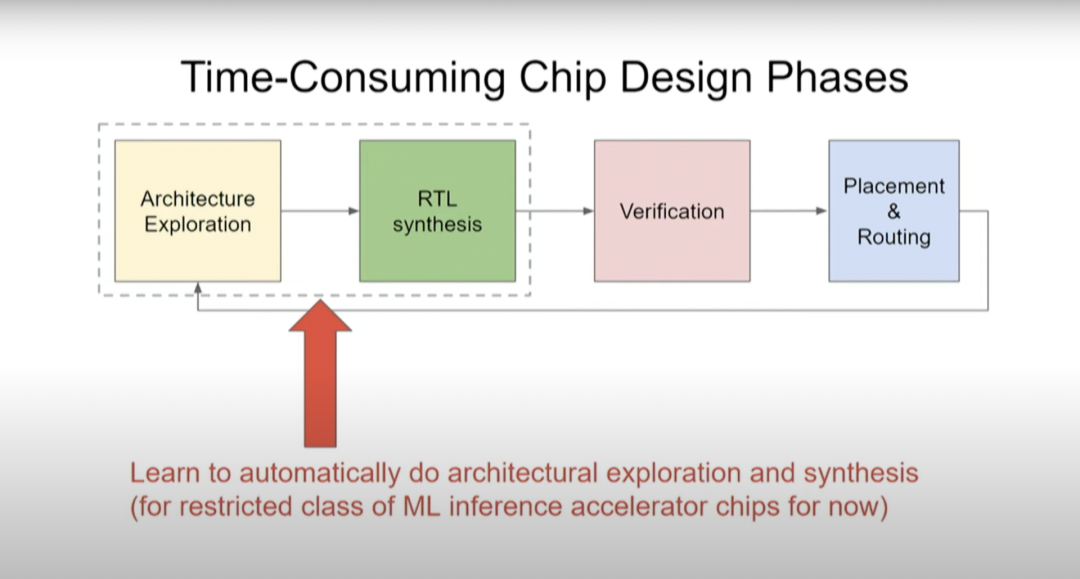
在芯片设计中,另一个比较耗时的方面是要清楚你究竟想要构建何种设计。此时你需要做一些架构探索(architectural exploration),然后做RTL综合。目前计算机架构师和其他芯片设计师等具有不同专业知识的人花费大量时间来构建他们真正想要的设计,然后验证、布局和布线,那么我们可以学习自动做架构探索和综合吗?
现在我们正在研究的就是如何为已知的问题实行架构探索。如果我们有一个机器学习模型,并且想要设计一个定制芯片来运行这个模型,这个过程能否实现自动化,并提出真正擅长运行该特定模型的优秀设计。
关于这项工作,我们在arXiv发表了论文《A Full-stack Accelerator Search Technique for Vision Applications》,它着眼于很多不同的计算机视觉模型。另外一个进阶版本的论文被ASPLOS大会接收了《A Full-stack Search Technique for Domain Optimized Deep Learning Accelerators》。
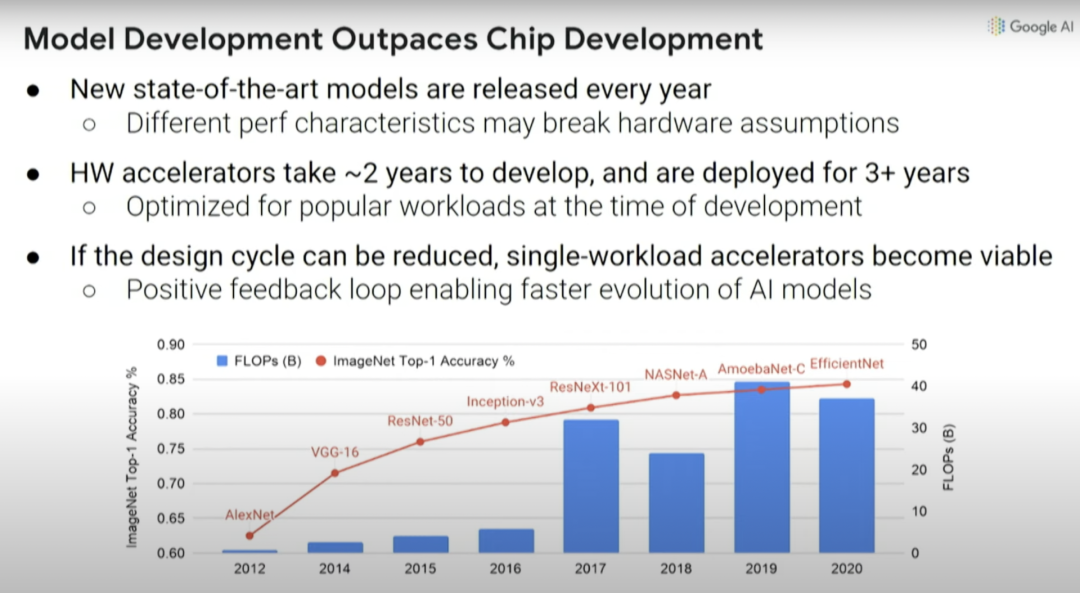
这里要解决的问题是:当你设计一个机器学习加速器时,需要考虑你想在哪个加速器上运行什么样的机器学习模型,而且这个领域的变化非常之快。
上图中的红线是指引入的不同计算机视觉模型,以及通过这些新模型实现的ImageNet识别准确率提升。
但问题是,如果你在2016年想要尝试设计一个机器学习加速器,那么你需要两年时间来设计芯片,而设计出来的芯片三年后就会被淘汰。你在2016年做的决定将会影响计算,要保证在2018年-2021年高效运行,这真的很难。比如在2016年推出了Inception-v3模型,但此后计算机视觉模型又有四方面的大改进。
因此,如果我们能使设计周期变得更短,那么也许单个工作负载加速器能变得可用。如果我们能在诸多流程中实现自动化,那么我们或许能够得到正反馈循环,即:缩短机器学习加速器的上市时间,使其能更适合我们当下想要运行的模型,而不用等到五年后。
4用机器学习探索设计空间
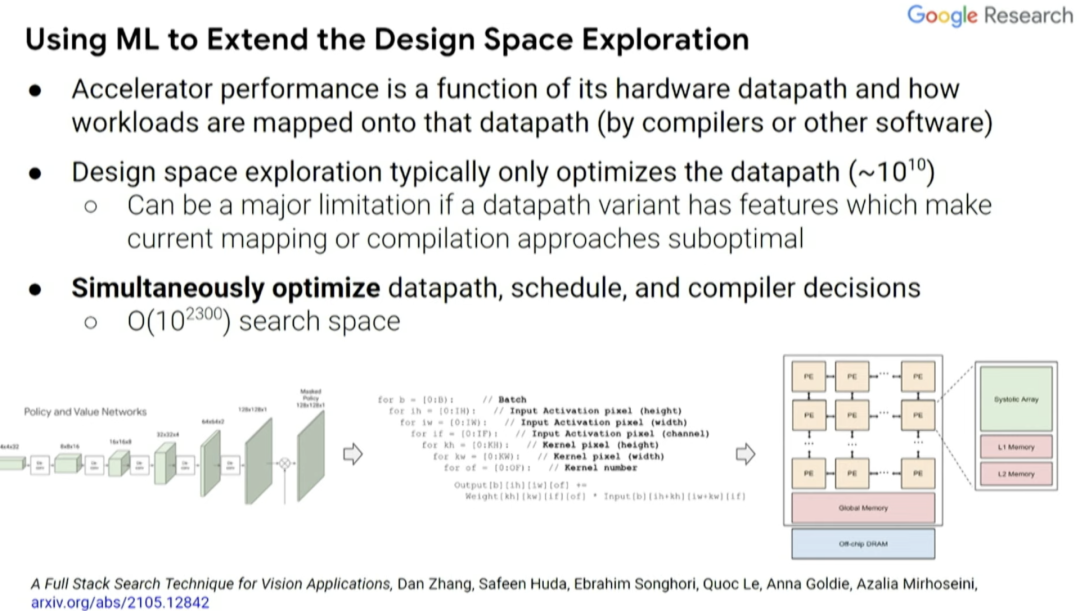
实际上,我们可以使用机器学习来探索设计空间。有两个因素影响加速器性能,一是设计中内置的硬件数据通道,二是工作负载如何通过编译器而不是更高级别的软件映射到该数据通道。通常,设计空间探索实际上只考虑当前编译器优化的数据通道,而不是协同设计的编译器优化和优化数据通道时可能会做的事。
因此,我们能否同时优化数据通道、调度(schedule)和一些编译器决策,并创建一个搜索空间,探索出你希望做出的共同设计的决策。这是一种覆盖计算和内存瓶颈的自动搜索技术,探索不同操作之间的数据通道映射和融合。通常,你希望能够将事物融合在一起,避免内存传输的每次内存负载中执行更多操作。
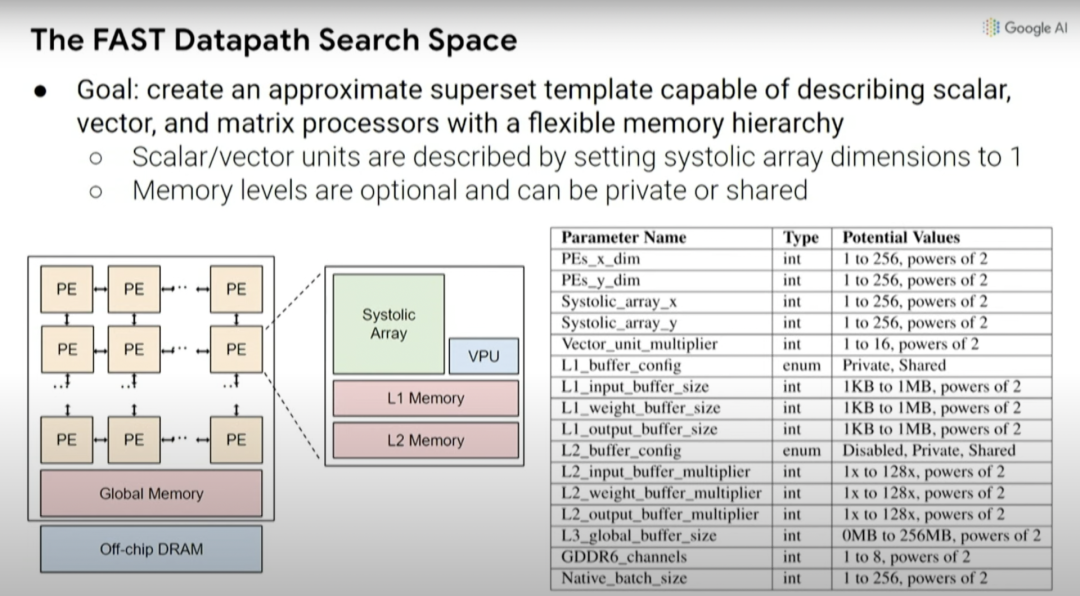
根本上说,我们在机器学习加速器中可能做出的设计决策创建了一种更高级别的元搜索空间,因此,可以探索乘法的脉冲列阵(systolic array)在一维或二维情况下的大小,以及不同的缓存大小等等。
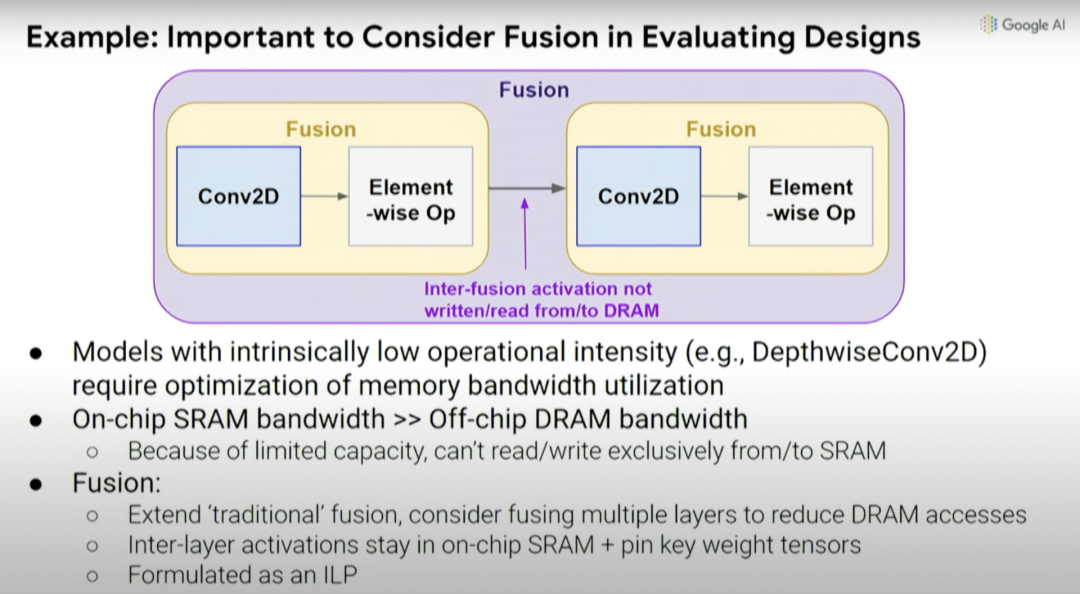
如前所述,考虑编译器优化与硬件设计的协同设计也很重要,因为如果默认编译器不会更改,就无法真正利用处理器中底层设计单元的变化。实际上,不一定要考虑特定设计的所有效果和影响。
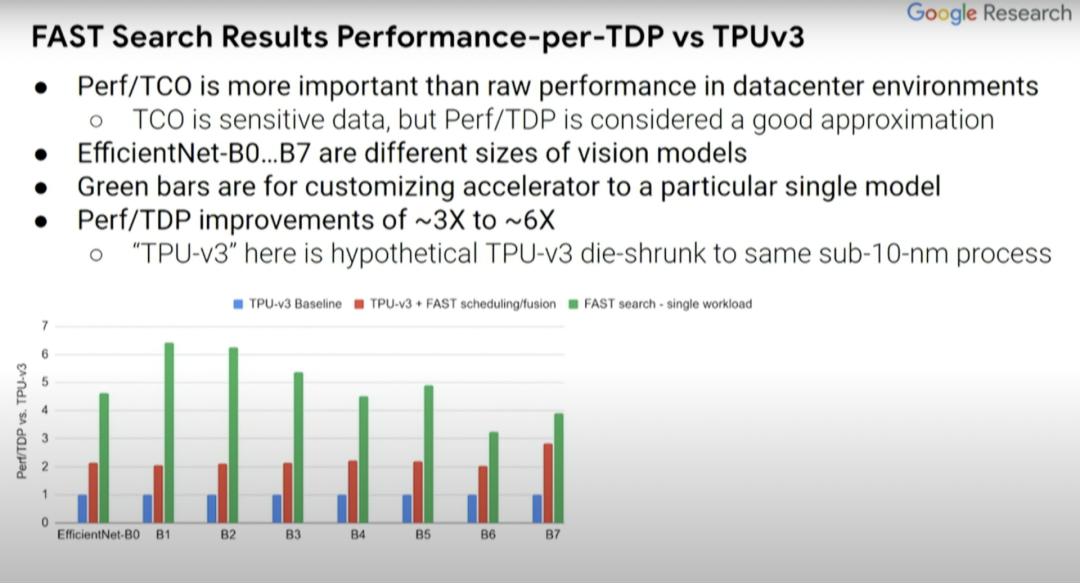
接下来看看这种方式产生的一系列结果,将这些结果与TPUv3芯片的baseline(上图蓝条)进行比较。实际上这是假定型TPUv3芯片,其中模拟器已停止了运行。我们已经将其缩小到了sub-10纳米工艺。我们还将研究TPUv3的软件效用,以及共同探索在设计空间中的编译器优化。
红条和蓝条表示的内容是一致的,但一些探索过的编译器优化不一定在蓝条中得以体现,而这里的绿条则表示的是为单一计算机视觉模型定制的假定型设计。EfficientNet-B0…B7表示相关但规模不同的计算机视觉模型。与蓝条baseline相比,(绿条的)Perf/TDP的改进大约在3到6倍之间。
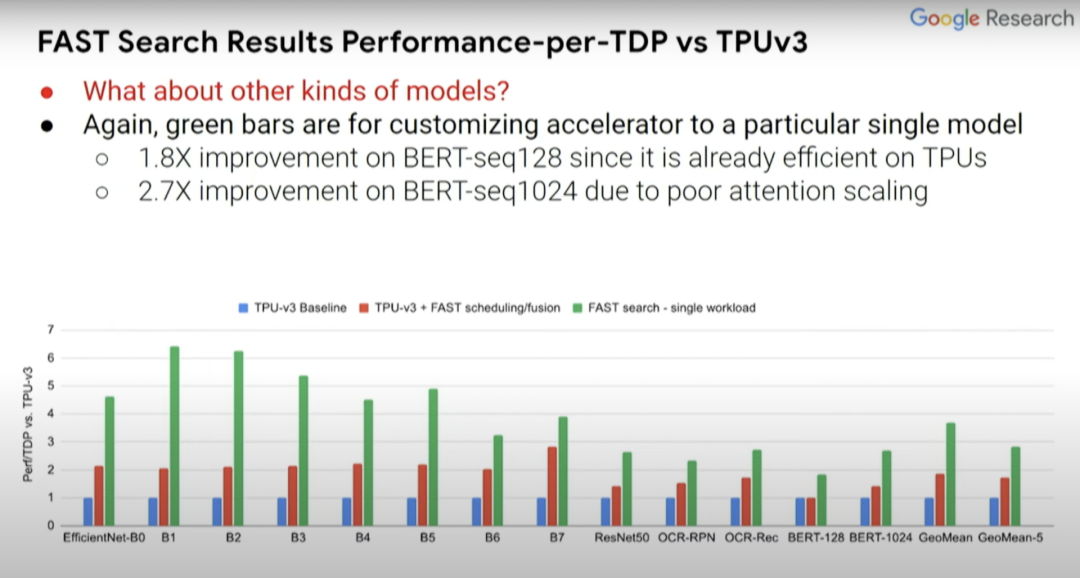
那么除EfficientNet-B0…B7外,其他模型的情况如何?在此前所述的ASPLOS论文中提出更广泛的模型集,尤其是那些计算机视觉以外的BERT-seq 128和BERT-seq 1024等NLP模型。
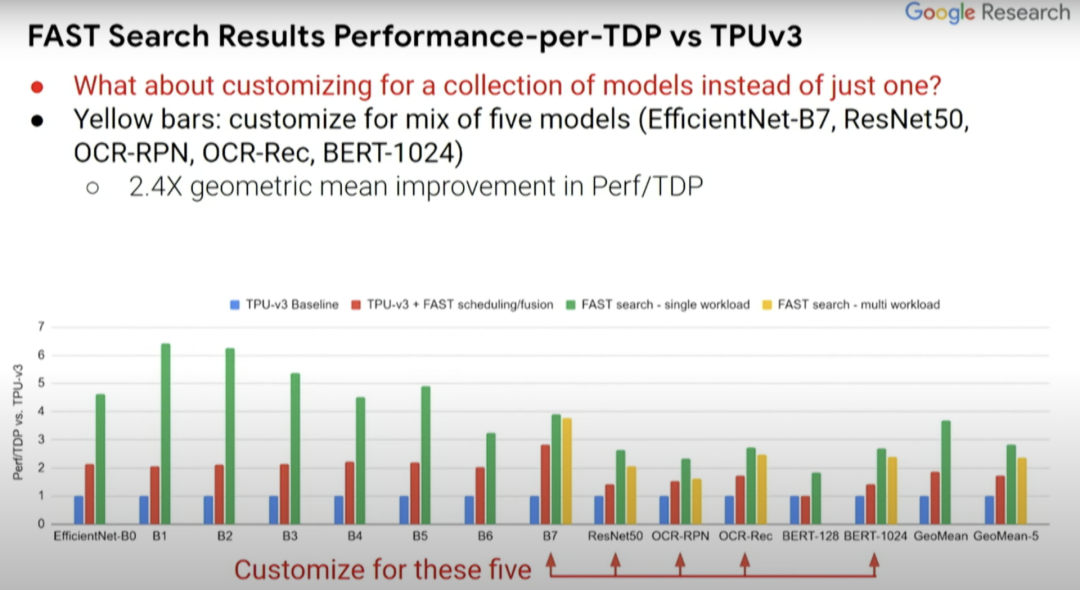
实际上,定制化芯片不只是适用于单个机器学习模型,而是使其适用于一组机器学习模型。你可能不想使你的加速器芯片设计仅针对某一项任务,而是想涵盖你所关注的那一类任务。
上图的黄条代表为五种不同模型设计的定制化芯片,而我们想要一个能同时运行这五种模型(红色箭头所指)的芯片,然后就能看出其性能能达到何种程度。可喜的是,从中可以看到,黄条(单一负载)并不比绿条(多负载)的性能低多少。所以你实际上可以得到一个非常适合这五种模型的加速器设计,这就好比你对其中任何一个模型都进行了优化。它的效果可能不是最好的,但已经很不错了。
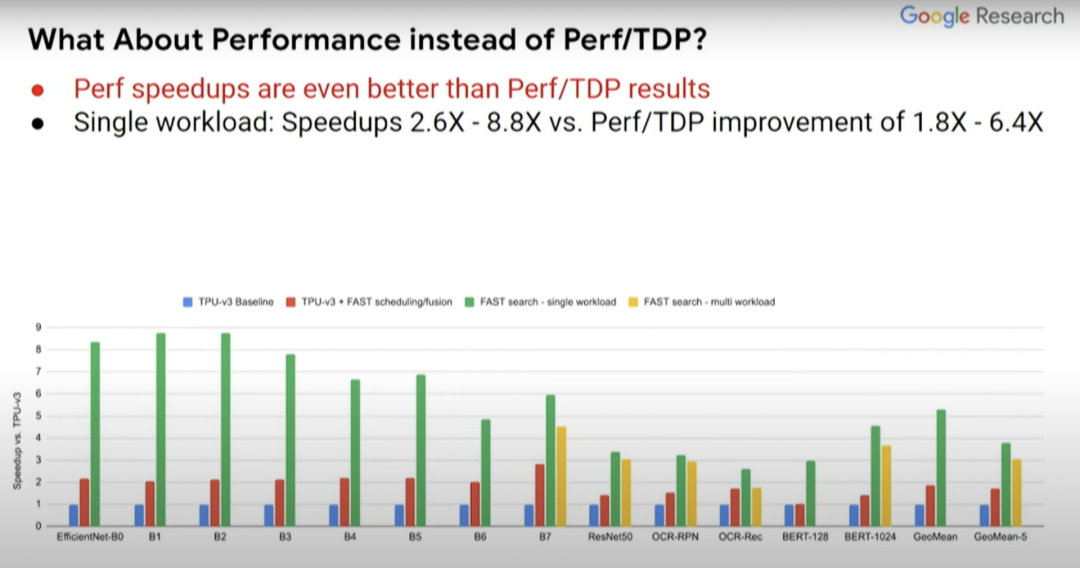
而且,如果你关注的点是性能而非Perf/TDP,得到的结果实际上会更好。所以结果如何取决于你关注的是什么,是绝对性能还是每瓦性能?在Perf//TDP指标中,性能结果甚至提升了2.6到8.8倍,而非Perf/TDP指标下的1.8到6.4倍。
因此,我们能够针对特定工作负载进行定制和优化,而不用构建更多通用设备。我认为这将会带来显著改进。如果能缩短设计周期,那么我们将能以一种更自动化的方式用定制化芯片解决更多问题。
当前的一大挑战是,如果了解下为新问题构建新设计的固定成本,就会发现固定成本还很高,因此不能广泛用于解决更多问题。但如果我们能大幅降低这些固定成本,那么它的应用面将会越来越广。
5
总结
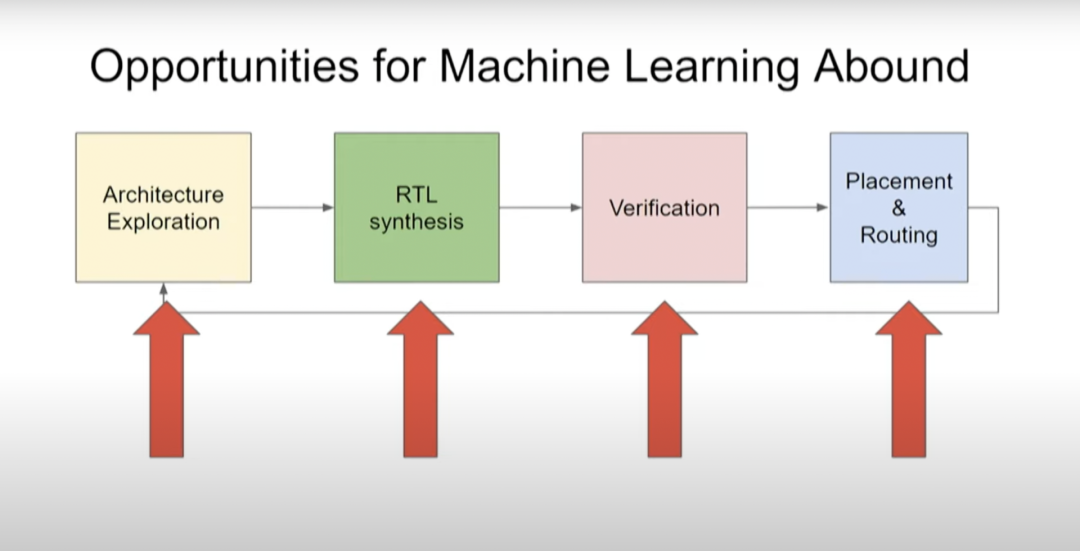
我认为,在计算机芯片的设计过程中,机器学习将大有作为。
如果机器学习在合适的地方得以正确应用,那么在学习方法(learning approaches)和机器学习计算的加持下,芯片设计周期能不能缩短,只需要几个人花费几周甚至几天完成呢?我们可以用强化学习使得与设计周期有关的流程实现自动化,我认为这是一个很好的发展方向。
目前人们正通过一组或多组实验来进行测验,并基于其结果来决定后续研发方向。如果这个实验过程能实现自动化,并且能获取满足该实验正常运行的各项指标,那么我们完全有能力实现设计周期自动化,这也是缩短芯片设计周期的一个重要方面。

这是本次演讲的部分参考文献以及相关论文,主要涉及机器学习在芯片设计和计算机系统优化中的应用。

机器学习正在很大程度上改变人们对计算的看法。我们想要的是一个可以从数据和现实世界中学习的系统,其计算方法与传统的手工编码系统完全不同,这意味着我们要采取新方式,才能创建出我们想要的那种计算设备和芯片。同时,机器学习也对芯片种类和芯片设计的方法论产生了影响。
我认为,加速定制化芯片设计过程中应该将机器学习视为一个非常重要的工具。那么,到底能否将芯片设计周期缩短到几天或者几周呢?这是可能的,我们都应该为之奋斗。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:机器学习如何影响计算机硬件设计3-机器学习 周志华 https://www.yhzz.com.cn/a/4455.html