 来源:小马智行第二场技术沙龙
来源:小马智行第二场技术沙龙
今天我主要想分享自动驾驶感知技术在探索的过程中,采用的传统方法和深度学习方法。传统方法不代表多传统,深度学习也不代表多深度。它们有各自的优点,也都能解决各自的问题,最终希望将其结合起来,发挥所有方法的优点。
一、感知系统简介
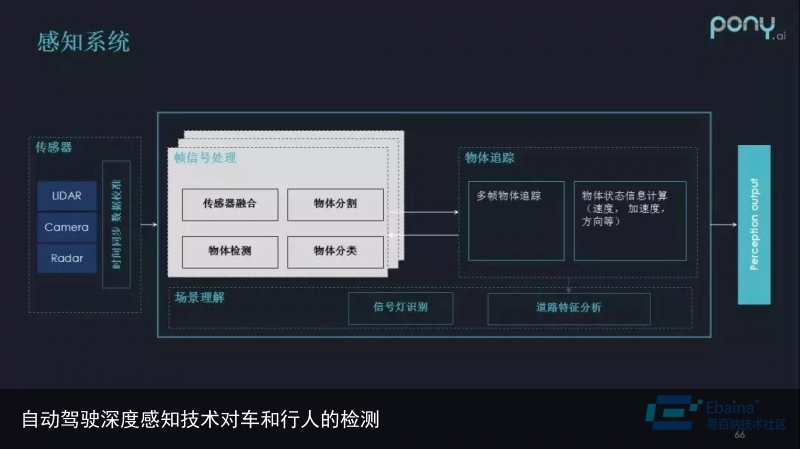
首先介绍下感知系统。感知可以被看作是对周围世界建模的过程,比如车辆在行驶过程中,需要知道其他物体的地理位置、速度、运动方向、加速度等各种各样的信息,自动驾驶系统接收这些信息之后,再通过后续的规划和控制模块来对车的运动做真正的调节。
感知可以类比为人类眼睛的功能,即观察周围世界的能力:
◆ 采用的传感器:激光雷达、照相机、毫米波雷达等。
◆ 帧信号处理:多传感器深度融合、物体分割、物体检测、物体分类。
◆ 物体追踪:当有多帧信息之后,可以推算速度、加速度、方向等更有意义的信息,甚至可以用多帧的信息调整物体分割的结果。
◆ 道路特征分析:对道路特征进行理解,比如交通信号灯、交通指示牌等。
感知可以认为是自动驾驶系统的基础部分,假如感知不到这个世界,就谈不上对这个世界做出反应,更谈不上后续的路径规划和车辆控制的过程。
二、2D物体检测
我今天主要介绍关于物体检测部分,因为必须先有了准确的物体检测和分割结果,我们才能对物体做出准确的分类、追踪等。我首先介绍下2D物体检测。

2D物体检测是指以2D信息作为输入(input)的检测过程,而典型的2D输入信息来自于照相机。
传统2D物体检测方法及缺点
传统的 2D 信息检测方法是使用检测框遍历图片,把对应的图片位置抠出来之后,进行特征提取,用 Harris计算子检测角点信息,Canny计算子检测边缘信息等。物体特征被提取并聚集在一起后,通过做分类器(比如SVM),我们可以判断提取的图中是否存在物体,以及物体的类别是什么。
但传统 2D 物体检测方法存在不足:
1.检测物体时,需要预置检测框,对不同物体需要设置不同的检测框。
2.自动驾驶需要高级的组合特征,而传统方法提取的特征维度比较低,对后续的分类会造成比较大的影响。基于深度学习的2D物体检测
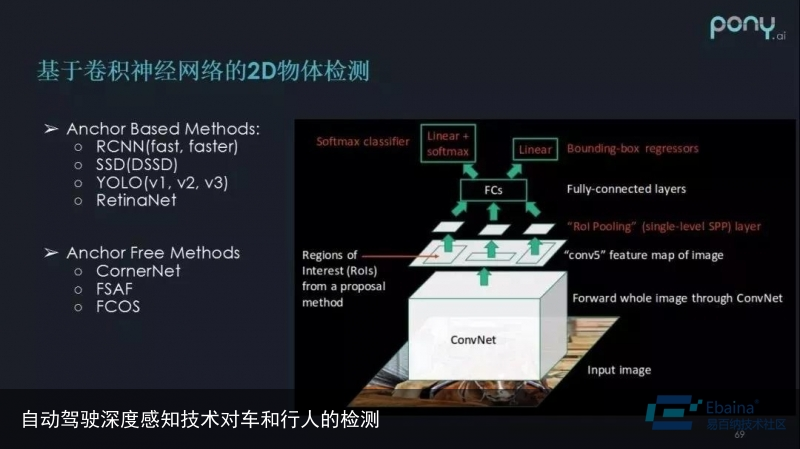
卷积神经网络的出现,解决了部分传统2D物体检测方法的不足。
卷积神经网络首先是多层感知机加卷积操作的结合,它的特征提取能力非常不错。因为卷积神经网络经常会有几十、上百个卷积,使其具备高维特征提取能力。
其次,通过 ROI pooling和RPN,整张图可以共享同样的特征,物体检测时不用遍历整张图片,还可以在单次操作中对图片中所有物体进行检测。这种检测方法使物体检测模型真正具备了应用于实际场景中的性能。
目前基于卷积神经网络的2D物体检测有两类分支:
◆ Anchor Based Methods
:跟传统方法比较类似,先预置检测框,检测过程则是对预设框的拟合过程。
1.RCNN(fast,faster)
2.SSD(DSSD)
3.YOLO(v1,v2,v3)
4.RetinaNET◆ Anchor Free Methods
:直接对照特征金字塔的每个位置,回归对应位置上,判断物体是否存在、它的大小是多少等。这类方法是2018年底开始大量出现的,也是未来的一个发展方向。
1.CornerNet
2.FSAF
3.FCOS
这是路测场景中的一个真实检测案例(上图),2D 物体检测已经应用于检测路面上一些小物体。
同时远距离物体检测也是2D物体检测中关注的重点。受限于激光雷达和毫米波雷达的物理特征,远距离物体缺乏良好的检测效果,而照相机在这方面比较有优势,可以和其他的检测方法进行互补。
2D物体检测面临的问题
一、物体相互遮挡

但是采用照相机做 2D 物体检测不可避免要面临一些问题。因为照相机回馈的图像只有两个维度,当两个物体堆叠时,对一个神经网络而言,图像的特征就比较聚集。
一般做物体检测的过程,会用一些非极大值抑制的方法,对检测结果进行后处理,当特征结果非常密集的时候,这种方法往往会受到影响。
二、成像质量波动
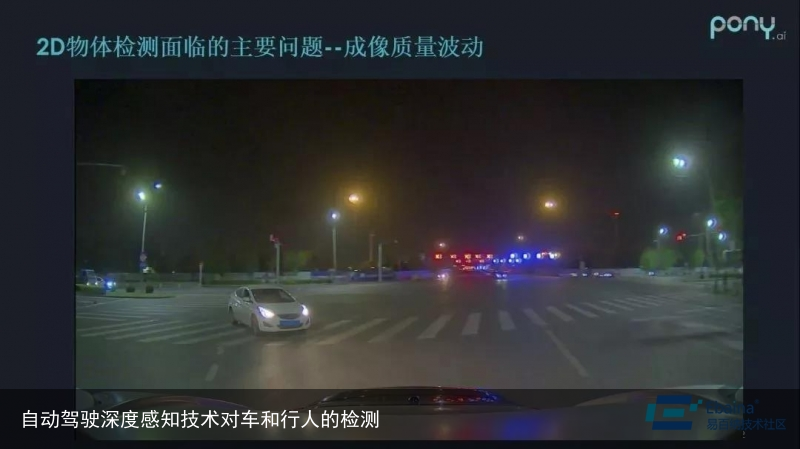
照相机是可见光设备,因此会受到光照强度的影响,成像质量出现波动。但我们总是希望图中的特征不管是在哪个位置,都能得到足够的表达。
例如,2D图像中远处的车灯和路灯很难区分开,导致可能都被检测为车或者路灯。在这种情况下,特征总会难以区分。
三、测距
另一个的问题就是测距问题。因为照相机是被动光源的设备,它不具备主动测距的能力。
如果希望借助照相机进行物体测距,就需要做很多的假设或者求解一些病态的数学问题,用以估算车与物体的距离。但这个结果通常不如主动测距设备的结果,比如激光雷达和毫米波雷达。
三、3D物体检测
正是因为照相机存在上面提到的问题,所以我们物体检测也使用了其他的传感器,将它们的结果共同结合起来,最终达到更可靠的检测效果。
什么是3D物体检测?

3D物体检测,顾名思义就是把3D的一些数据坐标,聚集起来进行物体检测。比如激光雷达,类似于我们拿一支激光笔不断扫描周围,它会提供相对明显的信息。当把3D数据聚集起来之后,我们可以用来推测周围物体的位置,大小,朝向等等。
3D物体检测一个很大的好处就是,我们在2D物体检测中很难区分的物体,有了3D数据提供的距离信息之后,将更容易从距离的维度上分开。这样感知系统在进行物体分割的时候能使用的信息更多,达到一个更好的工作效果。
传统3D分割方法及限制
传统的 3D 分割方法包括:
1.Flood Fill
2.DB scan
3.Graph Cut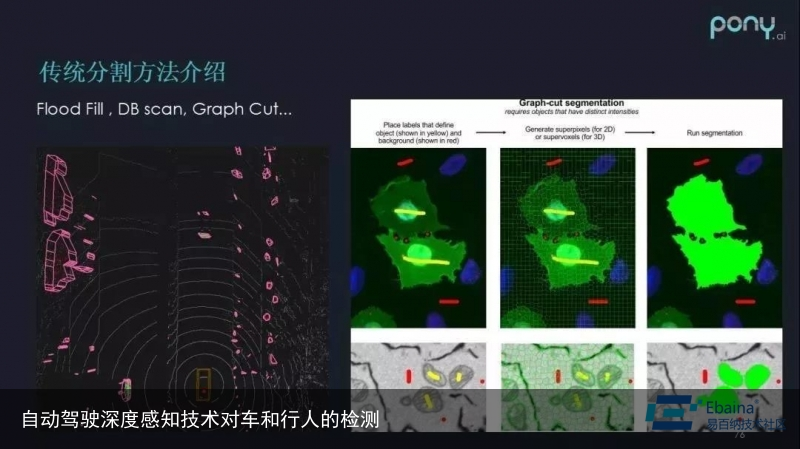 它主要是利用一些点的距离信息、密度信息或者点的一些天然属性,比如它的强度,把物体聚类分割。
它主要是利用一些点的距离信息、密度信息或者点的一些天然属性,比如它的强度,把物体聚类分割。
传统分割方法也存在不少限制,首先是过度分割。
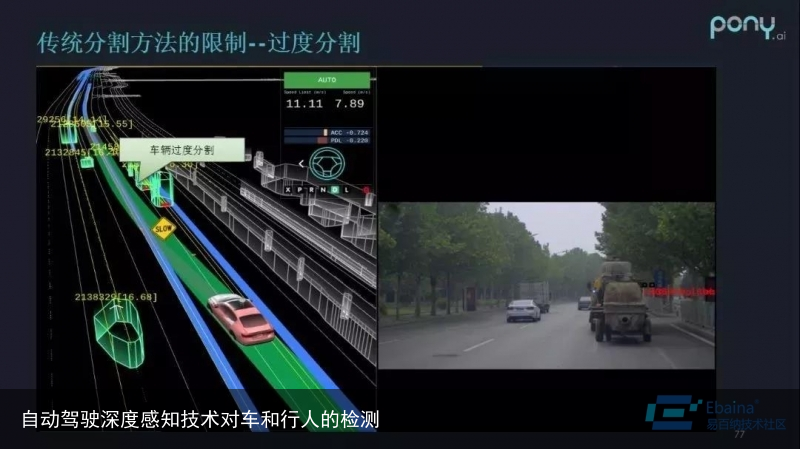
比如上图中的异形车,由于车尾和车头之间有缝隙,在 3D 检测中,它可能会被分割成多个物体,因为点和点之间有间隙,在激光雷达检测时呈现的是离散信息,就会出现过度分割。
传统分割方法的另一个问题是分割不足。

我们将上图出现的情况称为“三人成车”,就是当三个人离的很近的时候,有可能被传统分割方法识别成一辆车。
基于深度学习的3D分割方法
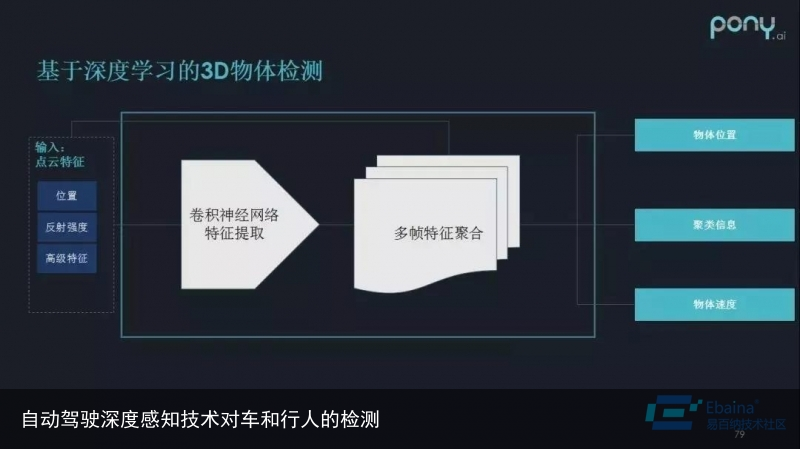
当深度学习与卷积神经网络引入到 3D 物体检测中时,我们发现传统3D分割方法遇到的问题得到较好解决。
首先让点云信息进行特征工程,即将点的位置、反射强度、高级特征聚合在一起,组织成类似图片或者图的关系。随后进行卷积神经网络特征提取,再进行多帧特征的聚合(它的意义是对运动的物体有一个更好的反映),最后输出物体的位置、聚类信息、物体速度。
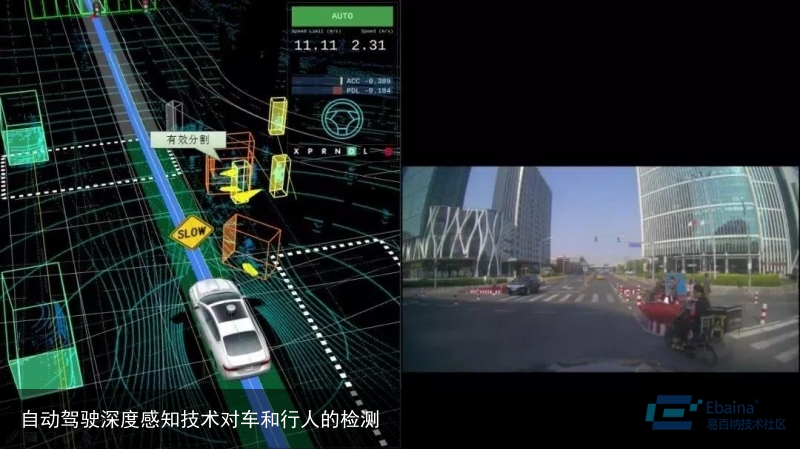
通过上述深度学习方法,“三人成车”的情况得到避免。系统不仅可以提取人的距离关系,还可以提取到更多的高级信息,比如在点云变化中,人类的点云形似长的柱体,而自行车类似于小山一样的点云分布,这样感知系统可以了解这些障碍物不属于同一物体,而将其割离开。
深度学习3D分割方法的限制
另一方面,我们也要认识到深度学习分割方法也可能面对的挑战。

◆ 结果的不完全可控:首先卷积神经网络经常有几百层的卷积层,参数总量可能有百万级,并且是自动学习的,这可能会导致对网络的输出缺少把控。换句话说,系统无法预期数据输入(input)后会得到怎样的数据输出,于自动驾驶而言,这是比较致命的。因为自动驾驶对场景的召回率和精度有非常高要求,如果车辆在行驶中,前面的一位行人miss(丢失),这是极其严重的隐患。
◆ 无法保证100%的召回(recall):如上图所示,垃圾桶和行人的特征其实非常相似,那么深度学习可能会出现把人学成了垃圾桶,最后导致行人在感知系统中出现丢失的情况。
◆ 易导致过拟合:由于卷积神经网络有非常好的特征提取能力,固定的数据集训练可能导致神经网络过拟合。例如同样的数据集训练后,在北京路测的表现很好,但是当到达一个新的城市进行测试时,因为路面特征和北京有所区别,可能导致物体分割效果下降,这对感知系统非常不友好。
优点兼得:传统方法和深度学习方法的结合
为了解决分割方法的限制,我们的想法是将传统方法和深度学习方法的结果进行结合:
◆ 使用深度学习的分割结果调整传统分割方法的结果。
◆ 使用传统分割方法的结果补足深度学习结果的召回。
◆ 基于多帧追踪的概率模型融合:比如利用马尔可夫分布的特点、贝叶斯的方法对多帧数据进行一定的平滑,以得到更好的效果。
通过传统方法和深度学习方法的相互结合与补充,我们最终可以实现优点兼具的物体检测策略。
做自动驾驶真的是一个很崎岖的旅程,不断的解决问题之后又出现新的问题,不过正是因为过程的艰难,才带来更多的快乐。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:自动驾驶深度感知技术对车和行人的检测 https://www.yhzz.com.cn/a/17794.html