
ECRAM 阵列
深度学习和人工智能带来的变革伴随着巨大的成本。例如,OpenAI的ChatGPT算法每天至少要花费10万美元才能运行。这可以通过加速器或设计用于有效执行深度学习的特定操作的计算机硬件来减少。然而,只有当这种设备能够在材料层面与主流硅基计算硬件集成时,它才是可行的。
这阻碍了一种极具前景的电化学随机存取存储器(ECRAM)深度学习加速器阵列的实现,直到伊利诺伊大学厄巴纳-香槟分校的一个研究团队首次在硅晶体管上实现了ECRAM的材料级集成。由研究生Jinsong Cui和材料科学与工程系教授Qing Cao领导的研究人员最近在Nature Electronics报告了一种ECRAM器件,该器件由可以在制造过程中直接沉积在硅上的材料设计和制造,实现了第一个实用的基于ECRAM的深度学习加速器。
“其他ECRAM设备已经具有深度学习加速器所需的许多难以获得的特性,但我们是第一个实现所有这些特性并与硅集成而没有兼容性问题的设备,”Cao说。“这是该技术广泛使用的最后一个主要障碍。
ECRAM是一种存储单元,或存储数据并将其用于在同一物理位置进行计算的设备。这种非标准计算架构消除了在内存和处理器之间穿梭数据的能源成本,从而可以非常高效地执行数据密集型操作。
ECRAM通过在栅极和通道之间移动离子来编码信息。施加到栅极端子的电脉冲将离子注入通道或从通道中吸取离子,由此产生的通道电导率变化存储信息。然后通过测量流过通道的电流来读取它。栅极和通道之间的电解质可防止不需要的离子流,使ECRAM能够将数据保留为非易失性存储器。
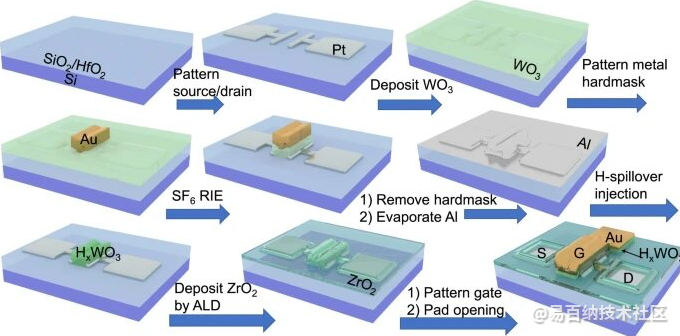
ECRAM制造流程
研究小组选择了与硅微细加工技术兼容的材料:氧化钨用于栅极和通道,氧化锆用于电解质,质子作为移动离子。这使得设备可以集成到标准微电子设备上并由其控制。其他ECRAM器件从神经过程甚至可充电电池技术中汲取灵感,并使用有机物质或锂离子,这两者都与硅微加工不兼容。
此外,Cao组设备还具有许多其他功能,使其成为深度学习加速器的理想选择。“虽然硅集成至关重要,但理想的存储单元必须实现一系列特性,”Cao说。“我们选择的材料还具有许多其他理想的功能。
由于栅极和通道端子使用相同的材料,因此将离子注入通道和从通道中吸取离子是对称操作,简化了控制方案并显着提高了可靠性。该通道一次可靠地保持离子数小时,这足以训练大多数深度神经网络。由于离子是质子,离子最小,因此器件切换得非常快。研究人员发现,他们的设备持续了超过100亿个读写周期,并且比标准内存技术效率高得多。最后,由于这些材料与微细加工技术兼容,这些设备可以缩小到微米和纳米尺度,从而实现高密度和计算能力。
研究人员通过在硅微芯片上制造ECRAM阵列来展示他们的设备,以执行矩阵向量乘法,这是一种对深度学习至关重要的数学 运算。矩阵条目(神经网络权重)存储在ECRAM中,阵列通过使用存储的权重来改变产生的电流,对矢量输入执行乘法,表示为施加的电压。此操作以及权重更新以高度并行性执行。
“我们的ECRAM设备对于对芯片尺寸和能耗敏感的AI边缘计算应用将最有用,”Cao说。“与硅基加速器相比,这种类型的设备具有最显着的优势。
研究人员正在为这种新设备申请专利,他们正在与半导体行业合作伙伴合作,将这项新技术推向市场。根据Cao的说法,这项技术的主要应用是自动驾驶汽车,它必须快速了解周围环境,并在有限的计算资源下做出决策。Cao正在与伊利诺伊州电气和计算机工程学院合作,将他们的ECRAM与代工厂制造的硅芯片以及伊利诺伊州计算机科学学院合作,利用ECRAM的独特功能开发软件和算法。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:研究人员为实用的AI加速器实现了第一个硅集成ECRAM-研究人员安排了一次实验怎么写 https://www.yhzz.com.cn/a/8826.html