
基于扩散的人工智能模型继续以卓越的图像、音频和视频生成能力震惊世界。然而,这种性能是有代价的,因为扩散模型的迭代采样过程(逐步去除噪声以生成高质量输出)通常需要比传统的单步生成模型(如生成对抗网络(GAN))多10–2000倍的计算量。与其他人工智能领域的情况一样,生成型人工智能研究人员越来越关注于不仅提高模型性能,而且降低计算负担。
在新的论文《一致性模型》(Consistency Models)中,OpenAI研究团队介绍了一系列计算效率高的生成模型,这些模型在不进行对抗性训练的情况下实现了单步样本生成的最先进性能。所提出的一致性模型可以训练为提取预训练的扩散模型或作为独立的生成模型。
该团队的目标是设计一系列新的生成模型,以促进高效的单步生成,同时保留扩散模型迭代优化过程的优势,如在必要时权衡计算复杂性和样本质量,或执行零镜头数据编辑任务的能力。

一致性模型建立在连续时间扩散模型中发现的概率流(PF)常微分方程(ODE)的基础上。给定一个平 滑地将数据转换为噪声的PF ODE,一致性模型学习在任何时间步将任何点映射到轨迹的起点,以进行生成建模。因此,输出被训练为与同一轨迹上的初始点“一致”——这是一个关键因素,决定了模型族的名称。
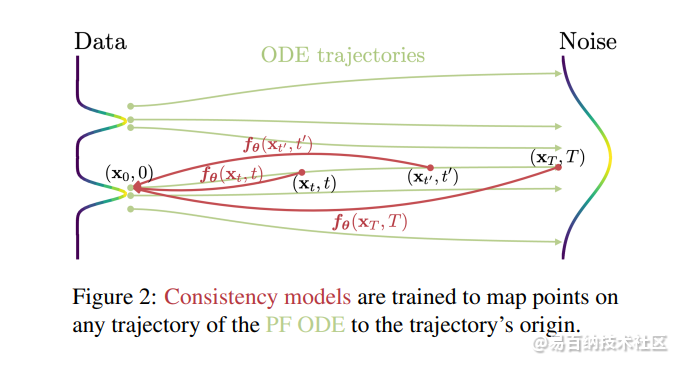
研究人员引入了两种一致性模型训练方法,它们支持蒸馏或分离模式。第一种训练方法使用数值ODE解算器和预训练的扩散模型来获得PF ODE轨迹上的相邻点对,并有效地将扩散模型提取为一致性模型。这显著提高了采样质量,同时实现了零拍图像编辑。第二种方法训练不依赖预训练的扩散模型,有效地将一致性模型建立为一个独立的生成模型族。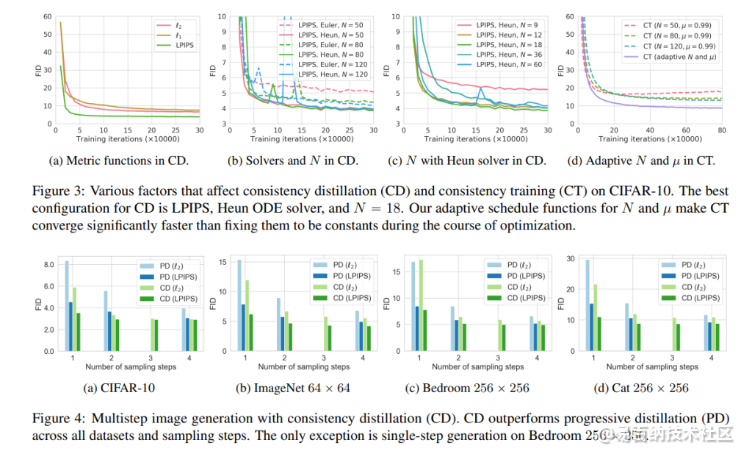

在他们的实证研究中,团队将一致性模型应用于真实图像数据集CIFAR-10、ImageNet 64×64、LSUN Bedroom 256×256和LSUN Cat 256×256。在实验中,通过一致性模型的蒸馏在CIFAR-10上获得了新的最先进FID分数3.55,在ImageNet 64×64上获得了6.20,用于一步生成,而独立一致性模型也优于现有的单步非对抗性生成模型。
本文演示了所提出的一致性模型如何在执行单步生成时实现更有效的采样。该团队相信,这样的模型也可以为不同人工智能研究领域的思想和方法的交叉传播提供令人兴奋的前景。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:OpenAI 的一致性模型支持快速一步生成扩散模型-数据一致性的计算方法 https://www.yhzz.com.cn/a/9026.html