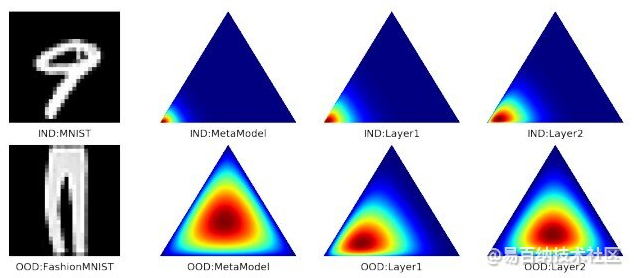
我们在OOD检测应用中提出的元模型方法的一个玩具示例显示了不同层中特征的多样性。MetaModel使用两个中间功能,而Layer1和Layer2仅使用一个单独的功能进行训练。
强大的机器学习模型正被用于帮助人们解决棘手的问题,例如识别医学图像中的疾病或检测自动驾驶汽车的道路障碍物。但是机器学习模型可能会犯错误,因此在高风险环境中,人类知道何时信任模型的预测至关重要。
不确定性量化是一种提高模型可靠性的工具;该模型在预测的同时产生一个分数,该分数表示预测正确的置信度。虽然不确定性量化可能是有用的,但现有的方法通常需要重新训练整个模型来赋予它这种能力。训练包括向一个模型展示数百万个例子,这样它就可以学习一项任务。然后再培训需要数百万个新的数据输入,这可能是昂贵和难以获得的,还需要使用大量的计算资源。
麻省理工学院和麻省理工学院- ibm沃森人工智能实验室的研究人员现在开发了一种技术,使模型能够执行更有效的不确定性量化,同时使用比其他方法少得多的计算资源,并且不需要额外的数据。他们的技术不需要用户重新训练或修改模型,对于许多应用来说足够灵活。
该技术包括创建一个更简单的辅助模型,以帮助原始机器学习模型估计不确定性。这个较小的模型旨在识别不同类型的不确定性,这可以帮助研究人员深入研究不准确预测的根本原因。
“不确定性量化对于机器学习模型的开发人员和用户都是至关重要的。开发人员可以利用不确定性度量来帮助开发更健壮的模型,而对于用户来说,当在现实世界中部署模型时,它可以增加另一层信任和可靠性。我们的工作为不确定性量化提供了一种更灵活、更实用的解决方案,”电气工程和计算机科学研究生沈茂豪表示
量化不确定性
在不确定性量化中,机器学习模型为每个输出生成一个数值分数,以反映其对预测准确性的信心。通过从零开始构建新模型或重新训练现有模型来整合不确定性量化通常需要大量数据和昂贵的计算,这通常是不切实际的。此外,现有的方法有时会产生意想不到的后果,降低模型预测的质量。
因此,麻省理工学院和麻省理工学院- ibm沃森人工智能实验室的研究人员将注意力集中在以下问题上:给定一个预训练的模型,他们如何使其能够执行有效的不确定性量化?
他们通过创建一个更小、更简单的模型(称为元模型)来解决这个问题,该模型附加到更大、预训练的模型上,并使用更大模型已经学习到的特征来帮助它进行不确定性量化评估。
元模型可以应用于任何预训练的模型。最好能够访问模型的内部,因为我们可以获得关于基本模型的更多信息,但如果只有最终输出,它也可以工作。它仍然可以预测信心得分,”Sattigeri说。
他们设计了元模型,使用一种包括两种不确定性的技术来产生不确定性量化输出:数据不确定性和模型不确定性。数据不确定性是由损坏的数据或不准确的标签引起的,只能通过修复数据集或收集新数据来降低数据不确定性。在模型不确定性中,模型不确定如何解释新观察到的数据,可能会做出不正确的预测,这很可能是因为它没有看到足够多的类似训练示例。在部署模型时,这个问题特别具有挑战性,但也是常见的问题。在现实环境中,他们经常会遇到与训练数据集不同的数据。
“当你在新的环境中使用模型时,你决策的可靠性是否发生了变化?”你需要某种方式来确定它是否在这种新体制下有效,或者你是否需要为这种特定的新环境收集训练数据,”Wornell说。
验证量化
一旦模型产生不确定性量化分数,用户仍然需要一些保证分数本身是准确的。研究人员通常通过创建一个较小的数据集来验证准确性,该数据集从原始训练数据中保留出来,然后在保留的数据上测试模型。然而,这种技术在测量不确定性量化方面效果不佳,因为该模型可以在仍然过于自信的同时实现良好的预测准确性,Shen说。
他们通过向验证集中的数据添加噪声来创建一种新的验证技术——这种嘈杂的数据更像是可能导致模型不确定性的分布外数据。研究人员使用这个嘈杂的数据集来评估不确定性量化。
他们通过观察元模型如何捕获各种下游任务的不同类型的不确定性来测试他们的方法,包括分布外检测和错误分类检测。他们的方法不仅优于每个下游任务中的所有基线,而且需要更少的培训时间来实现这些结果。
这种技术可以帮助研究人员使更多的机器学习模型能够有效地执行不确定性量化,最终帮助用户更好地决定何时信任预测。
展望未来,研究人员希望将他们的技术应用于更新的模型类别,例如具有与传统神经网络不同的结构的大型语言模型,Shen说。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:高效的技术提高了机器学习模型的可靠性-提高技术的有效策略 https://www.yhzz.com.cn/a/9216.html