谷歌上个月在巴黎发布的巴德聊天机器人(Bard)令人失望,但至少可以这么说,还不要把这家科技巨头排除在人工智能语言模型的竞赛之外。谷歌本周有所反弹,在去年11月启动的“1000种语言计划”项目上迈出了一大步,该计划旨在建立一个支持世界上1000种最常用语言的通用模型。
在新论文谷歌USM:扩展100种语言之外的自动语音识别中,谷歌团队“探索了语言扩展的前沿”,提出了一个可扩展的多语言ASR(自动语音识别)自我监督训练框架,扩展到数百种语言。他们所得到的通用语音模型(USM)在多语言ASR和语音到文本翻译任务中实现了最先进的性能。

该团队将他们的主要贡献总结如下:
我们证明了在 300 种语言上预训练的 USM 可以通过少量监督数据成功适应新语言的 ASR 和 AST(自动语音翻译)任务。我们通过在90k小时的监督数据上微调预训练模型,在73种语言上构建了通用ASR模型。通用ASR模型可以在TPU上高效地进行推理,并且可以在YouTube字幕ASR基准上可靠地转录长达数小时的音频。我们对预训练、嘈杂学生训练、文本注入和模型大小对多语言 ASR 的影响进行了系统研究。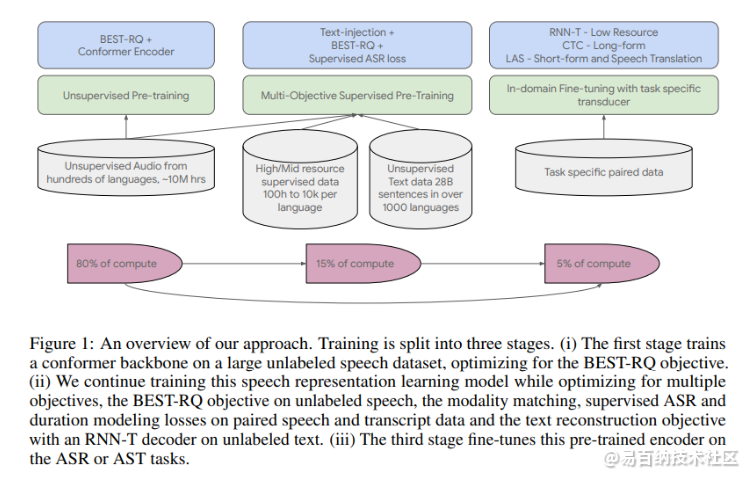
该团队使用谷歌在 2020 年推出的卷积增强变压器 Conformer 作为他们的骨干模型。USM 训练过程在管道中使用 12 万小时的语音和 28 亿句文本,涵盖 300+ 种语言,包括三个步骤:
1) 使用基于 BERT 的语音预训练和随机投影量化器 (BEST-RQ) 在 YT-NTL-U 大型未标记多语言语音数据集上预训练;
2) 应用多目标监督预训练来优化多个目标,使用 RNN-T 解码器对未标记的文本进行优化;
3) 预训练编码器针对下游 ASR 和 AST 任务进行了微调。
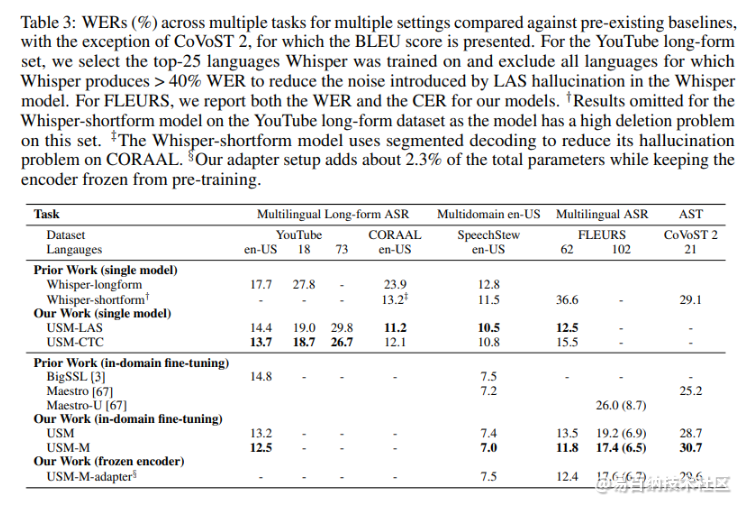
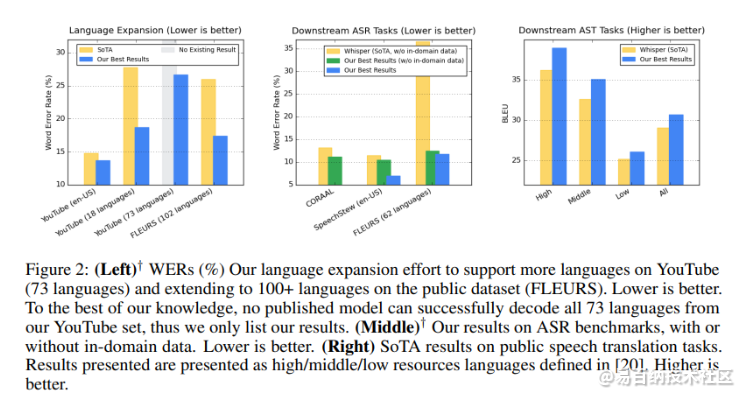
该团队在实证研究中评估了USM在ASR和AST任务上的表现。USM 模型在 102 种语言的 FLEURS 基准测试上实现了最先进的 ASR 结果,并在 2 种语言的 CoVoST-21 语音翻译语料库上实现了 AST 结果。研究人员指出,USM训练过程可以有效地适应新的语言和数据;并将USM的发展视为实现“谷歌组织世界信息并使其普遍可访问的使命”的重要一步。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:谷歌的通用语音模型将自动语音识别扩展到100多种语言-谷歌的语音助手是什么 https://www.yhzz.com.cn/a/9002.html