关键要点
最先进的人工智能系统的进步需要大量的注释数据。当务之急是,除了算法之外,还应该有一种在不影响安全方面的情况下利用各种实体可用数据的方法。协作学习可以解决数据安全和数据共享问题,我们可以在不共享数据的情况下共享学习。机构增量学习可以促进协作机器学习,同时促进灵活性。使用协作学习构建具有当前工具和技术的最先进的AI系统是可能的,同时解决了数据安全和安全问题。简介:协作学习和数据共享的重要性
近年来,人工智能取得了显着发展。计算能力和图形处理单元的可用性使其能够接触到大众。
构建人工智能系统一直是一项具有挑战性的任务。虽然今天的组织正在寻求采用人工智能,但他们通常需要决定投资人工智能计划是否是正确的做法。
这通常会导致我们希望围绕组织的需求构建一个实验性人工智能系统的情况,我们可以在进行更高的投资之前对其进行评估。在这里,系统应该以“实现”为中心。我们可以通过利用可用的工具和框架来促进原型的快速开发来实现这一目标。
这是一个具有挑战性的情况,因为构建人工智能系统需要解决以下方面:
数据收集/注释 – 第一个重要的考虑因素是如何获取注释数据来训练机器学习模型。这也要求数据不会受到损害。匿名数据是一种替代方法,但需要相当大的努力。使用合适的算法训练模型。- 获得正确的算法来训练模型。与参与的合作伙伴共享模型。- 这解决了数据共享问题,因为我们共享的是模型而不是数据。使模型可供用户反馈。- 训练模型后,需要有一种机制,用户可以在其中评估和感受模型。简而言之,具有评估模型的能力。重用 – 使用以前训练的模型来促进快速学习。为了应对上述挑战,协作机器学习非常有用。在本文中,我将讨论如何在数据共享困难的情况下使用协作机器学习,但可以通过使用模型共享和机构增量学习来构建更好的模型。
这里的关键字是模型共享,而不是数据共享。本练习的重点是以最优化的方式使用资源,以足够快的速度构建深度学习模型系统。这也需要解决与数据相关的安全问题。
在协作学习方案中,可以通过以下方式进行协作:
多个参与者/机构根据可用的私有数据训练模型,并将训练的参数传递给中央服务器。我们称之为联邦学习。多个参与者/机构以增量方式训练模型,并将模型传递给下一个参与者。这可以迭代发生。这是制度性的渐进式学习。什么是机构增量学习?
这是一种在模型训练中进行协作的方式。跨称为节点的多个设备/服务器训练机器学习(或深度学习)模型。以下是主要功能:
节点具有其本地数据示例的版本。该算法可供节点使用,而不是数据进入一台服务器。解决数据隐私、安全问题。参与者可以发布他们的生态系统模型。适用于多个领域,包括国防、电信、物联网、制药和医疗。机构增量学习是解决数据共享问题的有前途的方法之一。使用这种方法,组织可以在安全的环境中训练模型,并且可以共享模型,而无需共享宝贵的数据。
机构增量学习不同于联邦学习。在联邦学习中,所有参与者同时进行训练。这很有挑战性,因为集中式服务器需要更新和维护模型。这导致了复杂的技术和通信要求。
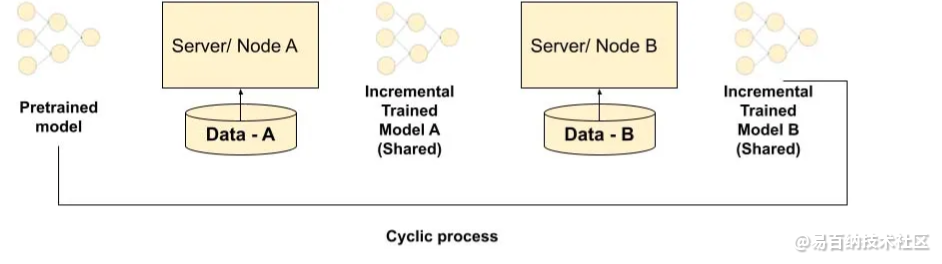
图1:机构增量学习流程
了解了增量机构学习之后,让我们在实践中实现这一目标。使用的数据是提供胸部 X 射线信息的公共数据集。我们通过使用称为分割的深度学习对象检测技术来解决这个问题。这里选择的架构是UNET,以resnet34为骨干。
可以使用预先训练的模型来诊断胸部X射线中的问题。对于本地训练,我们可以将此模型用作预训练模型。我们在这里所做的很重要,这被称为增量学习,使用了一个众所周知的迁移学习概念。这是使我们能够获得更好模型的功能。
在训练过程之后,我们得到一个可以与其他参与者共享的模型。如果模型足够好,可以使用,否则可以共享,我们建议进行更多训练。这里需要注意的重要一点是,数据不必离开其前提。我们共享一个模型,它是一堆参数,它将图像作为输入并使用称为“前向传播”的技术输出结果。它不能用于构建那些帮助它训练的图像。这是一种不可逆转的过程。模型只知道它需要知道什么才能提出预测。
在本地训练模型后,该模型以及指标将与参与实体共享。这样,使用特定模型的决定取决于组织,组织将使用它们,而不是任何人强迫。这真正实现了分散式机器学习,其中模型不仅经过训练,而且由用户自行决定使用。
渐进式机构学习有助于解决灾难性遗忘问题。这是因为当我们使用新数据训练模型时,训练不是从头开始的;它从最后一个协作者完成训练过程的点开始。然后,下一个协作者要求训练过程使用以前可用的模型作为下一次训练迭代的起点。以这种方式,神经网络从新信息中学习,但这不会破坏它。
上述过程可以以某种方式帮助解决灾难性的学习问题。当模型在使用之前在本地训练时,它将再次看到数据。即使以前的训练迭代使模式忘记了这一点,最后一遍也应确保将其保留在需要的地方。因此,在本地最后一次训练模型以防止灾难性遗忘是个好主意。
现在让我们了解此过程的各个部分。在这里,我通过一个使用机构增量学习的项目来演示这个过程。该项目的重点是以有助于以最有效的方式解决数据共享问题的方式使用这些概念。下一节提供了详细信息。
使用案例
建立一个可以在胸部X射线中检测肺炎的系统。这里使用的数据集是BIMCV COVID-19+,它提供了有关X射线状况以及该状况位置的信息。
接口支持这一点,因为有一些指标来支持数据是一回事,但有一种方法来查看结果并感受这一点是完全不同的主张。深度学习模型可以通过用户界面来“看到”或“感觉到”。我的项目通过提供一个可以进行预测的脚本来解决这个问题。
从技术上讲,我们在X射线中寻找一个矩形区域,称为边界框和相关条件。此处提供的数据集使用边界框进行批注。这些边界框表示显示肺条件的区域。表示此信息的另一种方法是通过语义分割。由于数据提供程序已使用边界框提供信息,因此模型还应通过边界框返回诊断。
物体检测
上述问题属于计算机视觉的保护伞,进一步将其细分为对象检测。物体检测因其在各个领域的适用性而成为抢手的领域。用于对象检测的一些流行方法/算法是R-CNN,更快的R – CNN,单次检测器和YOLO。
对象检测算法很复杂,因为它有两个任务要解决,什么和在哪里。模型通常有一个任务要解决,如分类或回归,但在对象检测方案中,它是预测条件是什么以及图像(此条件)存在的位置。通常,这是通过预测边界框以及与该边界框关联的条件来实现的。
还有另一种进行边界框检测的方法,即使用分割。边界框方法非常流行,但它们似乎不适用于较小的对象。在此实现中,采用了使用分割的对象检测。
使用的体系结构/库
U-Net – U-Net 是一个卷积神经网络,专为生物医学图像分割而开发。U 形架构包括特定的编码器-解码器方案:编码器减少了每一层的空间维度并增加了通道。解码器增加了空间维度,同时减少了通道。U-Net在生物医学图像分割中很受欢迎。
Resnet34 – Resnets 或残差神经网络是使用跳过连接进行残差学习的卷积神经网络。发现深度残差学习在学习深度架构网络方面效果更好。
FastAI是一个深度学习库,为从业者提供高级组件,这些组件可以快速轻松地在标准深度学习领域提供最先进的结果,并为研究人员提供可以混合和匹配以构建新方法的低级组件。它旨在做到这两件事,而不会在易用性、灵活性或性能方面做出实质性妥协。
scikit-image – 或 skimage 是用于图像处理和计算机视觉的算法集合。基于U-Net架构的模型以像素形式输出结果。Skimage有助于将像素信息转换为边界框。
方法:
该项目有两个主要模块:train.py 和 inference.py。
数据收集:我们在 BIMCV COVID-19+ 数据集上训练分割模型。数据以 DICOM 格式和逗号分隔文件提供,其中包含边界框和标签信息。
数据预处理:由于分割模型需要特定格式的数据,因此从 DICOM 格式中提取图像,并使用可用的边界框和条件信息创建遮罩图像。
模型训练 – 可以使用通用脚本,该脚本使用基于 PyTorch 构建的 fastai 框架。这提供了各种参数,如学习率、周期数、使用模型、训练目录、模式(完整或部分)。“使用模型”参数支持增量学习部分。调用训练脚本时,可以提供训练脚本在训练开始之前加载的模型引用(路径)。
因此,从以前的训练迭代中学习的内容将被保留(解决灾难性学习)。默认情况下,我们提供了一个可以使用的模型。该模型使用迁移学习方法,使用预先训练的 resnet34 模型。
通过这种方式,最好的人工智能实践得到了照顾。协作者训练模型并将模型提供给其他方后,他们可以使用该模型进行预测或进行训练。
进行预测 – 一旦训练好的模型可用,我们就可以在脚本“inference.py”的帮助下使用它进行预测。这是一个非常复杂的过程,其中会发生以下事情:
将模型加载到内存中。将图像加载到内存中进行预测/推理。模型处理图像,返回蒙版图像。调整蒙版图像的大小。从蒙版图像中获得与它们相关的概率和边界框。概率和相应的边界框绘制在图像上。将预测图像保存在输出目录中。在此步骤中,如果边界框信息可用,则还会生成带有注释数据的原始图像。这在最终用户拥有有关图像的信息并且他希望查看模型的性能的情况下很有用。
输出:
下面是在图像上生成的输出示例。除了边界框外,它还提供有关标签的信息。
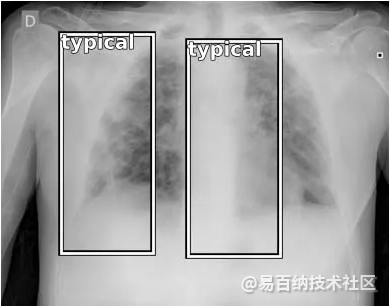
图 2:用于进行预测的图像
上图显示,与图像相关的病症与位置一起具有“典型”类型的肺炎。数据集通过四个标签提供信息:“正常”、“典型”、“非典型”和“不确定”。
确定标签和关联的边界框坐标需要一个中间步骤。经过训练的模型逐像素提供信息,然后使用 skimage 将其转换为边界框。下面是一个相同的示例。左图包含原始边界框,右图包含像素形式的信息。
原始信息:推理脚本生成一个图像,其中包含在地面实况信息可用时打印的标签和边界框。
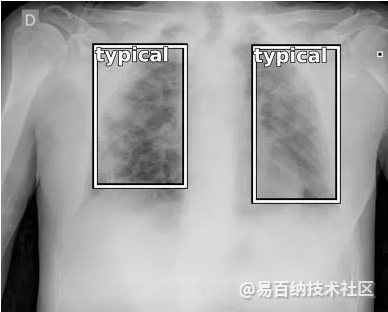
图3:带有原始信息的图像
适用性:
此应用程序通过仅共享模型来支持机构增量学习。协作者训练模型并与协作者共享模型后,就无需共享数据。通过模型,信息与协作者共享,从而可以获取与图像关联的标签信息。从而确保保持学习。这里的另一个优点是,任何人都不会强迫协作者使用特定的模型。他们可以灵活地
使用默认模型上可用的数据训练他们的模型。加载其他用户提供的模型并得出结论。加载其他用户提供的模型,并使用他们的数据集对其进行微调。这在医疗领域特别有用,因为分割模型很有用,这种方法有可能解决数据隐私问题。
增量学习的好处:
我们观察到机构增量学习的各种好处,例如:
解决数据安全问题。在不共享数据的情况下实现协作。无需访问所有数据即可获得更好的模型。易于实施。与另一种称为联邦学习的方法相比,此方法更容易遵循。灵活选择型号。在这里,参与者不限于使用特定的模型,他们可以选择自己喜欢的模型。与联邦学习系统相比,这种方法易于实现,因为存在复杂的技术要求,其中中央服务器扮演裁判的角色,并确保模型与参与节点的更新保持最新。这带来了复杂的工程挑战。
因此,我们可以看到,在使用机构增量学习解决数据共享问题的同时,构建一个对象检测系统并将其提供给用户并不难。可用的项目已准备就绪,并支持机构增量学习。在fastai库的帮助下,我们可以轻松开发支持其他架构(如resnet50)的模型。
机构增量学习可能非常有效,尤其是在医学领域。此框架可以支持以下用例:
脑肿瘤检测胸部 X 线检查中的肺炎检测腹部扫描免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:使用机构增量学习开发深度学习系统-机构数量大幅增加 https://www.yhzz.com.cn/a/9220.html