深度神经网络
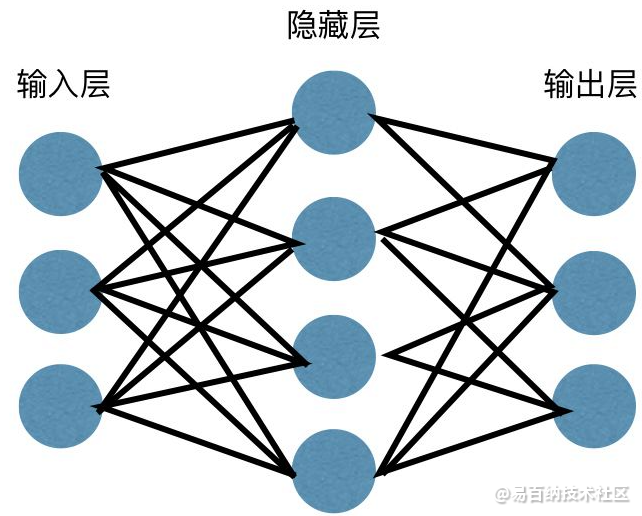
神经网络广泛应用于监督学习和强化学习。这些网络基于一组彼此连接的层。
在深度学习中,大多数非线性隐藏层的数量可能很大;大约1000层。
DL模型比普通ML网络产生更好的结果。
我们主要使用梯度下降法来优化网络并最小化损失函数。
Imagenet是数百万数字图像的存储库,可用于将数据集分类为猫和狗等类别。除了静态图像、时间序列和文本分析之外,DL网络越来越多地用于动态图像。
训练数据集是深度学习模型的重要组成部分。此外,反向传播是训练DL模型的主要算法。
DL处理训练具有复杂输入和输出变换的大型神经网络。深度网络
我们必须决定是否构建分类器,或者是否尝试在数据中找到模式,以及是否应该使用无监督学习。为了从一组未标记的数据中提取模式,使用了受限的玻尔兹曼机器或自动编码器。
选择深度网络时,请考虑以下几点:对于文本处理、情感分析、解析和名称实体识别,我们使用循环网络或递归神经张量网络或RNTN;递归网络可以用于在字符级运行的任何语言模型。对于图像识别,可以使用深度信念网络DBN或卷积网络。对于对象识别,可以使用RNTN或卷积网络。对于语音识别,可以使用递归网络。通常,具有整数线性单元或RELU和多层感知器的深度信念网络是分类的好选择。 对于时间序列分析,始终建议使用递归网络。
神经网络已经存在了50多年,但直到现在,它们已经上升到了一个突出的位置。原因是他们很难训练;当我们试图用一种叫做反向传播的方法训练它们时,我们遇到了一个叫做消失或爆炸梯度的问题。当这种情况发生时,训练需要很长时间,而准确度则需要退居次要地位。当训练数据集时,我们连续计算成本函数,即一组标记的训练数据的预测输出和实际输出之间的差异。然后调整权重和偏差值,直到获得最小值。训练过程使用梯度,这是成本将随着权重或偏差值的变化而变化的速率。前向传播算法和滑动平均模型
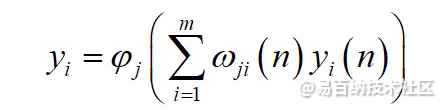 我们使用我们的几个权重系数矩阵W和偏置向量b对输入值向量x进行一系列线性运算和激活运算。从输入层开始,我们逐层向后计算,直到运算到达输出层,输出结果是一个值。
我们使用我们的几个权重系数矩阵W和偏置向量b对输入值向量x进行一系列线性运算和激活运算。从输入层开始,我们逐层向后计算,直到运算到达输出层,输出结果是一个值。
①滑动平均模型的作用是提高测试值上的健壮性,一个参数变化很大,那势必会影响到测试准确度问题,从他的公式看shadow_var = decay shadow_var + (1 – decay) var_new,decay控制着该shadow变量的更新速度,decay越大,那么很明显其值就会越倾向接近于旧值,而decay越小,那么var_new产生的叠加作用就会越强,其结果就会越倾向于远离旧值,那这样波动就很大,通常认为稳定性就不够好当然就不够健壮了
②通俗的理解就是“让参数有滑动效果,目的是让参数不是一个常数,而是一个可以变的参数,提高模型的稳定性”代码实例:
激活函数的一般性质
(1) 通常,我们使用梯度下降算法来更新神经网络中的参数,因此激活函数必须是可微的。如果函数是单调递增的,则导数函数必须大于零(便于计算),因此要求激活函数是单调的。
(2) 限制输出值的范围输入数据通过神经元上的激活函数控制输出值。输出值为非线性值。激活函数获得的值决定了神经元是否需要根据极限值激活。换句话说,我们可以通过激活函数来确定我们是否对神经元的输出感兴趣。
(3) 非线性是因为线性模型的表达能力不够(从数据输入到与权重值相加和偏移,这是一个在线性函数中对权重和输入数据进行加权和的过程,例如(
)因此,激活函数的出现也为神经网络模型增加了非线性因素。激活函数具有上述特征,其核心意义在于,没有激活函数的神经网络只是一个线性回归模型,无法表达复杂的数据分布。神经网络中加入了激活函数,这相当于引入了非线性因素,从而解决了线性模型无法解决的问题。
不同激活函数的选择对神经网络的训练和预测有不同程度的影响。接下来,我们将分析神经网络中常用的激活函数及其优缺点。
激活函数与损失函数如下: def activity_func(a):# simgoid函数 yp =1/(1+ np.exp(-1* a))return ypdef dA_dZ(Z):# 返回simgoid函数的dA/dZreturn np.multiply((1/(1+ np.exp(-1* Z))),(1–(1/(1+ np.exp(-1* Z)))))def loss_func(YP, Y, error): size = YP.shape[1]# 得到YP的数量 Y_arr = Y.tolist() YP_arr = YP.tolist()# 避免后续求dA时出现除0现象 temp = np.where(YP ==1)for index, item in enumerate(temp[0]): YP[item, temp[1][index]]=0.999999999999 dA =-(np.true_divide(Y, YP)+ np.true_divide((Y –1),(1– YP))) loss_part1 = np.dot(Y, np.log(YP).T) loss_part2 = np.dot(1– Y, np.log(1– YP).T) loss =-(loss_part1 + loss_part2) count =0for index, item in enumerate(Y_arr[0]):if abs(item – YP_arr[0][index])< error: count +=1 accuracy = count / sizereturn dA, float(loss)/ size ifnot np.isnan(float(loss)/ size)else0, accuracydef relu(z):return np.multiply(z, z >0)def rele_dA_dZ(z):return z >0免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:AI-深度神经网络(前向传播算法和滑动平均模型)以及激活函数实例-前馈神经网络和反馈神经网络的区别在于 https://www.yhzz.com.cn/a/8862.html