通过AD采集数据时,我们总是希望采集到的数据是纯净而真实的,而实际上环境中存在太多的干扰信号,为了让我们得到的数据尽可能地接近实际值,我们需要降低这些干扰信号的影响。所以软件实现的数字滤波器应运而生,这一篇我们就来讨论基于中值算术平均的平滑滤波器。
1、问题的提出在我们通过AD采集获取数据时,不可避免会受到干扰信号的影响,而且很多时候我们希望尽可能的将这种影响减到最小。为实现这一目的,人们想了很多办法,有硬件方面的,也有软件方面的。在硬件难以改变或者软件能够达到相应效果时,我们一般采用软件方法来实现,通常称之为数字滤波。
前面我们实现了基于算术平均的中值平均滤波器。这一滤波器可以解决我们一定频率范围内的周期性干扰和随机性的高频干扰。但是随机性的干扰出现的频次我们是不知道的,所以我们采用去掉固定数量的极大值和极小值时,虽然可以去除掉随机干扰的部分影响,但有两种情况还是会对我们的最终计算产生影响。其一是当随机干扰很频繁,我们去掉固定数量的极大值和极小值时,还会有一些受干扰的数据影响到最后的结果。其二是当随机干扰不频繁时,我们去掉固定数量的极大值和极小值就可能会去掉一些周期干扰所影响的数据,那么我们采用平均值的方法就不能很好的消除周期性干扰的影响。
为了消除上述两种情况造成的影响,我们需要改进前述的基于算术平均的中值滤波算法。我们注意到我们的每一次的测量与上一次的测量相距时间很短,数据不会有大幅度的变化,超过一定幅度的数据我们就可以认为它是受到干扰的数据,去除这些受到干扰的数据,我们就可以得到相对理想的结果。
2、算法设计前面我们已经描述了问题的来源,这个问题分为两个层次。第一,我们需要去除不同种类的干扰信号,所以我们必须设计一个针对多种干扰信号的滤波算法。第二,我们需要为丢弃固定数量极大值和极小值,而造成的周期干扰的影响不平衡,导致的算术平均算法不能完全消除周期干扰。
对于第一个层面的问题,其实与上一篇中所描述的问题是一致的。我们知道主要的干扰信号是相对频率较低的周期干扰和相对频率较高的非周期干扰,我们将分析这两种信号的特点并针对性的采取相应的滤波手段。
首先我们来考虑相对频率较低的周期干扰,这种干扰来自于环境并且很难避免,但这种干扰信号具有一定的规律,所以它对正常信号造成的影响也是有一定规律的。我们可以图示如下:
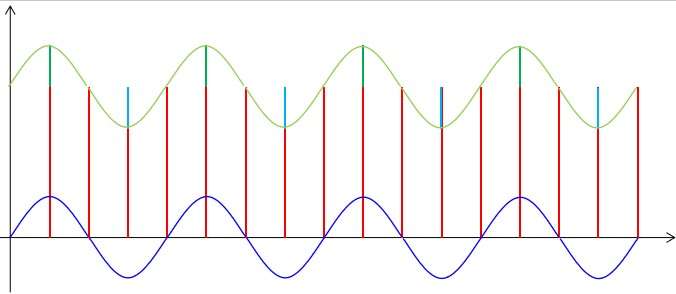
如果只存在这一种周期性的低频率的干扰信号,那么我们很容易想到采用算术平局算法就能够去除,在前面我们也确实是这么做的。事实上如果存在多种频率的周期性干扰信号,只要采集到的数据样本数量足够,采用算数平均算法基本都是可以得到比较理想的结果。在我们的项目中,我们的采集频率达到了1KHz,而我们每100毫秒出一个数,所以从理论上讲,10Hz以上的周期性干扰都可以通过算术平均率波来消除。
接下来我们来考虑相对频率较高的非周期干扰,这种干扰具有较大的随机性,有可能对信号的影响较大,也有可能对信号的影响较小,其频率和幅值都是随机的,测量结果存在很大的偶然性。我们可以简单的图示如下:
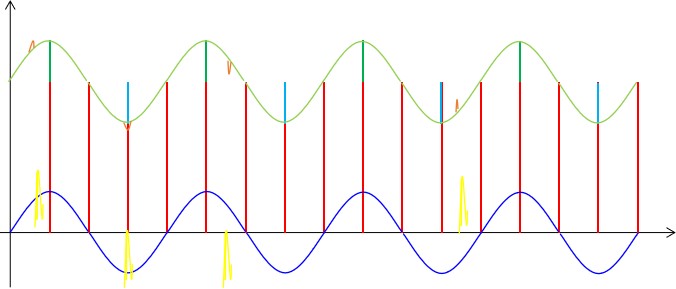
对于这种干扰我们前面的方法对它是没有效果的,但我们的ADC采用的是积分方式来检测信号的,所以在两个采样点之间,无论这类干扰信号在何时出现都会叠加到紧接着的这个采样数据上,致使最终的采样数据比周期性干扰叠加的情况下要么大一些,要么小一些。这就存在两种情况,如果是正向干扰就会是数据变大一些,如果是反向干扰就会是数据变小一些。使得最终的测量数据更加背离原始数据或者更加接近原始数据。
对于更加接近我们需要的数据的变化,我们先不用理会它,毕竟它更加接近我们想要的数据。对于更加偏离的那一部分数据,我们有什么办法将其去除掉呢?办法是有的,我们借鉴比赛积分中去掉偶然性的方式,去掉最高和最低的数,中间的数应该更接近与真实值。具体如下图所示:

这样去掉最大的一些数和最小的一些数后,并不能保证得到的就是真实的信号值,但有一点我们时刻以肯定的就是,余下的值都更为接近真实的信号值。然后我们在对余下的数采取算术平均操作,得到的就是接近真实值的一个采集值了。
而对于第二个层面的问题,我们考虑到我们的测量对象并不会在两次测量之间发生剧烈的变化,所以如果某一个原始数据与上一次的测量结果偏离较大,我们就认为它是一个受到了干扰的数据,我们就将其舍弃。也就是说,以上一次的测量结果为基础,超过上限或者下线的数据我们都认为是异常数据,具体操作图示如下:
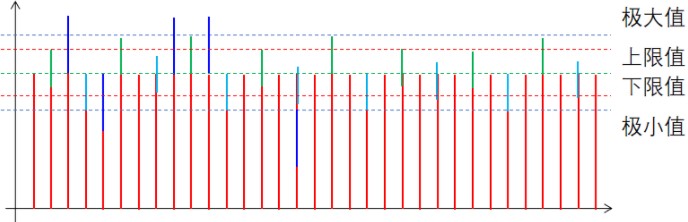
事实上,这一算法不仅可以剔除剧烈变化的异常数据,对于超长周期的干扰也会有一定的抑制作用。
3、编码实现上一节,我们描述了基于算术平均的限幅滤波算法,接下来我们看看具体该如何实现这一算法。根据前述的经验,我们可以将算法的实现分为三个层次:第一,采集到足够多的数据,并将数据排序;第二,将数据中一定数量的极大值和极小值剔除;第三,将超越限幅值的数据剔除并使用算术平均值得到最后结果。
首先来考虑数据采集和排序的问题。数据采集速度不能太低,数据量必须达到一定的数据,约几十至几百的规模。考虑到数据的规模,我们依然采用简单直接的冒泡排序实现数据的极大值和极小值的查找。
其次我们考虑剔除极大值和极小值的问题。我们实现了对数据的排序后,剔除极大值和极小值是非常容易的,关键是提出的数量怎么设置。
最后我们考虑限幅滤波的问题。我们将其超过限幅值的数据去除,并对余下的数据取算术平均。这里存在一个问题,就是如果超出限幅的数据量非常之多,远远超过了没有超限的数据量该怎么办呢?我们认为这使得数据也许真的是因为某些原因而出现了较大的变化。此时我们将对全体数据取算术平均值,以快速响应检测对象的变化。
根据上述的描述,我们可以实现算法如下:
复制/*限幅平均滤波算法*/ static uint32_t LimitedMeanFilter(uint32_t *pData,uint16_t aSize,uint16_t eSize,uint32_t rData,uint32_t lValue) { uint32_t tData; uint32_t uResult=0; uint32_t mResult=0; uint32_t lResult=0; uint16_t uNumber=0; uint16_t mNumber=0; uint16_t lNumber=0; if(aSize<=2*eSize) { return 0; } for (int i=0; i在上述实现中,我们先对输入的数据进行了排序。然后我们去除了一定数量的极大值和极小值,并检测余下的值是否超越了限幅值。并对限幅之内、超越上限及超越下限的数据分别求和。然后判断三类数据的数量,当限幅内数据的数量超过三分之一时,对其取算术平均,否则对所有数据取算术平均。
对于函数中的五个参数:uint32_t *pData是需要滤波的原始采集数据;uint16_t aSize是需要滤波的原始采集数据的数量;uint16_t eSize是需要丢弃的极大值和极小值的数量。其中aSize要远大于eSize的2倍,否则大部分被舍弃,滤波的意义就不大了。uint32_t rData参数是参考值;uint32_t lValue参数是偏离参考值的限幅。
函数的使用也很简单。比如在我们的应用中,我们以1KHz的速度采集原始值,每采集100个数出一个测量结果,去掉10个极大值和10个极小值,于是我们就可以调用函数如下:
复制temp[i]=LimitedMeanFilter(rDatas[i],100,10,refData[aPara.phyPara.waveband][i],150);在这个应用中,我们测试去掉10个极大值和10个极小值,并将限幅的偏差设置为了150,当然这些数值的取值根据具体的应用而定。特别是参考数据的选择非常关键,一般可以根据不同的情况选取上一个测量结果、一定数量的之前的测量结果的算术平均或加权平均,或者采用累计的平均值等。
4、应用总结这一篇中,我们实现了基于算术平均的限幅滤波器。该滤波器对一定频率以上的周期性干扰和随机性的噪声干扰均有较好的效果。通过修改丢弃的极大值和极小值的数量可以应对在不同环境下的滤波要求。也可以对超长周期的干扰和其它原因造成的剧变数据拥有较好的抑制作用。
对于限幅的取值一般只能根据采集系统的特点或者工程师的经验来判断,但并非是盲目的,因为很多情况下我们是能够判断出干扰信号的大致判断范围的。所以限幅值的选取,以及剔除的极大极小值的数量都需要根据集体的应用场景来设置。
此外参考值的选取也会对滤波效果有决定性影响。一般根据具体的应用场景我们可以选取上一个测量结果、一定数量的之前的测量结果的算术平均或加权平均,或者采用累计的平均值等作为参考值。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:基于算术平均算法的限幅滤波器设计-算术均值滤波器例题解析 https://www.yhzz.com.cn/a/5703.html