人工智能自然语言处理—PageRank算法和TextRank算法详解
一、PageRank算法
PageRank算法最初被用作互联网页面重要性的计算方法。它由佩奇和布林于1996年提出,并被用于谷歌搜索引擎的页面排名。事实上,PageRank可以在任何有向图上定义,然后应用于社会影响分析、文本摘要和其他问题。
PageRank算法的基本思想是在有向图上定义一个随机游动模型,即一阶马尔可夫链,以描述随机游动者沿着有向图随机访问每个节点的行为。在某些条件下,在极限情况下访问每个节点的概率收敛到一个平稳分布,然后每个节点的平稳概率值就是它的PageRank值,它表示节点的重要性。PageRank是递归定义的,PageRank的计算可以通过迭代算法进行。算法公式如下:
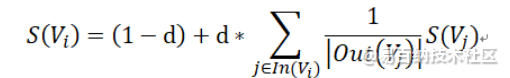
原理如下图
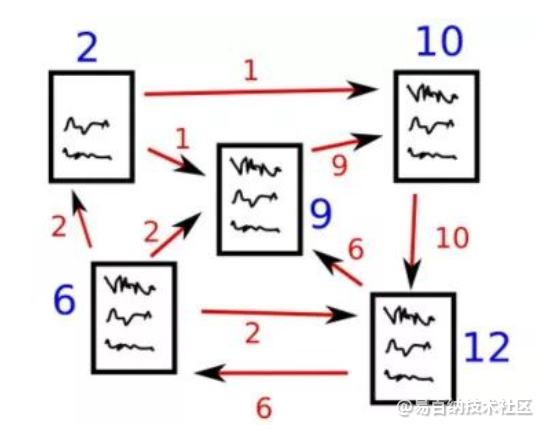
PageRank算法的核心思想如下:
(1)链接数量:如果一个网页被越多的其他网页链接,说明这个网页越重要,即该网页的PR值(PageRank值)会相对较高;
(2)链接质量:如果一个网页被一个越高权值的网页链接,也能表明这个网页越重要,即一个PR值很高的网页链接到一个其他网页,那么被链接到的网页的PR值会相应地因此而提高。
代码实例:
import numpy as npp =0.85#引入浏览当前网页的概率为p,假设p=0.8a = np.array([[1,0,0,0],[0,0,0,1],[0,0,0,1],[0,1,0,0]],dtype = float)#dtype指定为floatlength=a.shape[1]#网页数量#构造转移矩阵b = np.transpose(a)#b为a的转置矩阵m = np.zeros((a.shape),dtype = float)for i in range(a.shape[0]):for j in range(a.shape[1]):#如果一个节点没有任何出链,Dead Endsif b[j].sum()==0: b[j]=b[j]+np.array([1/length]*length) m[i][j]= a[i][j]/(b[j].sum())#完成初始化分配#pr值得初始化v = np.zeros((m.shape[0],1),dtype = float)#构造一个存放pr值得矩阵for i in range(m.shape[0]): v[i]= float(1)/m.shape[0]count=0ee=np.array([[1/length]*length]).reshape(length,-1)# 循环100次计算pageRank值for i in range(100):# 解决spider traps问题,spider traps会导致网站权重向一个节点偏移,将转移矩阵加上打开其他网页的概率1-p v = p*np.dot(m,v)+(1–p)*ee count+=1print(“第{}次迭代”.format(count))#pageRank值print(v)二、TextRank算法
TextRank算法是一种基于图的文本排序算法。它将文本分成几个组成单元(句子),构建节点连接图,使用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后提取排名较高的句子,形成文本摘要。本文介绍了提取文本摘要的算法TextRank,并使用Python实现了TextRank算法的应用,从多个单域文本数据中提取句子以形成摘要。
TextRank算法的代码实例:
它是从Google的PageRank算法改进而来的,用于对网页的重要性进行排序。它使用文档中单词之间的共现信息(语义)来提取关键字。它可以从给定文本中提取关键词和关键短语,并使用提取自动摘要方法提取文本的关键句子。
# coding=utf-8from textrank4zh importTextRank4Keyword,TextRank4Sentenceimport jieba.analysefrom snownlp importSnowNLPimport pandas as pdimport numpy as np#关键词抽取def keywords_extraction(text): tr4w =TextRank4Keyword(allow_speech_tags=[n,nr,nrfg,ns,nt,nz])# allow_speech_tags –词性列表,用于过滤某些词性的词 tr4w.analyze(text=text, window=2, lower=True, vertex_source=all_filters, edge_source=no_stop_words, pagerank_config={alpha:0.85,}) keywords = tr4w.get_keywords(num=6, word_min_len=2)# num — 返回关键词数量# word_min_len — 词的最小长度,默认值为1return keywords#关键短语抽取def keyphrases_extraction(text): tr4w =TextRank4Keyword() tr4w.analyze(text=text, window=2, lower=True, vertex_source=all_filters, edge_source=no_stop_words, pagerank_config={alpha:0.85,}) keyphrases = tr4w.get_keyphrases(keywords_num=6, min_occur_num=1)# keywords_num — 抽取的关键词数量# min_occur_num — 关键短语在文中的最少出现次数return keyphrases#关键句抽取def keysentences_extraction(text): tr4s =TextRank4Sentence() tr4s.analyze(text, lower=True, source=all_filters) keysentences = tr4s.get_key_sentences(num=3, sentence_min_len=6)return keysentencesdef keywords_textrank(text): keywords = jieba.analyse.textrank(text, topK=6)return keywordsif __name__ ==“__main__”: text =“来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式,” \“我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台、” \“副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”” \“据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站,” \“获得国际永久编号第120730号。2018年9月25日,经国家天文台申报,” \“国际天文合会小天体联合会小天体命名委员会批准,国际天文合会《小行星通报》通知国际社会,” \“正式将该小行星命名为“周又元星”。”#关键词抽取 keywords=keywords_extraction(text)print(keywords)#关键短语抽取 keyphrases=keyphrases_extraction(text)print(keyphrases)#关键句抽取 keysentences=keysentences_extraction(text)print(keysentences)部分代码解释如下:
text — 文本内容,字符串
window — 窗口大小,int,用来构造单词之间的边。默认值为2
lower — 是否将英文文本转换为小写,默认值为False
vertex_source — 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来构造pagerank对应的图中的节点
默认值为all_filters,可选值为`’no_filter’, ‘no_stop_words’, ‘all_filters’
edge_source — 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来构造pagerank对应的图中的节点之间的边
默认值为no_stop_words,可选值为no_filter, no_stop_words, all_filters。边的构造要结合window参数
pagerank_config — pagerank算法参数配置,阻尼系数为0.85
lower — 是否将英文文本转换为小写,默认值为False
source — 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来生成句子之间的相似度。
默认值为all_filters,可选值为`’no_filter’, ‘no_stop_words’, ‘all_filters’
sim_func — 指定计算句子相似度的函数
获取最重要的num个长度大于等于sentence_min_len的句子用来生成摘要
三、PageRank算法与TextRank算法的区别
PageRank算法根据网页之间的链接关系构造网络,TextRank算法根据词之间的共现关系构造网络;
PageRank算法:

TextRank算法:
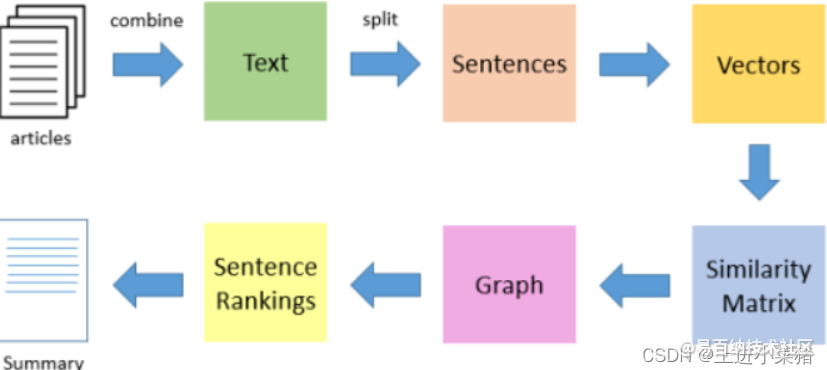 PageRank算法构造的网络中的边是有向无权边,TextRank算法构造的网络中的边是无向有权边。
PageRank算法构造的网络中的边是有向无权边,TextRank算法构造的网络中的边是无向有权边。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:人工智能自然语言处理—PageRank算法和TextRank算法详解-人工智能自然语言理解的有哪些 https://www.yhzz.com.cn/a/8866.html