华为达芬奇( HUAWEI DaVinci )架构,是华为自研的面向AI计算特征的全新计算架构,具备高算力、高能效、灵活可裁剪的特性,是实现万物智能的重要基础。 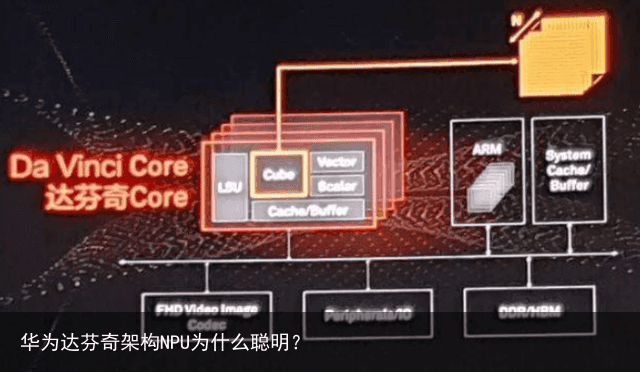 AI计算的核心是矩阵乘法运算,计算时由左矩阵的一行和右矩阵的一列相乘,每个元素相乘之后的和输出到结果矩阵。在此计算过程中,标量( Scalar)、向量( Vector)、矩阵(Matrix)算力密度依次增加,对硬件的AI运算能力不断提出更高要求。
AI计算的核心是矩阵乘法运算,计算时由左矩阵的一行和右矩阵的一列相乘,每个元素相乘之后的和输出到结果矩阵。在此计算过程中,标量( Scalar)、向量( Vector)、矩阵(Matrix)算力密度依次增加,对硬件的AI运算能力不断提出更高要求。
华为达芬奇架构采用3D Cube针对矩阵运算做加速,大幅提升单位面积下的AI算力,每个AI Core可以在一个时钟周期内实现4096个半精度MAC操作,相比传统的CPU和GPU实现数量级的提升。为提升AI计算的完备性和不同场景的计算效率,达芬奇架构还集成了向量、标量、硬件加速器等多种计算单元。同时支持多种精度计算,支撑训练和推理两种场景的数据精度要求,实现AI的全场景需求覆盖。
华为达芬奇架构具备灵活可裁剪的特性,可用于小到几十毫瓦,大到几百瓦的训练场景,支持AI从端侧、边缘侧到中心侧的全场景部署。
华为达芬奇架构具备灵活可裁剪的特性,可用于小到几十毫瓦,大到几百瓦的训练场景,支持AI从端侧、边缘侧到中心侧的全场景部署。
举例来说,在智能手机这一典型的AI场景中, 麒麟990 5G采用华为达芬奇架构NPU,创新设计NPU双大核加NPU微核架构,NPU大核展现卓越性能与能效,微核实现超低功耗。基于麒麟990 5G的AI强劲算力,华为P40系列带来AI路人移除、AI反光消除等功能,让更多受限于功耗和算力的AI应用成为现实。 
在边缘侧、中心侧甚至是云端,华为达芬奇架构同样能够提供强在边缘侧、中心侧甚至是云端,华为达芬奇架构同样能够提供强劲算力,赋能异腾系列人工智能芯片开启智慧未来。其中,舁腾310是华为首款全栈全场景人工智能芯片,为智慧城市、自动驾驶、云业务和IT智能、智能制造、机器人等应用场景提供解决方案;异腾910更是业界算力最强的AI处理器,支持云边端全栈全场景应用,算力完全达到设计规格,充分展现强劲AI实力。
关于华为自研的达芬奇NPU架构,您怎么看?
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:华为达芬奇架构NPU为什么聪明? https://www.yhzz.com.cn/a/14635.html