本文主要参考《操作系统概念》一书总结一下我对多线程程序的理解,如有错误还望指正。
1 进程与线程
1.1 进程
进程(Process):程序执行时,其编译出来的可执行文件会被读取到内存,操作系统会为其分配计算机资源(CPU 时间、地址空间、I/O……),得到一道程序实例,称为进程。进程与程序代码并不能直接划等号,进程中除了包含程序代码外,还包含程序运行时产生的临时数据以及操作系统管理进程而“注册”的信息。一个进程通常由三部分构成:
程序段:能被操作系统调度到 CPU 执行的程序代码段。程序可以被多个进程共享,也即同一段程序可以对应多个进程实例。数据段:包含程序在运行时产生的临时数据进程控制块(Process Control Block, PCB):PCB 是进程存在的唯一标识,用于操作系统管理进程。在进程开始时创建,在进程结束时回收。汇编语言与 C/C++ 程序都有“段”的概念。以 32 位 x86 汇编程序为例,段寄存器存放段描述符表指针,一个段描述符表示一个程序段的类型,比如代码段、数据段、堆栈段。
进程控制块(Process Control Block, PCB):操作系统通过 PCB 管理多道近处。PCB 是进程存在的唯一标识,在进程开始时创建,在进程结束时回收。进程控制块包含如下四个部分:
进程描述信息进程标识符:标志各个进程,每个进程都有一个并且是唯一的标识号。用户标识符:进程归属的用户,用户标识符主要为共享和保护服务。进程控制和管理信息进程当前状态:描述进程的状态信息,作为处理机分配调度的依据。进程优先级:描述进程抢占处理机的优先级,优先级高的进程可以优先获得处理机。资源分配清单,用于说明有关内存地址空间或虚拟地址空间的状况;所打开文件的列表和所使用的输入/输出设备信息。处理机相关信息,主要指处理机中各寄存器值,当进程被切换时,处理机状态信息都必须保存在相应的PCB中,以便在该进程重新执行时,能再从断点继续执行操作系统引入进程是为了能使多道程序并发执行,提高资源的利用率与系统的吞吐量。进程之间是相互独立的,在创建和销毁进程时,都需要申请与回收其独占的计算资源,这些操作都有不小开销。进程是并发执行的,当发生进程切换时,需要保存当前进程的状态,这些数据是非常多,切换的代价也不小。因此为了进一步提高利用率与吞吐量,同时降低开销,引入了线程(Thread)的概念。
1.2 线程
线程(Thread):一个进程可以包含多条线程。线程共享进程的全部资源,所以线程在创建时,不需要申请和回收计算资源。线程有自己的程序计数器、寄存器集合和堆栈,因此在切换时只需要保存少量寄存器内容。
线程分为内核线程(Kernel Thread)与用户线程(User Thread)。每个进程至少有一个内核线程,也称为“轻量级进程”,操作系统会为内核线程创建相应的线程控制块(Thread Control Block,TCB),内核线程是操作系统调度的实体。开发者不能直接控制内核线程,但为了编写多线程程序逻辑,增加代码的可移植性,操作系统都会为开发者提供线程库来创建和管理用户线程。内核线程与用户线程的关系如下:
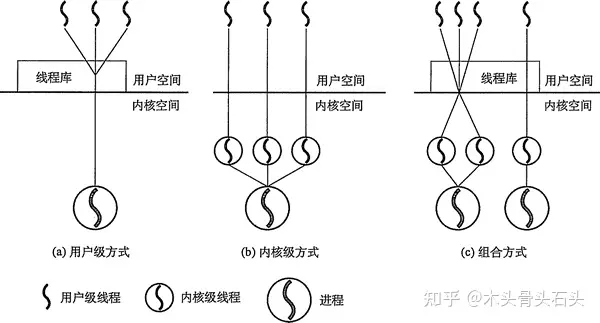
多对一模式(用户级方式):多条用户线程对应一条内核线程,此时也可看成没有内核线程,内核线程就是进程本身。线程的管理在用户空间完成,内核并不知道用户线程的存在,多条用户线程分时间片得映射到内核线程上执行。用户线程切换时,上下文保存在进程空间,开销小。缺点在于,当内核线程发生阻塞时,所有用户线程都会被阻塞。
一对一模式(内核级方式):一条用户线程对应一条内核线程,优点在于一条内核线程阻塞时不会阻塞该进程中其他线程,缺点是每创建一条用户线程同时要创建一条新的内核线程,参与调度的内核线程变多会影响整体的性能。
多对多模式(组合方式):主流的映射方式。同时兼顾了多对一模式和一对一模式的优缺点,既保证并发性,又避免创建多过的内核线程。
引入线程的概念后,进程的角色也发生了变化,线程成为了操作系统调度的实体,而进程变成了系统资源分配的实体。一道进程至少包含一条线程,称为主线程,从线程中可以创建更多的线程,操作系统调度多道线程在处理器上并发或并行执行。
2 并发与并行
多道进程(或线程)有两种“同时”执行方式:并发计算(Concurrent computing)与并行计算(Parallel Computing) 。这两种方式都能提高计算资源的利用率与处理器的吞吐量,下面详细介绍两者的区别。
2.1 并发
并发:指在某一时钟周期内实际只有一条指令在处理器上执行,操作系统负责调度多道进程(或线程),分时间片在处理器上执行。因为切换是非常迅速且频繁的,所以在宏观上会感觉多道进程(或线程)是在“同时”执行。如果没有并发,对于程序中那些耗时较长的操作,比如 I/O,会阻塞进程(或线程),使 CPU 等待,浪费计算资源。
对于并发执行的多道进程(或线程),操作系统需要实现一个调度策略,让这多道程序分时间片共享 CPU 计算资源。现有的调度算法多种多样,但没有一种算法适用于所有情况。在介绍调度算法前,先介绍调度的基本准则,一般通过这五大准则衡量各种调度算法:
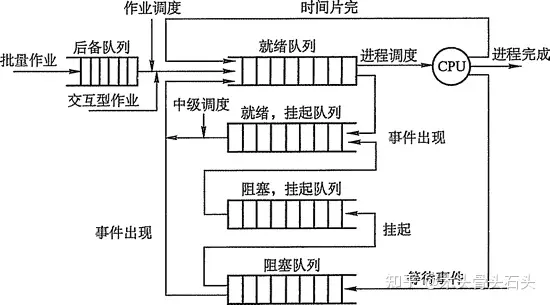
CPU 利用率:应该尽可能使 CPU 保持忙碌,提高其利用率系统吞吐量:单位时间 CPU 完成的作业数,吞吐量也应该越大越好周转时间:从作业提交到作业完成的时间,越短越好等待时间:作业处于等待状态的总时间,越短越好响应时间:从用户提交到系统首次产生响应的时间,越短越好一个待执行的程序会在多个队列中轮转,直到执行完毕。如下图:
下面介绍几种常见的调度算法,并评估它们的优劣。
先到先服务(First Come First Serve,FCFS):从就绪队列中选择最先进入队列的线程分配 CPU 资源执行,直到执行完毕或者阻塞。从表面上看,FCFS 对所有作业都是公平的,但若一个长作业先到达系统,就会使后面许多短作业等待较长时间,降低系统吞吐量,增加平均响应时间。FCFS 效率低,通常与其他调度策略相结合。比如,在使用优先级调度算法中,多个相同优先级的线程按 FCFS 原则处理。
短作业优先(Shortest Job First,SJF):从就绪队列中选择执行时间最短的线程分配 CPU 资源执行。SJF 的平均等待时间、平均周转时间理论上是最短的。SJF 对短作业有利,对长作业不利,甚至会导致长作业“饥饿”。
优先级调度(priority scheduling):从就绪队列中选择优先级最高的线程分配 CPU 资源执行。根据新的高优先级线程能否抢占正在执行的线程,可分为:
抢占式调度(preemptive scheduling):当一道作业正在处理机上执行时,若另一个更为重要的或紧迫的作业需要使用处理机,则立即暂停正在执行的作业,将处理机分配给这个更为重要或紧迫的作业非抢占式调度(non-preemptive scheduling):与抢占式调度相反,只有当前作业执行完毕或进入阻塞状态时,才把处理机分给更重要的作业优先级调度也会造成低优先级线程“饥饿”,因此大多数操作系统都会根据实际情况动态改变线程的优先级,比如当一个线程等待时间越长,相应的其优先级也会越高。
时间片轮转(Round Robin,RR):从就绪队列中选择最先进入队列的线程分配 CPU 资源执行,但与 FCFS 不同的是,该线程只能运行一个时间片。当线程执行完毕、阻塞或时间片用完,会剥夺其执行权。在 RR 中,时间片的大小对系统的性能影响很大,如果时间片过大会退化为 FCFS,如果时间片过小,会造成频繁的切换。时间片的长短通常根据平均响应时间、就绪队列中的线程数和系统的处理能力动态变化。
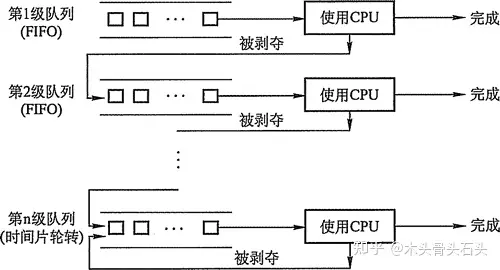
多级反馈队列调度:结合了优先级调度与时间片轮转算法。系统会有多个就绪队列,线程会根据其优先级进入不同的就绪队列中,优先级越高的队列时间片越小。当一个新线程提交后进入第一级队列末尾,根据 FCFS,当轮到该线程时,在时间片用完后仍未执行完毕则被剥夺执行权,并放入下一级队列末尾。仅当一级队列为空时,才调度下一级队列中的线程执行,当此时有新的线程被提交时,第 i 级队列的线程将会被抢占,重新切换到第一级队列中执行。
2.2 并行
并行:指在某一 CPU 时钟周期内,可以同时执行多条指令,这需要多核处理器的支持,是真正意义上的同时执行多条指令。
下文主要参考 Introduction to Parallel Computing Tutorial阿姆达尔定律(Amdahls Law)说明了并行程序潜在的性能提升:
speedup=11−p\text{speedup} = \frac{1}{1-p}\\
其中,p 是程序的并行率,当没有任何一段代码可以并行时, p=0,speedup=1\text{p}=0,\ \text{speedup}=1 ;如果所有代码都可并行,则 p=1,speedup=∞\text{p}=1,\ \text{speedup}=\infty 。如果考虑计算核心数量的限制,公式改写为:
speedup=1P/N+(1−P)\text{speedup} = \frac{1}{P/N + (1-P)} \\
其中,P 是程序的并行率,N 是核心数,当 N→∞N\to\infty 时,该公式变成第一个公式。通过该公式,我们计算几种常见情况的组合:
由阿姆达尔定理引出一个著名的论断:”You can spend a lifetime getting 95% of your code to be parallel, and never achieve better than 20x speedup no matter how many processors you throw at it!”
对于并行计算有多种分类方法,最著名的有弗林分类法。另外从体系结构的角度,又分为指令级并行、数据级并行、线程级并行……下面简单介绍一下。
2.2.1 弗林分类法
计算机科学家弗林提出了一种区分并行计算的分类方法称为:弗林分类法(Flynns Taxonomy) 。他根据指令流(Instruction Stream)和数据流(Data Stream)两个维度区分不同的处理器:
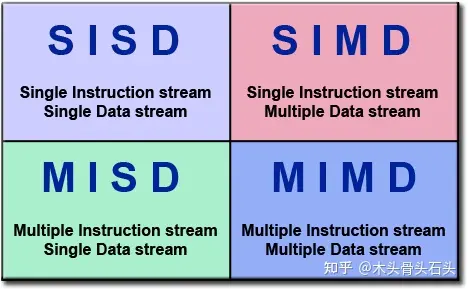
SISD(单指令流、单数据流处理器):在任何一个时钟周期,只有一条指令流被处理单元执行,一条数据流被处理单元处理。在这种处理器中,通常只有一个执行单元(Processing Unit,PU),属于串行处理器。
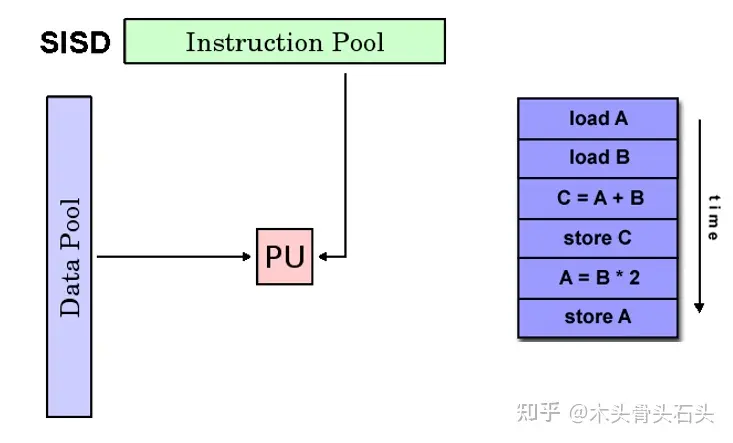
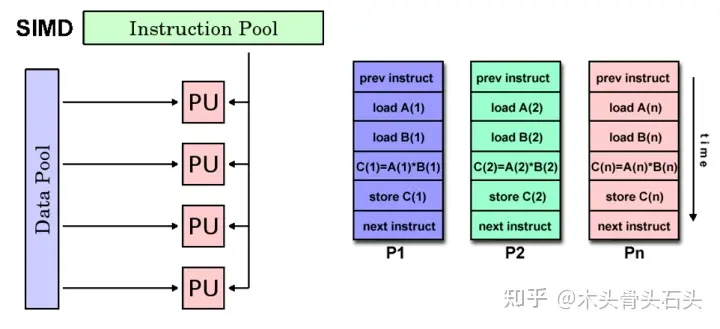
SIMD(单指令流、多数据流):在任何一个时钟周期,所有执行单元执行同一条指令,但每个执行单元输入的数据可以不同。在这种处理器适用于向量和矩阵运算,比如 GPU 就是一种 SIMD 处理器,属于并行处理器。
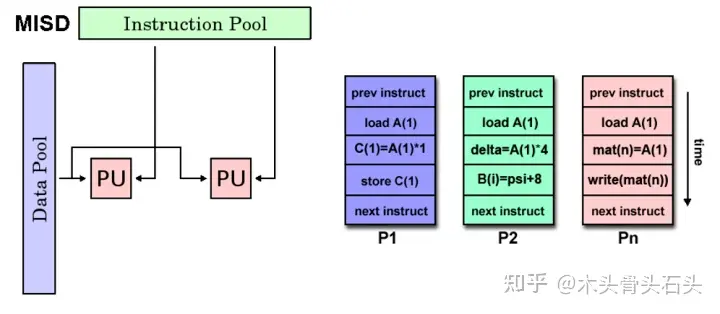
MISD(多指令流、单数据流):在同一个时钟周期,不同处理器单元执行不同的指令,但输入处理器单元的数据是相同。这种并行处理器并不常见。
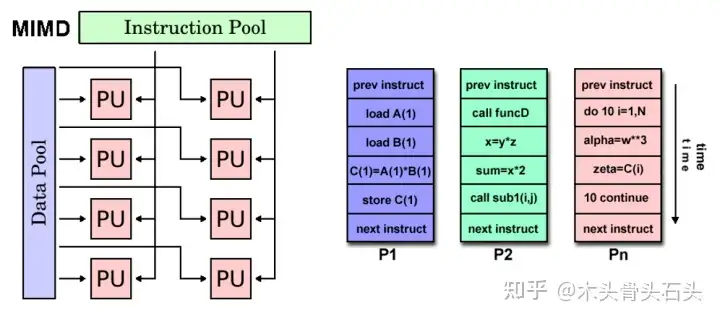
MIMD(多指令流、多数据流):在一个时钟周期,每个处理单元执行不同的指令流,处理不同的数据流。指令之间可以同步或异步执行,在如今的超级计算、分布式系统、个人电脑多核 CPU 都是基于 MIMD
2.2.2 指令级并行
CPU 指令集:指令集中会定义处理器可以执行的所有指令,高级语言编写的程序最终会被编译成一串指令。按照指令集的复杂程度,可以把 CPU 指令集分成两类:
复杂指令集计算机(Complex Instruction Set Computer,CISC)精简指令集计算机(Reduced Instruction Set Computer,RISC)在 CPU 中,指令都是按流水线的方式执行的,以提高 CPU 的使用率。
指令流水线(Instruction Pipeline):一条指令通常被分成若干个阶段交由处理器中不同单元执行,有分三步的,也有分六步的。按照 RISC-V 标准,指令流水线被划分成五个阶段:
指令获取(Instruction Fetch,IF):控制单元从程序计数器(Program Counter)寄存器中取出即将执行的指令的地址。当指令获取后,PC 寄存器的值会指向下一条指令的地址。指令获取所需的时钟周期取决于指令所在的存储器,因此我们要保证尽可能保证局部性原理指令解码(Instruction Decode,ID):指令解码器将获取到的指令解码成成控制CPU其他部分的信号。执行(Execute,EX):指令进入执行单元,如 ALU、FPU、LSU、AGU 中执行内存访问(Memory Access,MEM):访问内存,读写数据寄存器回写(Register Write Back,WB):将执行结果或内存读取结果写入到通用寄存器(GPR)中次标量处理器:一个单核 CPU 指令执行最简单的方式为,CPU 一个时钟周期只能执行一条指令的一个阶段,假设每个指令的每个阶段需要一个时钟周期,那么执行三条指令需要十五个时钟周期。

这种 CPU 平均一个时钟周期最多只有一条指令在执行(IPC < 1,Instructions Per Machine Circle),称为次标量处理器(Subscalar Processor)。其处理器资源利用率很低,假设某一指令的一个阶段消耗多于一个时钟周期,那么后面的阶段只有等待。
标量处理器:为了提高 CPU 资源利用率,一种最常见的方式是让 CPU 在一个时钟周期能执行多条指令的某一个阶段:
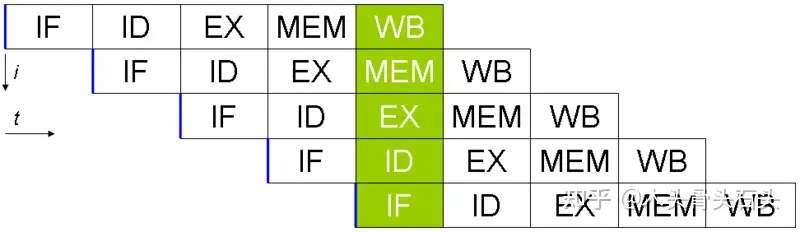
这种 CPU 平均一个时钟周期有一条指令在执行(IPC = 1),属于一种标量处理器(Scalar Processor)。这是一种最简单的指令级并行(Instruction-Level Parallelism,ILP)手段。指令流水线效率取决于程序指令的可并行性,当某一条指令依赖之前指令的执行结果时,将不能以流水线方式执行,还是会按照第一种方式执行,这种情况称为障碍(Hazard)。
超标量处理器:更进一步,在一个单核 CPU 中搭载多个执行单元(Execution Unit),比如多个 ALU、FPU、LSU 等。那么一个时钟周期可以将多条指令的一个阶段分发到不同功能单元上执行:
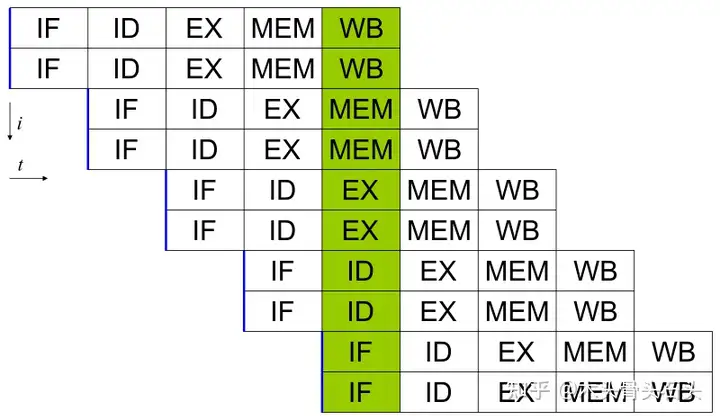
这处理器平均一个时钟周期有多条指令在执行(IPC > 1),属于一种 超标量处理器(Superscaler Processor) 。超标量处理器指令并行程度同样取决于程序指令的独立性。现代所有的通用 CPU 几乎都是超标量的。Superscaler Processor 同样要避免 Hazard。
并行障碍:因为指令之间的依赖性,后续指令需要等待前一指令结果的返回,这时需要改进硬件,处理障碍。下面介绍三种策略:1. 管线气泡;2. 操作数前移;3. 乱序执行
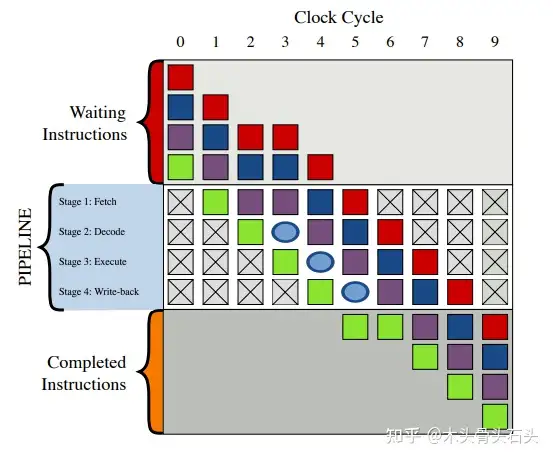
管线气泡(Pipeline Bubble):管线气泡是最简单的解决方案。在一条指令在解码阶段被识别需要依赖前面指令执行的结果时,会创建一个管线气泡占据解码阶段,使当前管线的解码阶段处于空闲等待状态,管线气泡对导致后续指令被延迟。如下图,紫色指令依赖于绿色指令将执行结果写会寄存器,在其解码阶段会创建一个指令气泡,在第 5 个时钟周期,绿色指令的结果写回寄存器,紫色指令从寄存器读取绿色指令执行的结果,进入执行单元执行,在第 6 个时钟周期,管线气泡被挤出指令管线。
操作数前移:当发生并行障碍时,后一条指令依赖前一条指令将执行结果回写到寄存器,再从寄存器读取结果才能执行。如果前一条指令在执行后需要内存访问,再写回寄存器,那么后续指令等待的时钟周期将不止一个。如果前一条指令能直接将执行结果直接传递给后一条指令,不经过寄存器,将大大减少等待的时间。操作数迁移技术需要改进硬件,使解码器能探测这种依赖性,并增加一条电路直接获取前一条指令的值。
乱序执行:乱序执行允许指令执行的顺序与程序编写时的顺序不一样,但执行结果依然正确。指令乱序执行的前提是,该指令所需的数据已经计算出来,而且它不依赖前一条(或多条)指令的结果,那么它可以先于前一条(或多条)指令执行。那么乱序执行的步骤为:
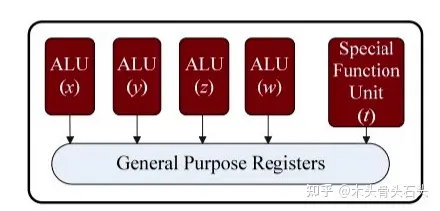
获取指令将指令分配到一个指令队列指令在指令队列中等待,直到其输入操作数可用,此时它可以早于自己前面指令被执行执行指令将指令输出结果保存在一个队列中只有当一个指令之前所有指令被执行完毕并将结果写回寄存器后,才将该指令的结果写回寄存器,以保证执行结果的顺序一致性超长指令字:不管是 Scalar Processor 还是 Superscalar Processor,都是通过增加硬件的复杂度,决定哪些指令能在一个时钟周期并行执行。另一种不增加硬件复杂度的前提下,依然能使多条指令在一个时钟周期同时执行的架构称为超长指令字(Very Long Instruction Word,VLIW) 。VLIW 是不同于 CISC 和 RISC 的第三种指令集架构,它将多个相互无依赖的指令由编译器打包成一条超长指令,交由 CPU 核心中对应数量的执行单元并行执行,指令级并行的发现和指令执行顺序的调度完全由编译器完成,处理器只负责指令的执行。AMD TeraScale 架构 GPU 的流处理器就是 VLIW 架构,一个 TeraScale 流处理有 5 个 ALU:
2.2.3 数据级并行
Scalar Processor 和 SuperScalar Processor 都是 SISD,也即单指令、单数据,适合标量运算。在数学领域,除了标量运算,还有向量运算。如果用 SISD 处理器执行一个四维向量的加法,它需要八个内存访问指令取出数据,四条加法指令,四条寄存器写回指令。
向量运算天然适合并行执行,四个分量的互相独立,SuperScalar Processor 因为有多个执行单元,四条加法指令可以在一个指令周期并行完成,勉强可以完成短向量的运算,但读写数据是串行的,是整个指令流水线的瓶颈。如果数据读写也能并行执行那将极大的加速向量运算,这种并行称为数据级并行(Data-Level Parrallelism,DLP) 。
向量处理器:在超标量处理器的基础上,为了支持任意维度的向量的运算,我们需要增加更多的执行单元,搭载更大容量的向量寄存器(Vector register),称为向量处理器(Vector Processer) 。向量处理器最大的不同是内存访问是流水线化,因此以同时读写多条数据,并将数据同时分发到不同的执行单元。Vector Processor 是一种 SIMD 处理器。那么上面的四维向量加法,只需要两条内存访问指令,一条向量加法指令和一条向量寄存器写回指令。对于长向量或者矩阵运算,一个处理器核心中不可能集成如此多的执行单元和寄存器,需要拆分成多条向量指令,因此向量处理器也支持向量指令流水线并行执行。
数据级并行对数据的局部性要求更高,因为 SIMD 处理器中的执行单元和内存访问单元都是并行执行,如果缓存缺失,会导致更多资源资源闲置。
2.2.4 线程级并行
不同线程之间指令几乎没有依赖关系,所以适合并行计算。在 SISD、SIMD 处理器上,平均一个时钟周期只能执行一条指令,因此在这些处理上,多道线程实际是并发执行的,真正的线程级并行(Thread-Level Parrallelism) 要求处理能同时执行来自多条线程的指令,这需要设计更复杂的电路。
同时多线程(Simultaneous Multithreading,SMT):在超标量处理器的基础上,搭载更多指令获取器和程序计数器,可以在一个时钟从多道线程中获取指令并行执行。同时 SMT 处理器有更多的寄存器,当一条线程被阻塞或挂起时,比如遇到内存访问指令,需要多个时钟周期才能返回结果,它就将该线程的上下文用寄存器保存下来,并从另一条线程取指令继续执行。当内存访问结果返回时,可以在一个时钟周期内从寄存器恢复被挂起的线程。SMT 技术使处理器保持忙碌,隐藏内存访问时延。
超标量处理器与 SMT 处理器的区别在于,超标量处理器只能从一个线程中取多道指令并行执行,而 SMT 处理器可以从不同线程中取多道指令并行执行。因此 SMT 处理器是一种 MIMD 处理器。Intel 的超线程技术(Hyper threading) 也是一种 SMT
还有一种多线程技术称为时分多线程(Temporal Multithreading,TMT),它一个时钟周期只允许来自一条线程的一个指令执行,同时它拥有更多的寄存器,方便保存线程上下文。从标量处理器到超标量处理器,再从超标量处理器到向量处理器,最后从向量处理器到多线程处理器。单核处理器的并行潜力被充分挖掘后,如果希望同时完成更多的任务,只有在一块芯片上集成更多的核心,也就是多核处理器。
多核处理器(Multi-Core Processor):多核处理器能在一个时钟周期,同时执行来自不同线程的指令,属于 MIMD 处理器。操作系统负责将用户线程分发到不同处理器核心上执行,处理器的核心数通常少于用户的线程数,因此多道线程依然是分时间片在单个核心上执行。
3 同步
同步(Synchronize):不管是并发还是并行,都要求多道线程可以不用按顺序执行。但当多道线程在对共享资源的访问出现依赖时,需要限制它们对共享资源访问的权限,协调它们执行的先后顺序。这就是同步(Synchronization)。同步会使并发或并行的线程串行执行,会降低计算机利用率和吞吐量,因此并发或并行算法研究的重点,就是减少同步。
多道线程在并发或并行执行时,可能会出现两种制约关系,当出现这种依赖关系时需要同步:
直接制约关系:多条线程的执行有明确的先后顺序,通常是前一条线程产生的结果是后一条线程的输入,这里的共享资源有明确的“流向”。这种制约关系称为直接制约关系,或者协作关系。多道线程对共享资源的访问是同步的,如果不控制线程的执行顺序,则可能导致后一条作业先执行而无数据输入导致程序错误。间接制约关系:多条线程的某一代码区域不能同时执行,称为临界区(Critical Section)。临界区代码的特点是会修改共享资源,或者共享资源只有一个,称这种资源为临界区资源,比如多线程共享的数据库表或者多进程共享的一台打印机。这种制约关系称为间接制约关系,或者竞争关系。多道线程对临界区资源的访问是互斥的,如果不限制访问的权限,资源访问的顺序是不可预测的,这种情况称为 Race Condition。计算机科学家根据两种制约关系,提出了若干经典同步问题:
生产者消费者问题(Producer–consumer problem):假设有一个生产进程和一个消费进程共享一个固定大小的缓冲区。生产者将消息放入缓冲区中,当缓冲区满时生产者必须等待;消费者从缓冲区取出消息,如果缓冲区为空消费者必须等待。读者写者问题(Reader-writers problem):假设有一组读者线程和一组写者线程共享一个文件,当两个或以上的读者进程同时访问共享文件时不会产生错误,但如果某个写进程和其他线程(读进程或写进程)同时访问共享数据则可能导致数据不一致的错误。餐桌上的哲学家问题(Dining philosophers problem):假设餐桌上有五位哲学家,每两位哲学家之间摆一根叉子。当哲学家需要进餐时,需要先后拿起左右手边的叉子,当一个叉子被另一个哲学家使用时需要等待。当进餐完后会放下两手的叉子。吸烟者问题(Cigarette smokers problem):有三个抽烟者进程和一个供应者进程。每个抽烟者不停地卷烟并抽掉它,但是要卷起并抽掉一支烟,抽烟者需要有三种材料:烟草、纸和胶水。三个抽烟者中,第一个拥有烟草、第二个拥有纸,第三个拥有胶水。供应者进程无限地提供三种材料, 供应者每次将两种材料放到桌子上,拥有剩下那种材料的抽烟者卷一根烟并抽掉它,并给供应者一个信号告诉完成了,供应者就会放另外两种材料在桌上,这种过程一直重复(让三个抽烟者轮流地抽烟)。下面介绍几种常见的同步机制可以解决这些同步问题,具体实现在 wiki 上有,这里就不摘抄了。所有的同步技术都有一个共同点:它们通常需要一个共享数据用于在多个线程之间通信,线程可以用该数据判断自身是否满足某一条件,如果满足条件则继续执行,如果不满足条件则需要等待。
另外,所有的同步技术都依赖原子操作(Atomic Operation)。原子操作指不会被作业调度系统打断的操作,这种操作一旦开始就一直运行到结束,在执行过程中不会发生上下文切换。并发的同步大多可以在应用层面实现,而并行的同步需要硬件支持。在使用同步技术解决同步问题的时候,需要避免如下问题:
死锁(Deadlock)饥饿(Starvation)优先级反转(Priority Inversion)忙等待(Busy Waiting)3.1 并发的同步
3.1.1 自旋锁
自旋锁(Spinlock)是一种非常简单的同步机制,用于满足间接制约关系。下面先介绍一种用于并发同步的自旋锁实现。它有一个共享变量 isLock ,以及两个原子操作 Lock() 和 Unlock():
下面使用自旋锁实现两个线程的间接约束:
从上面的代码中可以看到,所谓的“自旋”就是 Lock 操作中有一个死循环。这个死循环用于当有线程在临界区时阻塞该线程,同时不断轮询是否解锁。这种等待称为忙等待(Busy Waiting) ,忙等待会浪费 CPU 时间执行一个什么也不做的死循环,因此自旋锁只适合阻塞时间不长的操作。
这里的自旋锁的实现会造成 饥饿(Starvation) 问题。当多条线程等待临界区线程退出临界区时,下一条进入临界区的线程无法预测,这可能会使得某一条线程一直无法执行。为了解决这一问题,可以对所有在等待的线程按照优先级进行排序,选择优先级最高的线程进入临界区3.1.2 信号量
信号量(Semaphore):常用于限制同时执行的线程数。其为维护一个整形计数,其取值范围是 0 到用户设置的最大值 MAX。只有两个原子操作 Wait() 和 Signal() 可以改变信号量的值,也称为 P 操作和 V 操作。当有一个线程调用 Wait 时,信号量计数减一,当计数为 0 时阻塞线程;当有一个线程调用 Signal 时,信号量加一,且不能超过最大值。用忙等待实现 Wait 和 Signal:
通过信号量可以实现直接约束与间接约束。Task1() 与 Task2() 协作完成一项任务,将信号量初始化为 0,Task1() 的 x 语句需要先于 Task2() 的 y 语句执行:
使用信号量完成 Task1() 与 Task2() 的间接约束,信号量初始化为 1,并且将 MAX_SEMAPHORE 设为 1:
当 MAX_SEMAPHORE 设为 1 时,信号量只能取 0 和 1 两个值,称为二分信号量(Binary Semaphore),或者互斥量(Mutex)。用忙等待实现的二分信号量与自旋锁无本质区别。另外 Wait 的阻塞可以不用忙等待实现,比如将线程挂起,使长时间的阻塞不会带来额外的开销。
3.1.3 屏障
屏障(Barrier):在一组线程的代码中设置一个屏障点,当所有线程都执行到屏障点时,这组线程才继续向后执行。屏障属于一种更为高级的同步技术,它需要通过自旋锁或者信号量实现。设置屏障点时,需要指定需要为多少条线程设置屏障点。另外屏障内部维护两个共享数据,一是 arrive_counter 统计抵达屏障点的线程数,二是 leave_counter 统计离开屏障点的线程数。多道线程对这两个数据的访问是互斥的,那么参考 Wiki 的实现,屏障技术用代码表示为:
使用屏障同步 4 条线程:
3.2 并行的同步
上面介绍的并发同步在应用层面就可以实现,但多线程并行执行,上面的同步算法会出现问题。因为并行是真正意义上的多条线程同时执行,以自旋锁为例,可能同时会有多道线程同时执行 Lock 操作,使间接约束失效。因此多线程并行的同步还需要硬件的支持。
下面参考:Parallel Programming and Synchronization
3.2.1 TAS 指令
TAS 指令:全称 test-and-set 指令。其用于向一个内存地址写入 1 并返回它的旧值,用伪代码表示为:
该指令是一个原子操作,用硬件实现该指令可以用于并行同步。当一个处理器执行 TAS 指令时,在该处理器完成指令之前,其他处理器不能向同一个地址执行 TAS 指令。利用 TAS 指令,实现间接约束:
3.2.2 CAS 指令
CAS 指令:全称 Compare and swap 指令。在向给定地址写入数据时,会比较地址中的数据与旧值是否相同,如果相同则写入新值。如果不同,意味着旧值在这一期间被修改过,那么写入失败。是用伪代码表示为:
该指令是一个原子操作,硬件实现该指令可以用于并行同步。CAS 指令的一大问题是 ABA 问题,也即旧值从 A 变成 B 再变成 A,这样会看不出变化,解决方式会给每次修改加一个版本号。或者使用 LL/SC 指令对。
3.2.3 LL/SC 指令
LL/SC 指令 :全称 Load-link/store conditional ,这是一对用于并行同步的指令。LL 返回内存地址中的值;SC 将一个值存入该地址,如果自上次 LL 到这次 SC 发生之间,该地址的值发生变化,则 SC 写入失败。可以看到 LL/SC 指令对与 CAS 指令很相似,但是 LL/SC 指令对可以不用版本号就解决 ABA 问题。通过 LL/SC 指令对实现自旋锁:
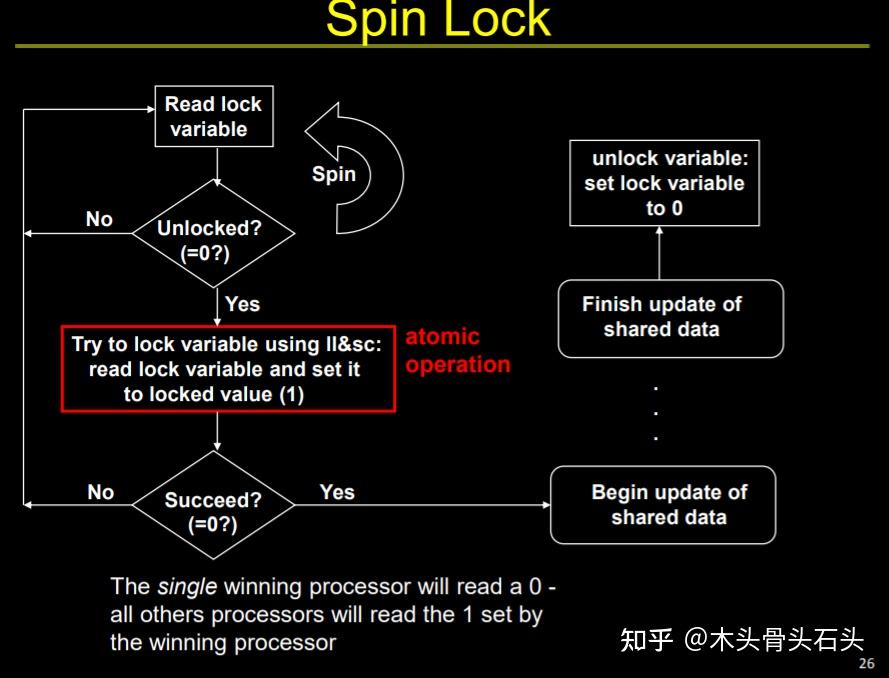

3.3 死锁
死锁(Deadlock):当多道线程出现复杂依赖(比如循环依赖),在解决它们的同步时会出现死锁。死锁会导致有的线程无限等待下去。死锁发生会有如下四个必要条件。当这四个条件同时满足时,就会发生死锁:
互斥:多道线程对共享资源的访问是互斥的,也即当一个线程占有资源后,其他线程只能等待不可剥夺:线程占有资源后,在其使用完之前不能被其他线程剥夺占有权占有并等待:当线程占有一个资源后,有请求新的资源,而改资源又被其他线程占有循环等待:存在一个线程资源的循环等待链资源分配图:为了更精确地描述死锁问题,计算机科学家提出用资源分配图来描述线程之间的依赖关系。下图中,圆圈表示进程或线程。方块表示某一类资源,方块中的圆圈数表示该种资源的数量。箭头表示进程或线程申请或占有的资源,指向进程或线程的箭头表示对资源的占有,称为分配边;指向资源的箭头表示对资源的请求,称为请求边。
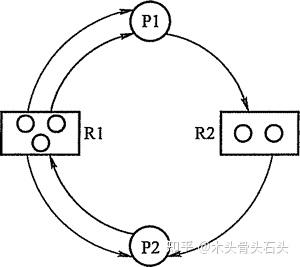
资源分配图是一个有向图,当图中没有出现“环”时,则系统不发生死锁;如果图中出现“环”,则可能发生死锁。如果每种资源只有一个实例,出现“环”,必然出现死锁,此时“环”就是死锁存在的充要条件。
明白死锁产生的原因,下面介绍解决死锁问题。通常有三种策略:
死锁预防(Deadlock prevention):设置某些限制条件,破坏产生死锁的四个必要条件中的一个或多个,从而预防死锁死锁避免(Deadlock avoidance):在资源的分配过程中,用某种方法避免系统进入不安全状态,从而避免死锁。最常用的死锁避免算法是银行家算法(Bankers algorithm)。死锁的检测与解除:允许死锁发生,通过某种机制检测出发生死锁的线程(也即检测资源分配图中的环),并采取某种解除死锁的措施(剥夺线程对资源的占有,从而破坏“环”)死锁预防是非常保守的死锁解决策略,实现简单但资源利用率低。死锁避免和死锁预防类似,都是在资源分配时设置某种限制,从而让死锁不发生。死锁避免时避免系统进入不安全状态。并非所有的不安全状态都是死锁状态,但当系统进入不安全状态后,便可能进入死锁状态;反之,只要系统处于安全状态,系统便可以避免进入死锁状态。现代操作系统通常通过死锁检测与解除解决死锁问题,死锁检测的开销是很大的,通常不会很频繁。
4 用户线程的创建与管理
创建用户线程,需要在程序中调用操作系统提供线程库函数,不同的操作系统的线程库会有所不同。跨平台编程语言在解释器这一层封装不同平台的线程库,在语言层面直接提供多线程接口,使开发者更专注于应用的开发,不用兼顾平台特性。
4.1 POSIX Thread
POSIX Threads 也即 pthreads,是 IEEE 制定的线程库接口标准,在许多 Unix-like 操作系统上得到实现,比如 FreeBSD、Linux、macOS、Android…… 使用 pthreads 提供的 API 函数,我们可以在这些操作系统上创建和管理用户线程。POSIX Threads 标准库函数是用 C 语言定义,以 pthread_ 前缀开头,在程序中包含 pthread.h 头文件使用线程库。下面参考 Oracle Solaris 的 pthread 教程:Multithreaded Programming Guide 。
4.1.1 线程的创建与回收
线程是一种系统资源,会占用一段内存,在创建的线程执行完毕后,需要回收该线程,不然会造成内存泄漏。线程的创建与回收详见 Solaris 官方文档:The Pthreads Library
调用 pthread_create 函数创建一条线程:
如果创建成功,返回一个 pthread_t 线程句柄。在创建时,传入一个函数指针 start_routine 作为线程的入口函数,arg 表示入口函数的参数。attr 表示创建线程时的属性,是一个可选参数。与线程属性相关的函数都有前缀 pthread_attr_ ,详见 Solaris 官方文档:Thread Attributes
线程的回收有两种方式:合并与分离。默认创建出来的线程是 joinable 的,调用 pthread_join 函数手动回收,该函数义如下:
调用该函数会阻塞当前进程或线程,直到参数 thread 指定的线程执行完毕,同时回收 thread 线程,status 参数接受 thread 线程的返回值。pthread_detach 函数自动回收线程,其定义如下:
调用该函数,线程会自动变成 detached 属性,意味着将线程回收工作交由系统完成,当 thread 线程执行完毕后,系统会自动回收该线程,但这也意味着我们无法获得分离线程的返回值。
下面是一个多线程的例子:
上面的程序输出:
4.1.2 线程的同步
pthread 提供了多种线程的同步机制,详见 Solaris 官方文档:Programming with Synchronization Objects 。一共有五种同步机制:
互斥量,相关函数与结构体有 pthread_mutex_ 前缀自旋锁,相关函数与结构体有 pthread_spin_ 前缀条件变量,相关函数与结构体有 pthread_cond_ 前缀读者写者锁,相关函数与结构体有 pthread_rwlock_ 前缀屏障,相关函数与结构体有 pthread_barrier_ 前缀互斥量的使用非常简单:
自旋锁的作用和互斥锁的很像,区别在于互斥量在阻塞线程时,是通过线程休眠阻塞;而自旋锁是通过忙等待阻塞线程。因此互斥量适用于长时间阻塞线程,而自旋锁适用于短时间阻塞线程
条件变量类似于信号量,其使用方式与互斥量、自旋锁稍有不同。条件变量的作用是,当线程满足某一条件时才继续执行,当不满足这一条件时等待。使用下面两个函数创建与销毁一个条件变量
条件变量同步机制在不满足条件时,阻塞线程。而条件检测需要互斥量的参与,因此 wait 函数的参数中需要传入一个互斥量句柄。
在一条线程中需要设置条件,解除等待线程的阻塞状态,设置条件时需要通知等待线程。这有两种通知方式:单播和广播:
读者-写者锁专门用于读者-写者问题,在 pthread 中定义了如下函数:
屏障用于阻塞线程直到其他多个任务完成后才继续执行的情况。
4.2 Windows Threads
Windows API 提供了多进程、多线程接口,需要引入 windows.h 头文件。在 Windows API 中,还有一个纤程(Fiber)的概念,也就是协程,这里就不多介绍了。详见 Microsoft 官方文档:
Processes and ThreadsSynchronizationWindows 平台也可以使用 pthreads,不过 Windows 没有提供原生的实现,可以使用第三方库 Pthreads4w ,用 Windows 多线程 API 实现 pthreads 接口,这样便于将 pthreads 编写的多线程程序移植到 Windows 平台下。4.2.1 创建线程
在 Windows 平台中,调用 CreateThread 创建线程
如果创建成功,则返回该线程的句柄。如果线程使用完毕,调用 CloseHandle 关闭线程句柄。在关闭线程句柄前,需要阻塞父进程或线程,等待所有的线程执行完毕。等待函数有:
这两个函数还用于线程同步,在某一(些)条件未满足前,这两个函数都不会 return。下面是一个 Windows 多线程的例子:
线程池(Thread pool) 可以认为是一种设计模式,因为线程是一种资源,频繁的创建销毁会影响性能。winthread API 提供了线程池接口便于开发者使用,详见:Using the Thread Pool Functions 。
在 pthread 没有提供该线程池接口,需要开发者自己实现4.2.2 线程的同步
Windows API 提供的同步机制包含两部分,一是同步对象(Synchronization Objects) ;二是等待函数(Wait Functions) 。它们既用于进程同步,也用于线程同步。同步对象有两个状态:signaled 或 nonsignaled,等待函数用于阻塞线程,直到某一个同步对象从 nonsignaled 设为 signaled 。通过同步对象与等待函数,可以实现多种同步算法。
4.2.2.1 同步对象
事件对象(Event Object):用于向一个线程发送信号,通知它某一个事件发生了。关于事件对象的使用,详见官方实例:Using Event Objects (Synchronization)
调用 CreateEvent 函数创建一个事件对象,创建成功返回该对象的句柄,初始状态为 nonsignaled。线程中调用等待函数 WaitForSingleObject ,阻塞线程,直到事件对象被设置为 signaled 状态线程中调用 SetEvent 函数将一个事件对象设置为 signaled 状态,调用 ResetEvent 可以将一个事件对象重置为 nonsignaled。使用完毕调用 CloseHandle 销毁事件对象互斥对象(Mutex Object):当其不属于任何线程时,它的状态才会被设为 signaled 。当任一线程占有它时,它的状态会被设为 nonsignaled。任何时刻只有一个线程可以占有互斥对象。关于互斥对象的使用,详见官方实例:Using Mutex Objects (Synchronization)
调用 CreateMutex 函数创建一个互斥对象,创建成功返回该对象的句柄,初始状态为 signaled 线程中调用等待函数 WaitForSingleObject ,阻塞线程,直到互斥对象被设置为 signaled 状态,该线程就占有互斥对象,互斥对象的状态变为 nonsignaled线程中调用 ReleaseMutex 函数,结束对互斥对象的占有,互斥对象的状态设为 signaled 使用完毕调用 CloseHandle 销毁互斥对象信号量对象(Semaphore Object):信号量对象会维护一个计数,其范围是从 0 到指定最大值。其作用是限制可以执行某操作的线程数。关于信号量对象的使用,详见官方实例:Using Semaphore Objects (Synchronization)
调用 CreateSemaphore 创建信号量对象,指定计数的初始值和最大值线程中调用等待函数 WaitForSingleObject ,阻塞线程,信号量的计数将减一,当计数减为 0 时阻塞线程线程中调用 ReleaseSemaphore 函数,信号量的计数将加一,另一条处于等待状态的线程将会激活使用完毕调用 CloseHandle 销毁信号量对象当信号量的计数最大值设为 1 时,信号量对象等价于互斥量等待计时对象(Waitable Timer Object):等待计时对象会在预定一段时间后切换为 signaled 状态,关于等待计时对象的使用,详见官方实例:Using Waitable Timer Objects (Synchronization)
调用 CreateWaitableTimer 创建信号量对象,调用 SetWaitableTimer 函数设定倒计时长线程中调用等待函数 WaitForSingleObject ,阻塞线程,直到等待计时对象被设置为 signaled 状态使用完毕调用 CloseHandle 销毁互斥对象4.2.2.2 其他同步对象
Windows API 还提供了如下两种同步机制,这两种方法仅能用于线程同步
临界区对象(Critical Section Objects):临界区对象的作用与互斥对象很相似,但互斥量对象可以用于进程间的同步,但临界区对象只能用于某一进程中多线程间的同步,且更加高效。关于等待计时对象的使用,详见官方实例:Using Critical Section Objects
定义一个临界区类型 CRITICAL_SECTION 的变量,调用 InitializeCriticalSectionAndSpinCount 初始化临界区线程调用 EnterCriticalSection 进入临界区线程调用 LeaveCriticalSection 退出临界区使用完毕调用 DeleteCriticalSection 删除临界区变量条件变量(Condition Variables):可以使线程等待直到某一条件发生,条件变量常用于生产者消费者问题或读者写者问题。关于条件变量的使用,详见官方实例:Using Condition Variables
定义一个条件变量类型 CONDITION_VARIABLE 的变量,调用 InitializeConditionVariable 初始化条件变量在线程中调用 SleepConditionVariableCS 函数使该线程等待,直到另一个线程调用 WakeConditionVariable 函数4.3 C# 多线程
C#、Java、Python 等跨平台编程语言,都封装了操作系统原生的线程库函数,作为语言特性的一部分供开发者使用,详见官方文档:Managed threading。下面介绍 C# 的多线程相关特性,相关类与结构体都包含在 System.Threading 命名空间中。C# 还提供了一系列线程安全容器用于多线程并发访问,这些容器定义在 System.Collections.Concurrent 命名空间中,不需要开发者同步。
4.3.1 创建线程
在 C# 中,实例化一个 System.Threading.Thread 类的对象即可创建一个线程,构造函数中传入一个 ThreadStart 或 ParameterizedThreadStart 类型的委托,表示线程的入口函数。该类的成员方法用于管理线程:
调用 Thread.Start() 启动线程调用 Thread.Join 可以阻塞父线程直到该线程执行完毕调用 Thread.Sleep 可以休眠该线程一段实现调用 Thread.Abort() 强制终止一条线程,并抛出一个 ThreadAbortException 给父线程,通常不调用该方法线程池:C# 也提供了对线程池的封装,调用 System.Threading.ThreadPool 其中的静态函数可以轻松使用线程池。
4.3.2 线程同步
C# 提供了 System.Threading.WaitHandle 类,其中封装了原生的操作系统同步句柄,并且使用 Signaling 机制在线程之间通信。开发者可以继承该类,实现自己的同步算法。同时 C# 提供了如下类方便开发者完成常见的同步任务,它们都继承自 WaitHandle:
System.Threading.Mutex :互斥量,当所有线程都不占有互斥量时,为 signaled 状态System.Threading.Semaphore :信号量,当它计数大于 0 时,为 signaled 状态,当计数等于 0 时,为 nonsignaled 状态System.Threading.EventWaitHandle:需要在线程中手动设置其为 signaled 状态或 nonsignaled 状态System.Threading.WaitHandle 类实现自 IDispose,其子类需要重写 Dispose 函数手动释放。
除了 WaitHanle 及其子类,C# 还提供了 Barrier 、SpinLock 、SpinWait 等同步方式。与 winthreads 的同名用法相同。
4.4 C++11 多线程
C++11 标准首次引入了 <thread> 库,它抽象了不同平台创建和管理用户线程的操作,使开发者能使用 C++ 编写跨平台的多线程代码。
4.4.1 创建线程
创建一个 std::thread 类型的对象表示一条用户线程,构造函数中传入一个可调用类型(函数指针、Lambda 表达式)表示线程的入口函数。thread::join 和 thread::detach 表示两种合并到主线程的方式:
4.4.2 线程同步
C++11 定义了互斥量和条件变量两种同步机制,C++20 定义了信号量。
互斥量:创建一个共享的 std::mutex 用于线程间的间接约束,通过其成员函数 mutex::lock、mutex::unlock,我们可以定义线程中的临界区
另外,C++11 还提供了操作互斥量的类,std::lock_guard ,它利用 RAII 特性,在构造函数中调用 mutex::lock ,在析构函数中调用 mutex::unlock,这样避免了线程在锁定期间发生了异常无法解锁的情况:
条件变量:创建一个共享的 std::condition_variable 用于线程间的直接约束,一个线程等待另一个线程通知它某一条件达成,它可以继续往后执行
信号量:分别用 counting_semaphore 和 std::binary_semaphore 表示计数信号量和二分信号量,用于限制同时执行的线程数。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:多线程程序理解-多线程的用处 https://www.yhzz.com.cn/a/2264.html