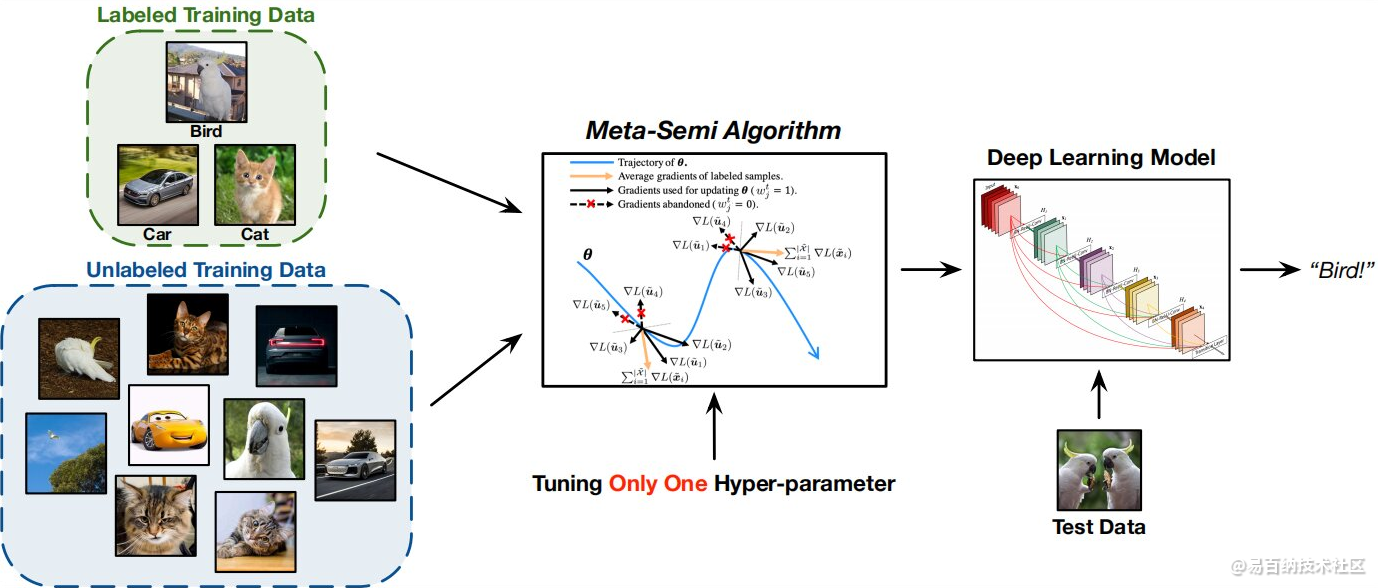
Meta-Semi使用伪标记样本训练深度网络,其梯度方向与标记样本相似。算法 1 显示了元半伪代码。Meta-Semi算法优于最先进的半监督学习算法
基于深度学习的半监督学习算法近年来显示出有希望的结果。然而,它们在真正的半监督学习场景中尚不实用,例如医学图像处理、高光谱图像分类、网络流量识别和文档识别。
在这些类型的方案中,标记的数据对于超参数搜索是稀缺的,因为它们引入了多个可调的超参数。一个研究小组提出了一种基于元学习的新型半监督学习算法,称为Meta-Semi,只需要调整一个额外的超参数。他们的Meta-Semi方法优于最先进的半监督学习算法。
深度学习是一种机器学习技术,计算机通过示例学习,在监督任务中取得了成功。然而,数据标记过程,即识别和标记原始数据,既耗时又昂贵。当有大量带注释的训练数据可用时,监督任务中的深度学习可以成功。然而,在许多实际应用中,所有可用训练数据中只有一小部分与标签相关联。
“深度学习最近在监督任务中的成功是由丰富的带注释的训练数据推动的,”清华大学自动化系副教授Gao Huang说。然而,耗时、昂贵的精确标签收集是研究人员必须克服的挑战。“Meta-semi作为一种最先进的半监督学习方法,可以用少量标记样本有效地训练深度模型,”Gao Huang说。
借助研究团队的Meta-Semi分类算法,他们有效地利用了标记的数据,同时只需要一个额外的超参数即可在各种条件下实现令人印象深刻的性能。在机器学习中,超参数是其值可用于指导学习过程的参数。
“大多数基于深度学习的半监督学习算法引入了多个可调超参数,这使得它们在真正的半监督学习场景中不太实用,因为标记的数据对于广泛的超参数搜索来说是稀缺的,”Gao Huang说。
该团队开发了他们的算法,其工作基于这样的假设,即网络可以使用正确的伪标记未注释样本进行有效训练。首先,他们在训练过程中根据网络预测在线为未标记的数据生成软伪标签。
然后,他们过滤掉伪标签不正确或不可靠的样本,并使用具有相对可靠的伪标签的剩余数据训练模型。他们的过程自然产生了一个元学习公式,其中正确的伪标记数据与标记数据具有相似的分布。在他们的过程中,如果网络是用伪标记数据训练的,那么标记数据的最终损失也应该最小化。
该团队的Meta-Semi算法在半监督学习的各种条件下实现了竞争性能。“从经验上讲,Meta-Semi在具有挑战性的半监督CIFAR-100和STL-10任务上明显优于最先进的半监督学习算法,并在CIFAR-10和SVHN上实现了有竞争力的性能,”Gao Huang说。
CIFAR-10、STL-10 和 SVHN 是经常用于训练机器学习算法的数据集或图像集合。“我们还从理论上表明,在温和的条件下,Meta-Semi收敛到标记数据上损失函数的平稳点,”黄说。与现有的深度半监督学习算法相比,Meta-Semi 调整超参数所需的工作量要少得多,但在四个竞争数据集上实现了最先进的性能。
展望未来的工作,研究团队的目标是开发一种有效,实用和强大的半监督学习算法。“该算法应该需要最少的数据注释,最少的超参数调整工作,以及最少的训练时间。为了实现这一目标,我们未来的工作可能集中在降低Meta-Semi的培训成本上,“Gao Huang说。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:“Meta-Semi”机器学习方法在深度学习任务中优于最先进的算法-rgm机器人 https://www.yhzz.com.cn/a/9018.html