课题中心:招聘网站的职位招聘数据预处理
之前的文章,我们已经对职位薪资数据进行了爬取(9000条)数据,然后进行了数据的清洗,最终得到了4000条有效数据。
具体需求:
按不同的类别划分职位中的薪酬数据,画盒图/箱线图,检查孤立点/离群点;使用分位数图、分位数-分位数图方法处理数据;本次任务的结构图:
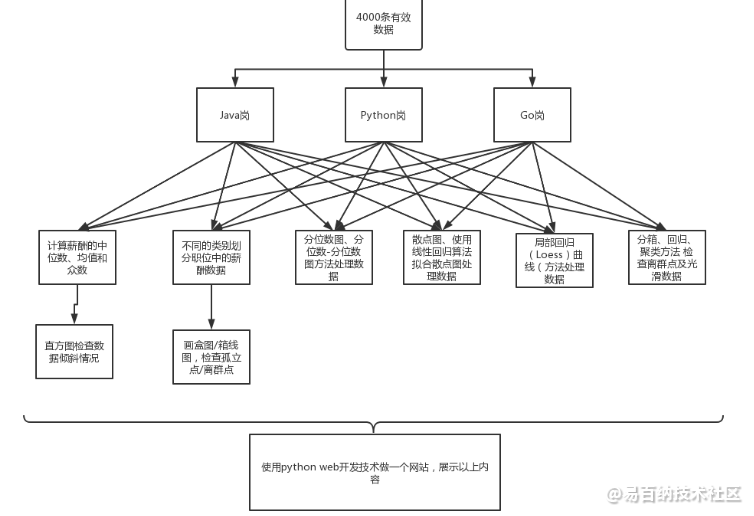
技术要点:
爬虫库(Beautifulsoup、requests-html、Scrapy)、数据预处理(python、kettle)、数据可视化(matplotlib、pyecharts、tebleau)、python-web框架(Flask) 二. 任务开始2.1 薪酬的中位数、均值和众数和数据倾斜模块详细设计
已Java为例,python和Go类似流程:
1.经过过去的爬虫和数据清理等步骤,我们得到了4000条左右的有效数据,我们先将其读取进来:
data = pd.read_csv(“A-06-最终有效数据.csv”,encoding=“gbk”)2.以Java为例:我们使用关键词“java”对数据进行筛选,循环筛选过程中将职位名,薪资需要的关键字放到列表里面,然后存入字典里,经过pandas的处理:
xingzhi={}zhiwei =[]xin1 =[]xin2 =[]for i in range(len(data)):if“java”in data.iloc[i][职位名]: a = re.findall(“\d+\.?\d*”, data.iloc[i][薪资])# print(data.iloc[i][职位名]) zhiwei.append(data.iloc[i][职位名]) xin1.append(int(a[0])) xin2.append(int(a[1]))xingzhi={“职位名”:zhiwei,最低薪资:xin1,最高薪资:xin2}df = pd.DataFrame(xingzhi)2.输出题目要求的均值,中位数和众数:
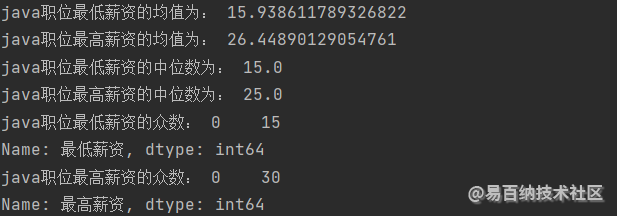
print(“java职位最低薪资的均值为:”,df[最低薪资].mean())print(“java职位最高薪资的均值为:”,df[最高薪资].mean())print(“java职位最低薪资的中位数为:”,df[最低薪资].median())print(“java职位最高薪资的中位数为:”,df[最高薪资].median())print(java职位最低薪资的众数:, df[最低薪资].mode())print(java职位最高薪资的众数:, df[最高薪资].mode())3.输出效果如下:
4.指定默认字体:解决plot不能显示中文问题,解决保存图像是负号’-‘显示为方块的问题。
mpl.rcParams[font.sans-serif]=[STZhongsong]mpl.rcParams[axes.unicode_minus]=False5.对x和y轴数据进行规范化,x轴使用数据的长度循环列表
import matplotlib.pyplot as plty1=xin1x1=range(0,df[最低薪资].count())x2=range(0, df[最高薪资].count())y2=xin2fig = plt.figure()plt.subplot(2,1,1)plt.bar(x1,y1, color=“green”)plt.ylabel(薪资,单位K)plt.title(java岗位的薪资情况(最低薪资-最高薪资))plt.subplot(2,1,2)plt.bar(x2,y2, color=“red”)plt.xlabel(公司个数)plt.ylabel(薪资,单位K)# plt.title(java岗位的薪资情况(最低薪资-最高薪资))plt.legend()plt.show()6.显示效果:
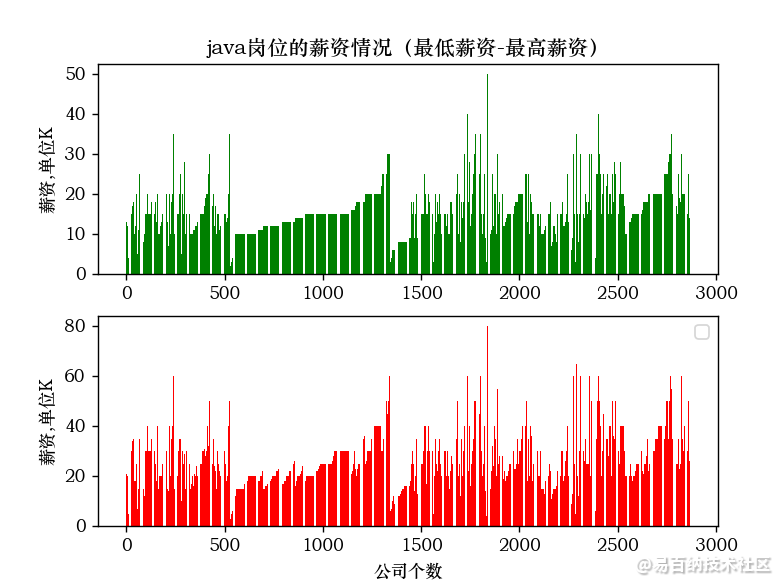
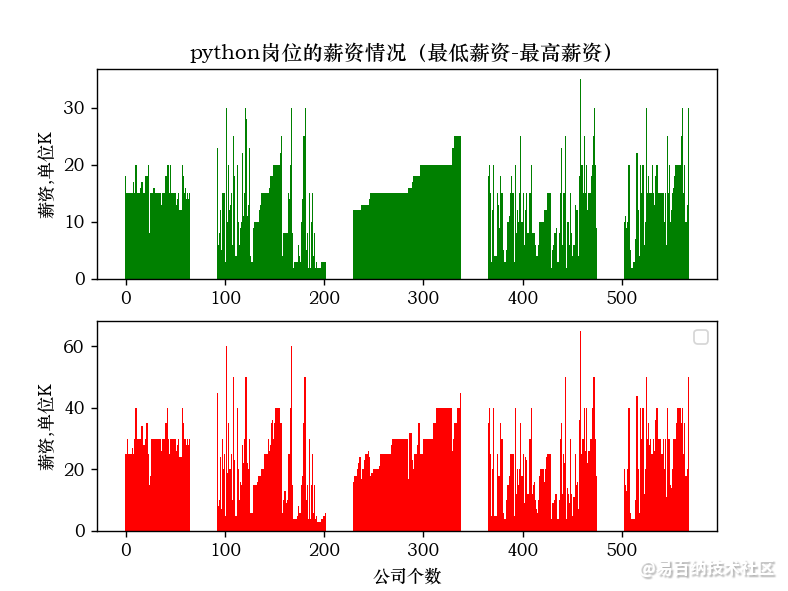
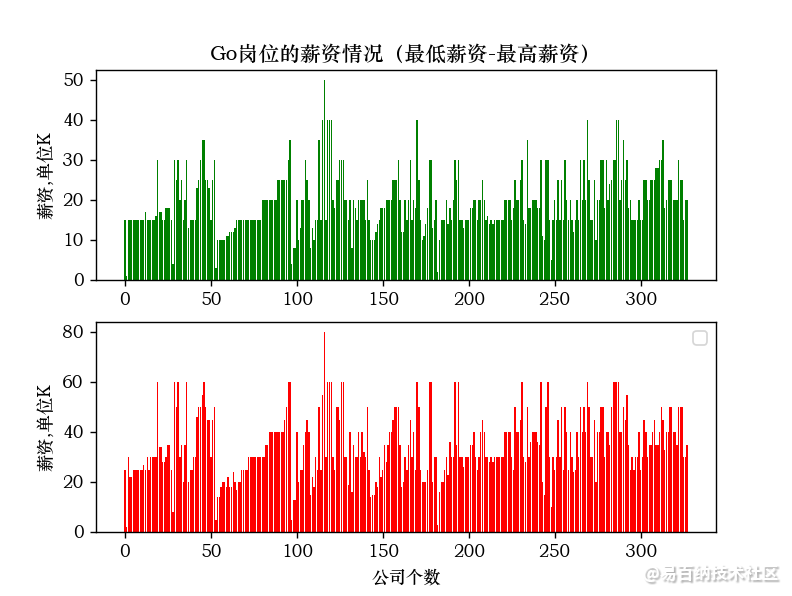
7.计算结果:
java职位:
java职位最低薪资的均值为: 15.938611789326822
java职位最高薪资的均值为: 26.44890129054761
java职位最低薪资的中位数为: 15.0
java职位最高薪资的中位数为: 25.0
java职位最低薪资的众数: 0 15
Name: 最低薪资, dtype: int64
java职位最高薪资的众数: 0 30
Name: 最高薪资, dtype: int64
python职位:
python职位最低薪资的均值为: 13.84330985915493
python职位最高薪资的均值为: 24.184859154929576
python职位最低薪资的中位数为: 15.0
python职位最高薪资的中位数为: 25.0
python职位最低薪资的众数: 0 15
Name: 最低薪资, dtype: int64
python职位最高薪资的众数: 0 30
Name: 最高薪资, dtype: int64
Go职位:
Go职位最低薪资的均值为: 19.64329268292683
Go职位最高薪资的均值为: 34.707317073170735
Go职位最低薪资的中位数为: 19.0
Go职位最高薪资的中位数为: 30.0
Go职位最低薪资的众数: 0 15
Name: 最低薪资, dtype: int64
Go职位最高薪资的众数: 0 30
Name: 最高薪资, dtype: int642.2 按不同的类别划分职位中的薪酬数据,画盒图/箱线图,检查孤立点/离群点
1.与上文一样,我们使用关键词“java”对数据进行筛选,循环筛选过程中将职位名,薪资需要的关键字放到列表里面,然后存入字典里,经过pandas的处理:
将上限和下限分别处理: xingzhi={}zhiwei =[]xin1 =[]xin2 =[]for i in range(len(data)):if“java”in data.iloc[i][职位名]: a = re.findall(“\d+\.?\d*”, data.iloc[i][薪资])# print(data.iloc[i][职位名]) zhiwei.append(data.iloc[i][职位名]) xin1.append(int(a[0])) xin2.append(int(a[1]))xingzhi={“职位名”:zhiwei,最低薪资:xin1,最高薪资:xin2}df = pd.DataFrame(xingzhi)labels =Java职位工资下限,Java职位工资上限A = xin1B = xin22.开始画图,将上面传入的进行处理
plt.grid(True)# 显示网格plt.boxplot([A, B], medianprops={color:red,linewidth:1.5}, meanline=True, showmeans=True, meanprops={color:blue,ls:—,linewidth:1.5}, flierprops={“marker”:“o”,“markerfacecolor”:“red”,“markersize”:10}, labels=labels)plt.yticks()plt.show()3.Python和GO语言的类似,如下:(GO语言代码省略不写)与这几个大致相同。
xingzhi={}zhiwei =[]xin1 =[]xin2 =[]for i in range(len(data)):if“python”in data.iloc[i][职位名]: a = re.findall(“\d+\.?\d*”, data.iloc[i][薪资]) zhiwei.append(data.iloc[i][职位名]) xin1.append(int(a[0])) xin2.append(int(a[1]))xingzhi={“职位名”:zhiwei,最低薪资:xin1,最高薪资:xin2}df = pd.DataFrame(xingzhi)labels =python职位工资下限,python职位工资上限A = xin1B = xin2plt.grid(True)# 显示网格plt.boxplot([A, B], medianprops={color:red,linewidth:1.5}, meanline=True,showmeans=True, meanprops={color:blue,ls:—,linewidth:1.5}, flierprops={“marker”:“o”,“markerfacecolor”:“red”,“markersize”:10}, labels=labels)plt.yticks()plt.show()4.运行结果如下:
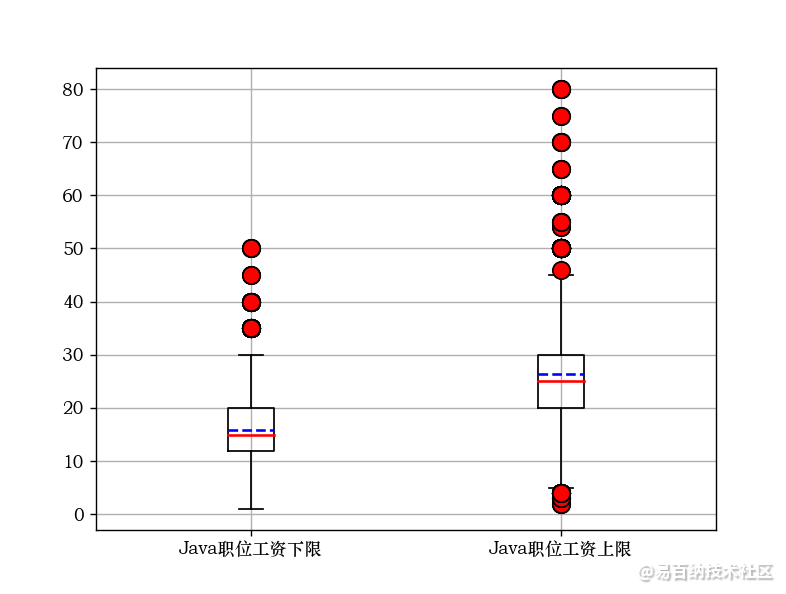
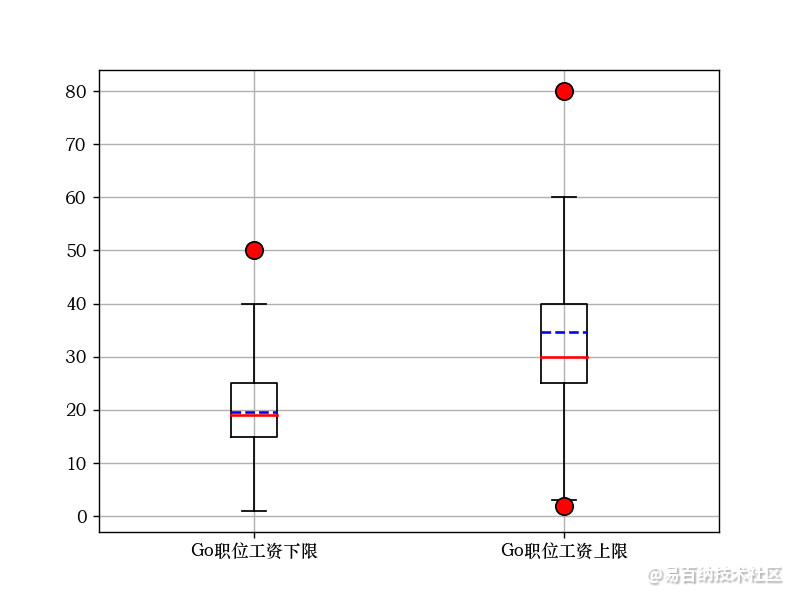
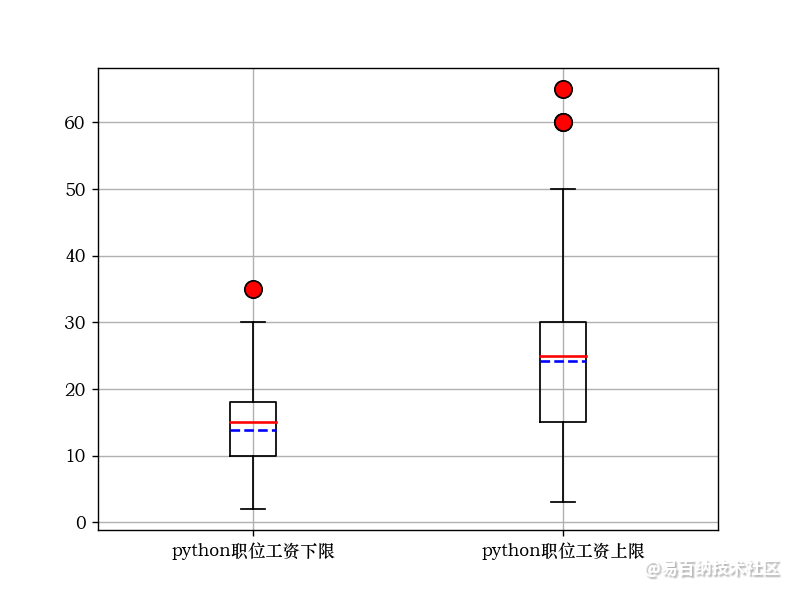
后面的任务会还会发布相关的文章。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【数据预处理&机器学习】对于薪资数据的倾斜情况以及盒图离群点的探究 https://www.yhzz.com.cn/a/8874.html