深度学习与图神经网络学习分享:CNN 经典网络之-ResNet
resnet 又叫深度残差网络
图像识别准确率很高,主要作者是国人哦
深度网络的退化问题
深度网络难以训练,梯度消失,梯度爆炸,老生常谈,不多说
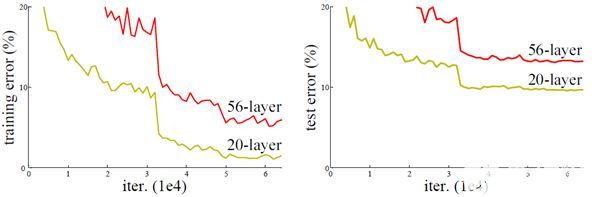
resnet 解决了这个问题,并且将网络深度扩展到了最多152层。怎么解决的呢?
残差学习
结构如图
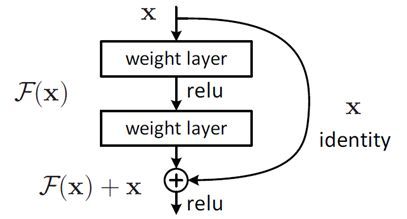
在普通的卷积过程中加入了一个x的恒等映射(identity mapping)
专家把这称作 skip connections或者 shortcut connections
残差结构的理解
为什么要这样呢?下面我从多个角度阐述这个问题。
生活角度
每学习一个模型,我都希望能用日常的生活去解释为什么模型要这样,一是加深对模型的理解,二是给自己搭建模型寻找灵感,三是给优化模型寻找灵感。
resnet 无疑是解决很难识别的问题的,那我举一个日常生活中人类也难以识别的问题,看看这个模型跟人类的识别方法是否一致。
比如人类识别杯子里的水烫不烫
一杯水,我摸了一下,烫,好,我的神经开始运转,最后形成理论杯子里的水烫,这显然不对
又一杯水,我一摸,不烫,好嘛,这咋办,认知混乱了,也就是无法得到有效的参数,
那人类是怎么办呢?
我们不止是摸一摸,而且在摸过之后还要把杯子拿起来仔细看看,有什么细节可以帮助我们更好的识别,这就是在神经经过运转后,又把x整体输入,
当然即使我们拿起杯子看半天,也可能看不出任何规律来帮助我们识别,那人类的作法是什么呢?我记住吧,这种情况要小心,这就是梯度消失了,学习不到任何规律,记住就是恒等映射,
这个过程和resnet是一致的。
网络结构角度
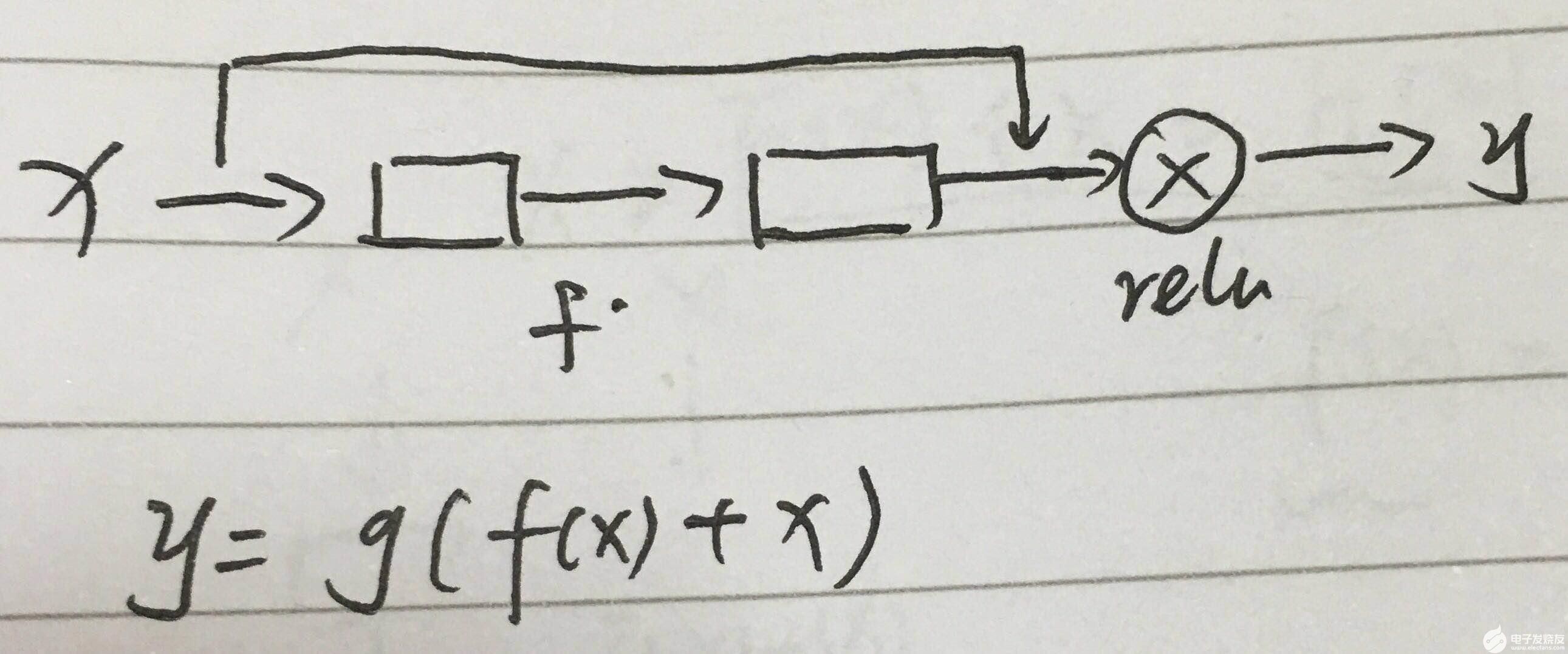
当梯度消失时,f(x)=0,y=g(x)=relu(x)=x,怎么理解呢?
1. 当梯度消失时,模型就是记住,长这样的就是该类别,是一个大型的过滤器
2. 在网络上堆叠这样的结构,就算梯度消失,我什么也学不到,我至少把原来的样子恒等映射了过去,相当于在浅层网络上堆叠了“复制层”,这样至少不会比浅层网络差。
3. 万一我不小心学到了什么,那就赚大了,由于我经常恒等映射,所以我学习到东西的概率很大。
数学角度
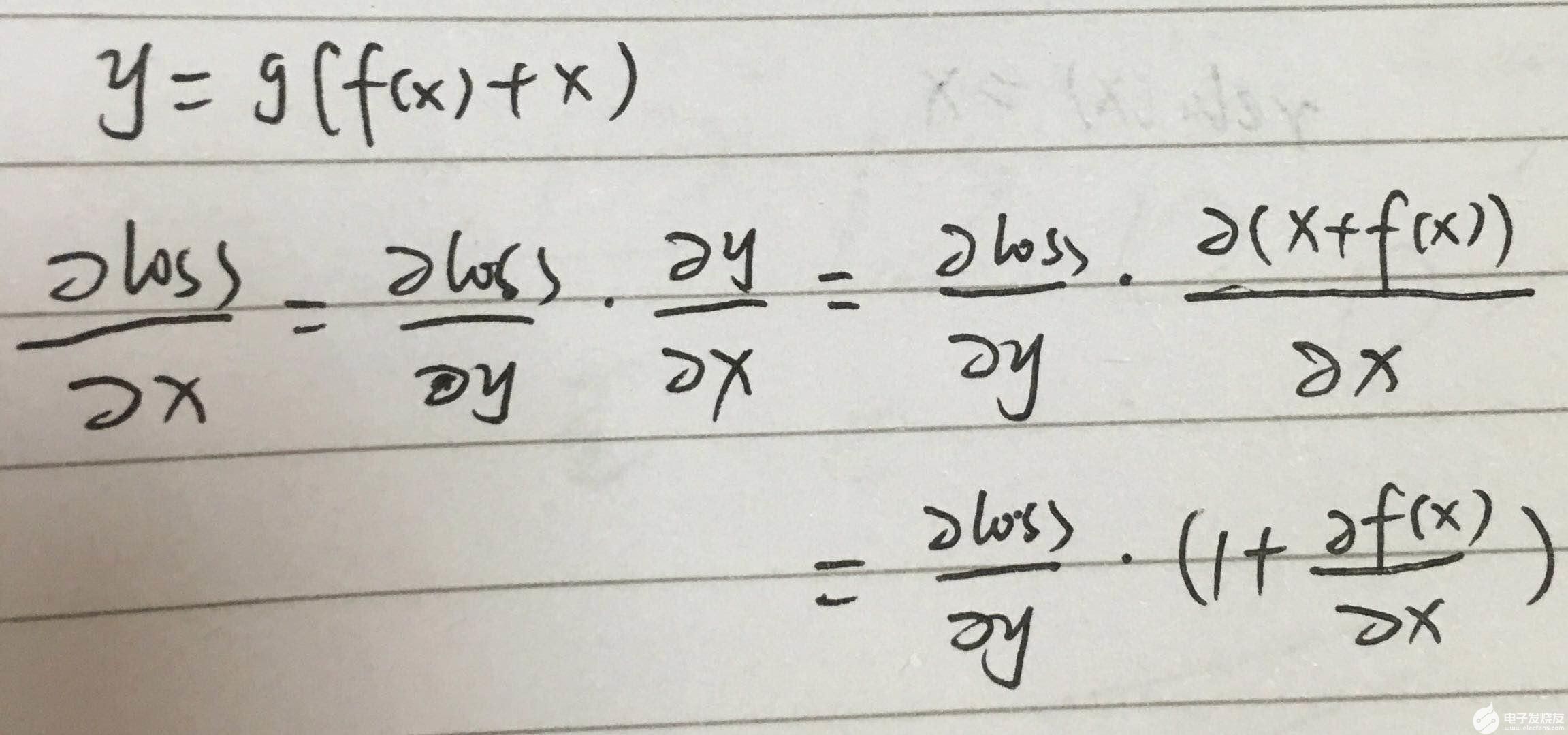
可以看到 有1 的存在,导数基本不可能为0
那为什么叫残差学习呢
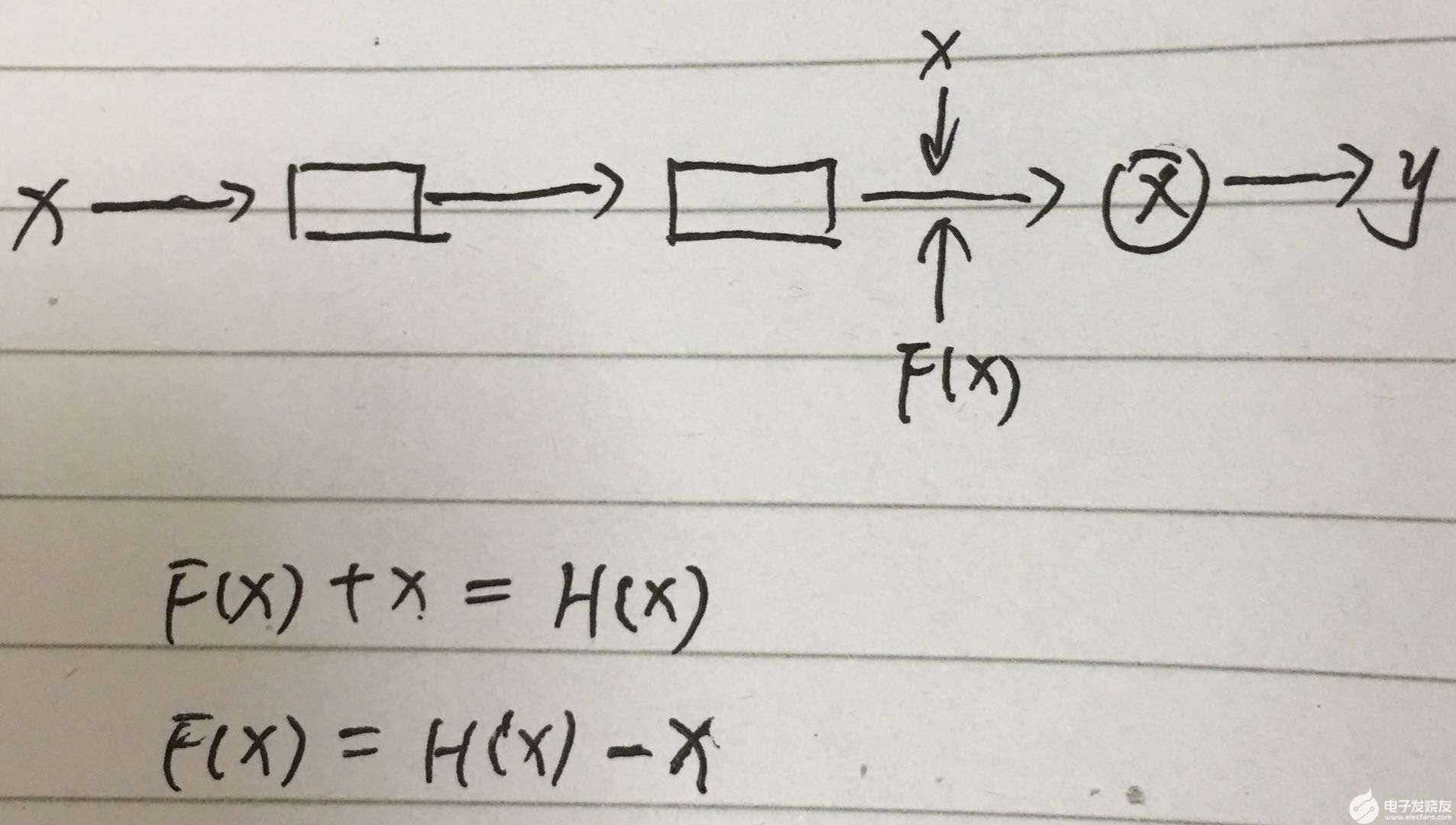
可以看到 F(x) 通过训练参数 得到了 H(x)-x,也就是残差,所以叫残差学习,这比学习H(x)要简单的多。
等效映射 identity mapping
上面提到残差学习中需要进行 F(x)+x,在resnet中,卷积都是 same padding 的,当通道数相同时,直接相加即可,
但是通道数不一样时需要寻求一种方法使得y=f(x)+wx
实现w有两种方式
1. 直接补0
2. 通过使用多个 1×1 的卷积来增加通道数。
网络结构
block
block为一个残差单元,resnet 网络由多个block 构成,resnet 提出了两种残差单元
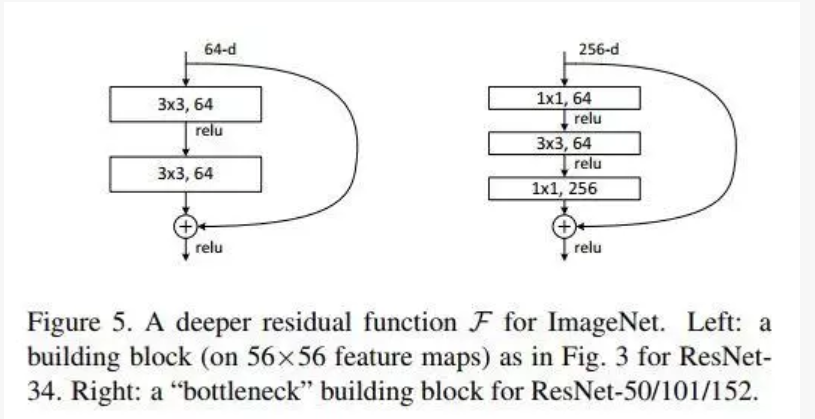
左边针对的是ResNet34浅层网络,右边针对的是ResNet50/101/152深层网络,右边这个又被叫做 bottleneck
bottleneck 很好地减少了参数数量,第一个1×1的卷积把256维channel降到64维,第三个又升到256维,总共用参数:1x1x256x64+3x3x64x64+1x1x64x256=69632,
如果不使用 bottleneck,参数将是 3x3x256x256x2=1179648,差了16.94倍
这里的输出通道数是根据输入通道数确定的,因为要与x相加。
整体结构
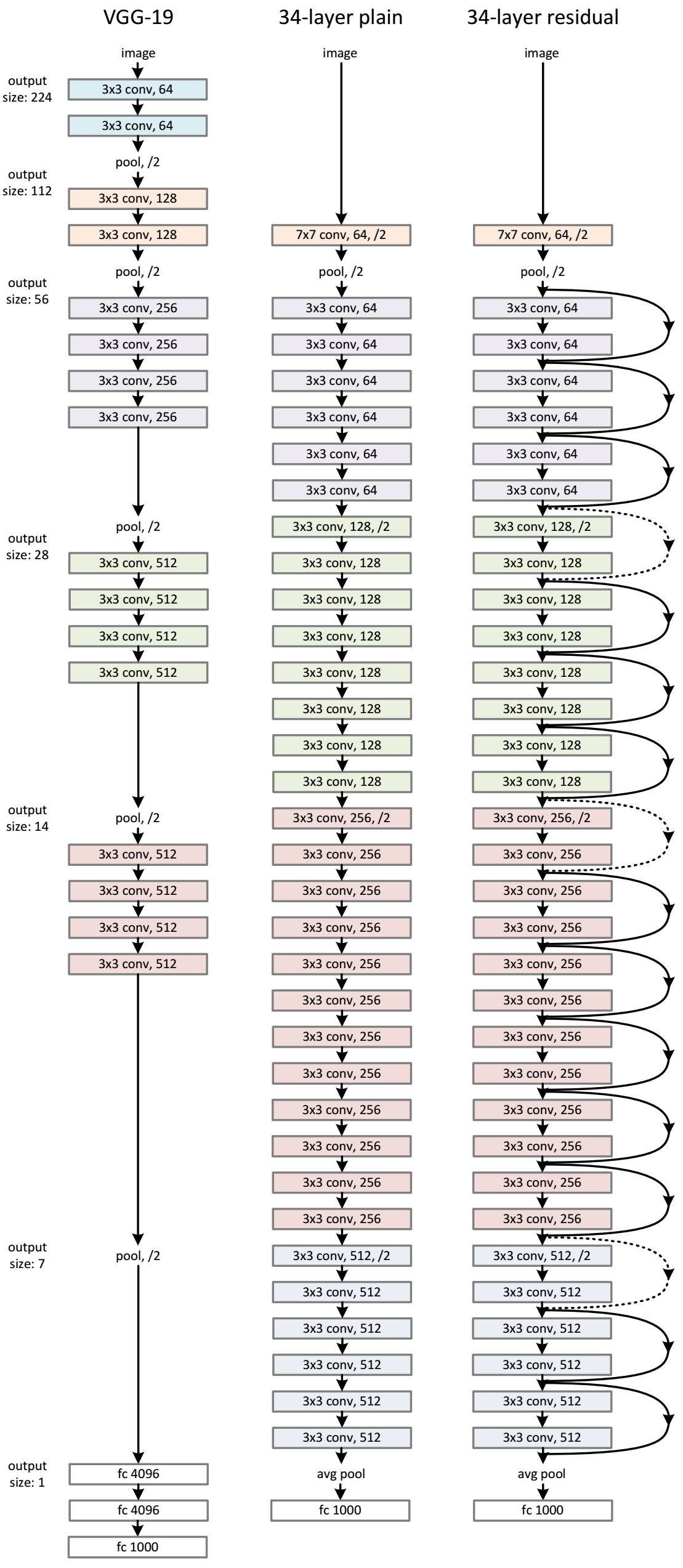
1. 与vgg相比,其参数少得多,因为vgg有3个全连接层,这需要大量的参数,而resnet用 avg pool 代替全连接,节省大量参数。
2. 参数少,残差学习,所以训练效率高
结构参数
Resnet50和Resnet101是其中最常用的网络结构。
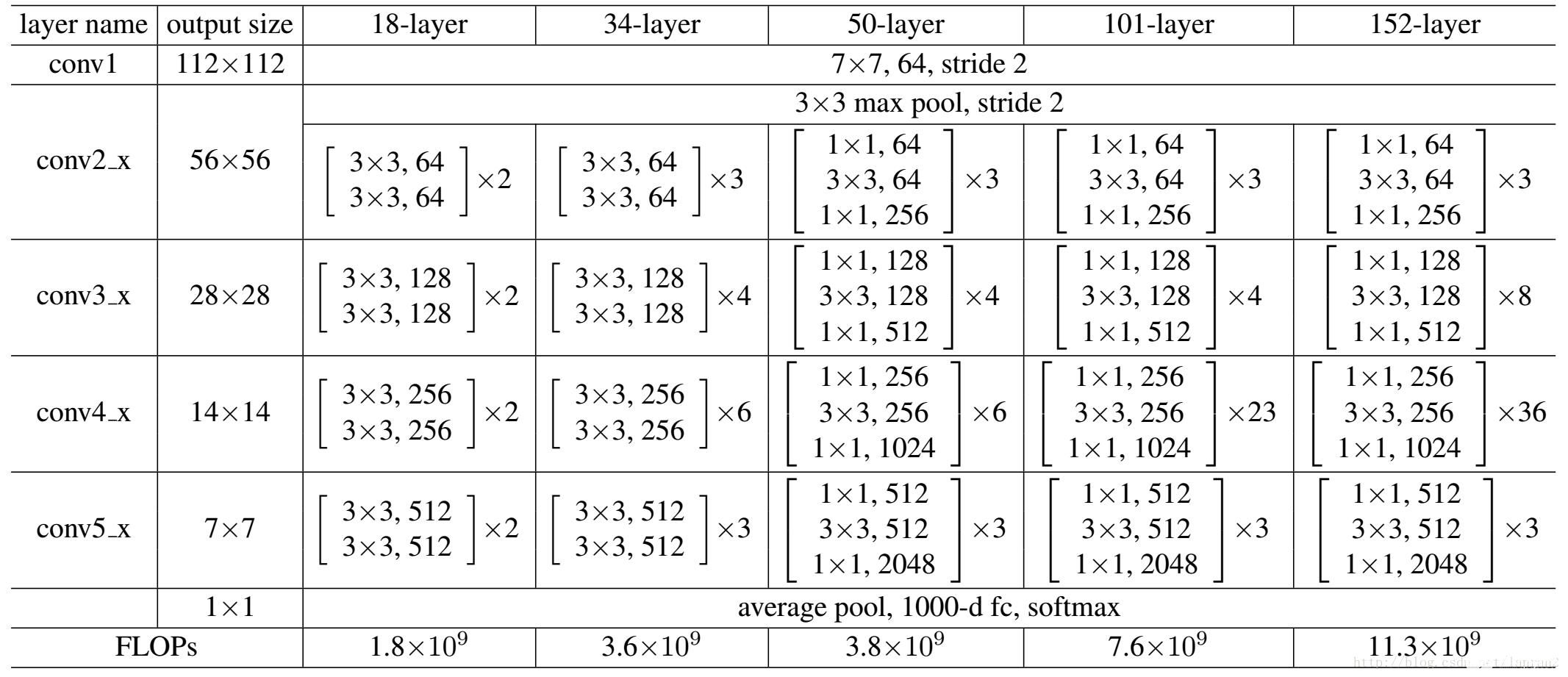
我们看到所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x
其结构是相对固定的,只是通道数根据输入确定。
注意,Resnet 最后的 avg_pool 是把每个 feature map 转换成 1 个特征,故池化野 size 为 feature map size,如 最后输出位 512x7x7,那么池化野size 为 7
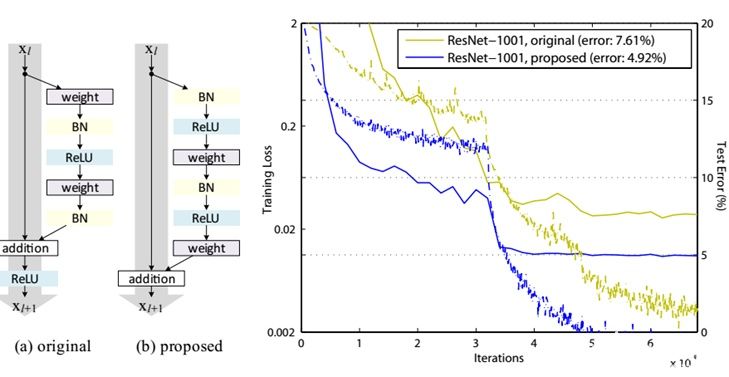
最新进展
残差单元被进一步更新
个人经验
1. 卷积层包含大量的卷积计算,如果想降低时间复杂度,减少卷积层
2. 全连接层包含大量的参数,如果想降低空间复杂度,减少全连接层
转载自努力的孔子
审核编辑 黄昊宇
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:深度学习与图神经网络学习分享:CNN经典网络之-ResNet-图神经网络的应用场景 https://www.yhzz.com.cn/a/6868.html