1, 介绍
我们可以把物理内存简单地看成一个大的数组,其中每个字节都可以通过物理地址进行访问。
前面的文章《一文搞懂DDR SDRAM工作原理》介绍过物理内存的物理结构,及怎么通过控制器、PHY读、写SDRAM芯片获取、写入数据,让我们明白物理内存在硬件原理方面的实现是什么样的。
在《一文搞懂CPU的工作原理》介绍过CPU访问物理内存的全过程,总结下来就是:
CPU写物理内存的过程:CPU先给出要写入数据的物理地址对应的虚拟地址,通过MMU转化为物理地址,若cache中没有命中,则将要写入数据的物理地址放到系统总线上。DDR的控制器感受到总线上的地址信号以及写控制信号,将物理地址从总线上读出来,并等待数据的到达。CPU将数据发送到系统总线上,DDR控制器感受到总线上的数据信号,将数据从总线上读取出来。DDR控制器通过物理地址找到相应的存储模块,然后将数据写入到物理地址对应的存储模块。
CPU读物理内存的过程:CPU给出要读数据的物理地址对应的虚拟地址,通过MMU转化为物理地址,若cache中没有命中,则将物理地址放到系统总线上。DDR控制器感受到总线上的地址型号及读控制信号,将物理地址从总线上读取出来,DDR控制器根据物理地址找到存储模块中数据的位置,并从SDRAM芯片中取出物理地址对应的数据,DDR控制器将数据放到总线上,CPU从总线上获取数据,并存放到寄存器上。
之前已经讲述过CPU读、写物理内存的过程,本文主要讲述linux内核是怎么管理物理内存,包括物理内存涉及的数据结构、内存模型、内存架构、物理内存的管理流程。
2, 数据结构
与物理内存相关的数据结构有内存节点(pglist_data)、内存管理区(zone)、物理页面(page)、mem_map数组、页表项(PTE)、页帧号(PFN)、物理地址(paddress)。
Linux内核通过struct page来管理物理内存中的一个页。内核为每个物理页定义了一个索引编号PFN(Page Frame Number,页帧号),这个PFN与struct page是一一对应的。通过page_to_pfn/pfn_to_page两个宏实现物理页和struct page之间的相互转换。

3, 框架
3.1 内存架构
在当前的计算机、嵌入式系统中,以内存为研究对象可以分成两种架构。一种是UMA(Uniform Memory Access,统一内存访问)架构,另外一种是NUMA(Non-Uniform Memory Access,非统一内存访问)架构。
1) UMA内存架构
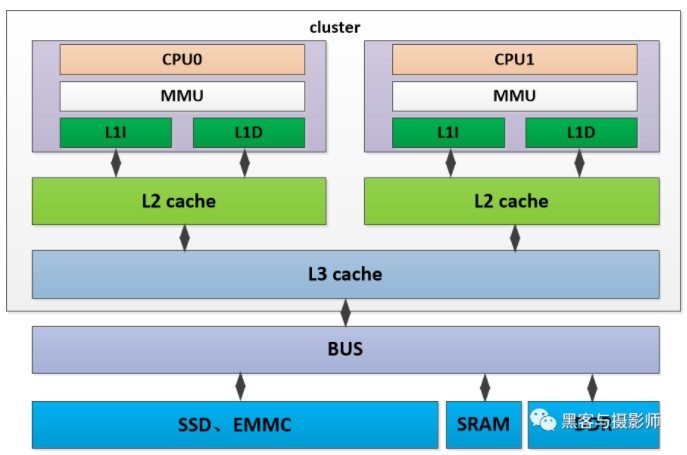
内存可以被其他模块统一寻址,有统一的结构。目前,大部分嵌入式系统及计算机系统都采用UMA架构。如上图所示,是一个UMA架构的系统,有两个cpu位于同一个cluster中,cpu分别有自己的L1D、L1I cache及L2 cache。两个cpu共享L3 cache,通过系统总线可以访问物理内存DDR,SRAM、SSD等模块,并且两个CPU对物理内存的访问消耗是一样的。这种访问模式的处理器被成为SMP(Aymmetric Multiprocessing,对称多处理器)
2) NUMA内存架构
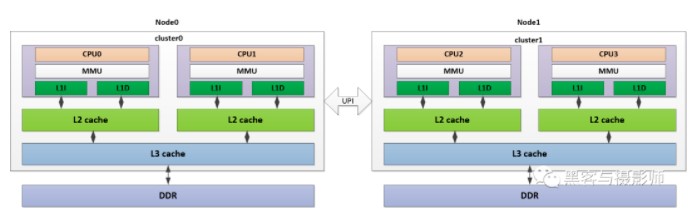
系统中有多个内存节点和多个cpu cluster,CPU访问本地内存节点的时间开销最小,访问远端的内存节点的时间开销要大。如上图所示,是一个NUMA架构的系统,其中cpu0、cpu1在cluster0中,与相应的L1I/L1D cache、L2 cache、L3 cache及DDR组成node0节点。同样的,CPU2、CPU3在cluster1中,与相应的L1I/L1D cache、L2 cache、L3 cache及DDR组成node1节点。两个node节点,通过UPI(Ultra Path Interconnect,超路径互联)总线连接。CPU0可以通过这个UPI访问远端node1上的物理内存,但是要比本地node0的内存访问慢得多。
3.2 内存模型
内核是以页为单位使用struct page数据结构来管理物理内存的。内核通过物理内存模型来实现组织管理这些物理内存页,不同的物理内存模型,应对的场景及页帧号与物理页之间的计算方式也不一样。
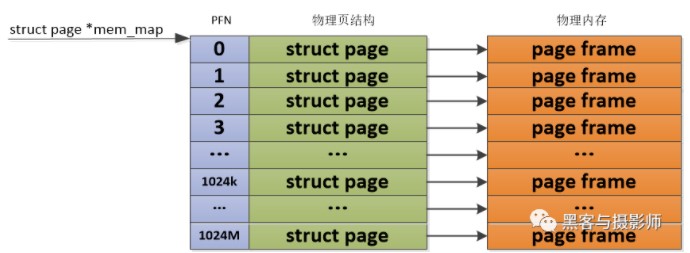
1) 平坦内存模型:FLATMEM
Linux早期使用的物理内存比较小,比如几十MB,并且这些物理内存是一片连续的存储空间,这样物理地址也是连续的,按固定页大小划分出来的物理页也是连续的。Linux内核会用一个mem_map全局数组来组织管理所有的物理页,其中物理页是通过struct page来管理,这样每个数组的下标便是PFN。这种连续的物理内存便是平坦内存模型。
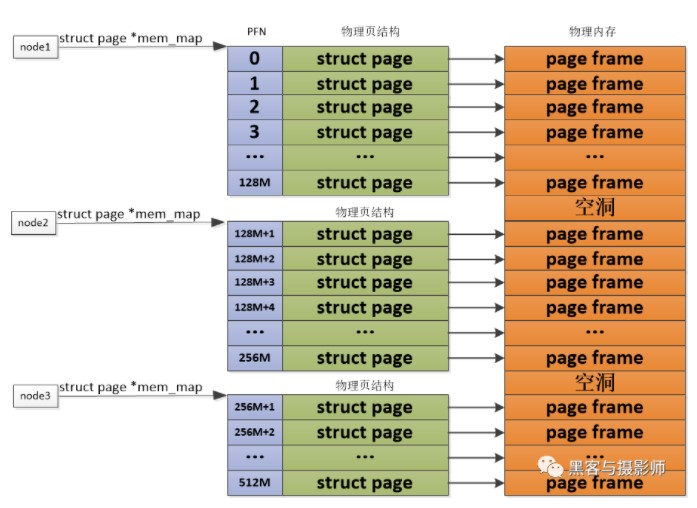
 2) 非连续内存模型:DISCONTIGMEM
2) 非连续内存模型:DISCONTIGMEM
对于PLATMEM适合管理一整块连续的物理内存,但是对于多块非连续的物理内存,若使用FLATMEM来管理,这时mem_map全局数组中会有不连续内存地址区的内存空洞,这会造成内存空间的浪费。为了管理这种不连续的物理内存,内核引入了DISCONTIGMEM非连续内存模型来管理,以便消除不连续的内存地址空洞对mem_map全局数组造成的空间浪费。
DISCONTIGMEM非连续内存模型的思路是:将物理内存从宏观上划分成一个个节点node,但是微观上还是以物理页为单位,每个node节点管理一块连续的物理内存,这样这些非连续的内存,会以连续的内存方式划分到node节点中管理起来,这样便可以避免内存空洞造成的空间浪费。
3) 稀疏内存模型:SPARSEMEM
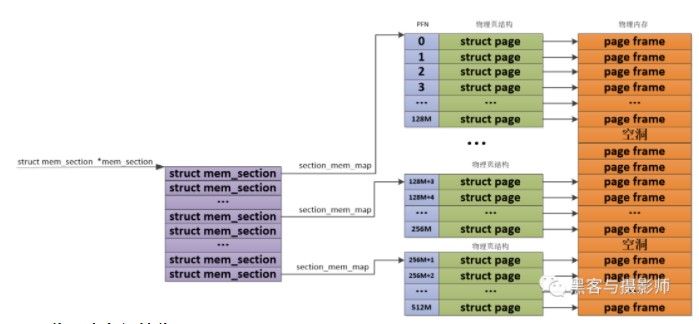
由于物理内存在使用的时候,会有很多空洞,这样物理内存存在多处不连续。如果利用上面讲的DISCONTIGMEM内存模型,会造成node众多,这样开销就大了。为了能够更灵活、更高效的、更小的管理连续物理内存。SPARSEMEM系数内存模型就是为了对粒度更小的连续内存块进行精细的管理,用于管理连续内存块的单元被称为section。在内存中用struct mem_section结构体表示SPARSEMEM模型中的section。
由于section被用作管理小粒度的连续内存块,这些小的连续物理内存在section中也是通过数组的方式被组织管理,其中mem_section结构体中的section_mem_map指针用于指向section中管理连续内存的page数组。SPARSEMEM内存模型中的mem_section会存在放在一个全局的数组中,并且每个mem_section都可以在系统运行的时候进行内存的offline/online,这样便可以支持内存的热拔插。
 4, 物理内存初始化
4, 物理内存初始化
4.1 内存大小初始化
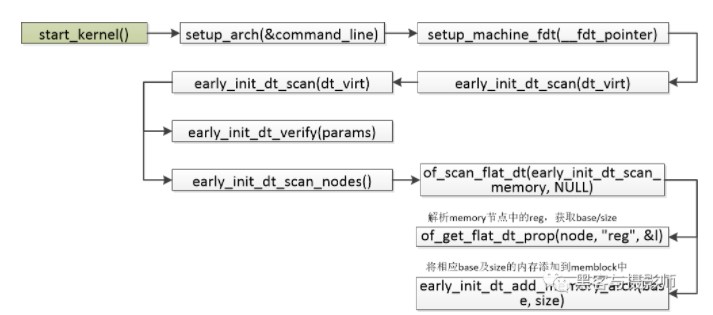
物理内存的大小会在DTS(Device Tree Source,设备树)中描述,如下dts的描述:
memory { device_type = “memory”; reg = <0x000000000 0x80000000 0x00000000 0x40000000>; };
起始地址为0x80000000,大小为0x40000000
内存在启动的过程中,会解析上面的DTS,相应的调用过程如下:
4.2 memblock内存分配器
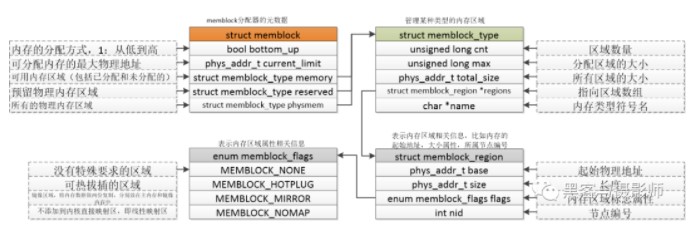
在伙伴系统没有初始化前,在内核中需要一套机制管理内存的申请与释放。在启动的过程中,会解析设备树中的memory节点,把所有物理内存添加到memblock中。后面会通过一篇文章讲解memblock分配器。这里先把结构体及函数接口列出来。

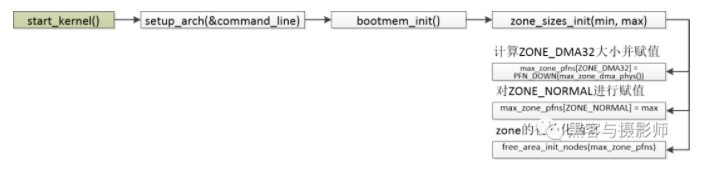
4.3 ZONE初始化
在对页表初始化后,内核就会对内存进行管理。内核会将这些物理内存分配成不同的内存管理区(ZONE),分别针对这些内存管理区进行管理。
常见的内存管理区如下:
ZONE_DMA:用于inter X86 ISA设备的DMA操作,范围是0~16MB,ARM没有这个内存管理区。
ZONE_DMA32:用于最低4GB的内存访问的设备,如只支持32位的DMA设备。
ZONE_NORMAL:4GB 以后的物理内存,用于线性映射物理内存。若系统内存小于4GB,则没有这个内存管理区。
ZONE_HIGHMEM:用于管理高端内存,这些高端内存是不能线性映射到内核地址空间的。64位Linux是没有这个内存管理区的。
其中ZONE是利用struct zone数据结构进行管理的,zone数据结构经常会被访问,因此为了提升性能,这个数据结构要求以L1高速缓存对齐。数据结构zone中关键的成员如下:
Watermark:每个zone在系统启动时会计算出3个水位,分别是WMARK_MIN(最低警戒水位)、WMARK_LOW(低水位)、WMARK_HIGH(高水位),这些在页面分配器和kswapd页面回收中会用到。
Lowemem_reserve:防止页面分配器过渡使用低端zone的内存。
Zone_pgdat:指向内存节点。
Pageset:用于维护每个cpu上的一些列页面,以减少自旋锁的使用
Zone_start_pfn:zone的起始页帧号。
Managed_pages:zone中被伙伴系统管理的页面数量。
Spanned_pages:zone中包含的页面数量。
Present_pages:zone里实际管理的页面数量。对于一些架构来说,它和spanned_pages数量一致。
Free_area:伙伴系统核心的数据结构,管理空闲也快链表的数组。
Lock:并行访问时用于保护zone的自旋锁。
Lruvec:LRU链表集合。
4.4 伙伴系统
内核启动完成后,物理内存的页面就要添加到伙伴系统中来管理了。伙伴系统(buddy system)是操作系统中常用的动态内存管理方法。用户提出申请时,分配一个大小合适的物理内存,当用户释放后,回收相应的物理内存。后面会专门写一篇介绍伙伴系统的文章,这里只做简单的介绍。
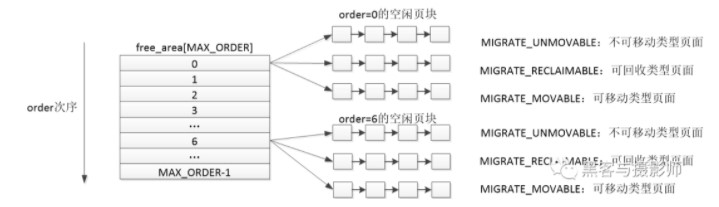
在伙伴系统中,内存块的大小是2的order次幂个页帧。Linux中order的最大值是11。伙伴系统大致的思想是,将所有空闲的物理内存页面分组成11个内存块的链表,每个内存块的链表分别包含1、2、4、8、16、32、…、1024个连续的物理页面。1024个物理页面对应着4MB大小的连续物理内存。
由上一节我们了解到,物理内存在linux中分出了几个ZONE来管理空闲物理页块。ZONE可以根据内核的配置来划分。每个ZONE又是利用伙伴系统来管理。ZONE的数据结构有一个free_area数据结构,数据结构的大小是MAX_ORDER(11)。free_area数据结构中包含了MIGRATE_TYPES个链表。可以理解成ZONE根据order的大小由0~(MAX_ORDER-1)个free_area,每个free_area根据MIGRATE_TYPES类型,由几个相应的链表组成。
 审核编辑:刘清
审核编辑:刘清
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:linux内核是怎么管理物理内存的呢?-linux申请物理内存mmp https://www.yhzz.com.cn/a/3920.html