PyTorch 数据封装
PyTorch 为我们提供了两个类型 Dataset 和 DataLoader,前者负责创建可被 PyTorch 使用的数据集,而后者负责向训练过程传递数据。
如果想个性化自己的数据集或者数据传递方式,也可以自己重写子类。
Dataset
Dataset 是一个抽象类,其完整调用路径是 torch.utils.data.Dataset。自定义的 Dataset 需要继承它,并实现两个成员魔术方法:
__getitem__() __len()__()而其中 __getitem__ 更需要根据情况灵活地进行编写,例如
from PIL import Image def __getitem__(self, index): img_path, label = self.data[index].img_path, self.data[index].label img = Image.open(img_path) return img, label只要以标准形式返回一个包含图像和对应标签的元组就可以了。
另一个 __len__ 返回数据集包含的数据量:
def __len__(self): return len(self.data)另外,PyTorch 也提供了一些实用的 transformer,包含在 torchvision.transforms 中。常用的有 Resize,RandomCrop,Normalize,ToTensor 等等。TorchVision 是 PyTorch 的额外组件,提供了 CV 方面的一些工具包。
Dataset 是 DataLoader 实例化的一个参数。例如,CIFAR10 是图像分类、目标检测任务中的一个常用数据集,也是 CV 领域常见的标准 benchmark。我们经常能够在开源的模型代码中见到:
import torchvision.datasets as datasets train_set = datasets.CIFAR10(“data”, transform=train_transform, train=True, download=True)在 torchvision.datasets 中包含了常用的数据集。datasets.CIFAR10 是 Dataset 的一个子类。
如果需要使用自己的数据作为数据集,除了继承 Dataset,也可以使用 ImageFolder 来构建:
my_dataset = datasets.ImageFolder(path/to/data, trasform=data_transform)DataLoader
DataLoader 的初始化参数列表如下:
dataset:要从中加载数据的数据集。 batch_size:每个批要装载多少样本数据。 shuffle:设置为 True 可以在每个 epoch 重新洗牌数据。 sampler:定义从数据集中提取样本的策略。 batch_sampler:与 sampler 功能类似,但一次返回一批索引。 num_worker:要使用多少子进程装载数据。“0”表示数据将在主进程中加载。 collate_fn:将一组样本合并成一个小批张量。在从字典样式的数据集进行批加载时使用。 pin_memory:如果为True,DataLoader 将把 Tensor 复制到CUDA固定内存中,然后返回它们。 drop_last:如果数据集大小不能被批大小整除,则设置为 True 以删除最后一个不完整的批。如果 False 和数据集的大小不能被批大小整除,那么最后的批会更小。可以看到,主要的参数就是 dataset 以及 batch_size。
Sampler
这里带来了另一个新的概念,就是 Sampler。Dataset、DataLoader 以及 Sampler 的关系大概可以用以下的图表示:
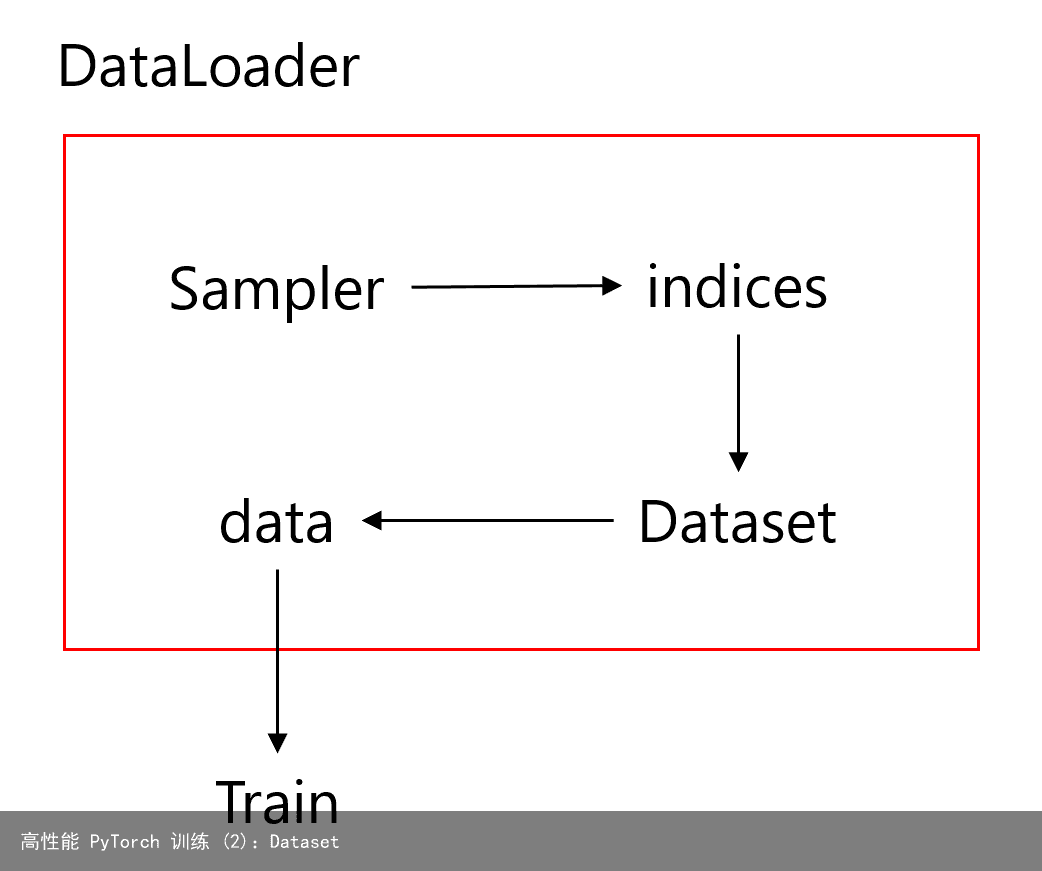
可以参考 DataLoader.__next__ 的源码来方便我们理解整个的工作流程:
class DataLoader(object): … def __next__(self): if self.num_workers == 0: indices = next(self.sample_iter) # Sampler batch = self.collate_fn([self.dataset[i] for i in indices]) # Dataset if self.pin_memory: batch = _utils.pin_memory.pin_memory_batch(batch) return batch假设我们的数据是一组图像,每一张图像对应一个 index,那么如果我们要读取数据就只需要对应的 index 即可,即上面代码中的 indices,而选取 index 的方式有多种,有按顺序的,也有乱序的,所以这个工作需要 Sampler 完成。在拿到 index 之后,就可以依此在 Dataset 中读取相应的数据和标签。
在上文中 DataLoader 的初始化参数中可以看到里有两种 sampler:sampler 和 batch_sampler,都默认为None。前者的作用是生成一系列的 index,而 batch_sampler 则是将 sampler 生成的 indices 打包分组,得到一个又一个 batch 的 index。例如下面示例中,BatchSampler 将SequentialSampler生成的index按照指定的batch size分组。
>>> in: list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)) >>> out: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]Pytorch 中已经实现的 Sampler 有如下几种:
SequentialSampler RandomSampler WeightedSampler SubsetRandomSampler所有采样器其实都继承自同一个父类,即Sampler。只要定义好 __iter__ 函数即可实现自定义的 sampler。
另外 BatchSampler 与其他 sampler 的主要区别是它需要将 Sampler 作为参数进行打包,进而每次迭代返回以 batch size 为大小的 index 列表。也就是说在后面的读取数据过程中使用的都是 batch sampler。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:高性能 PyTorch 训练 (2):Dataset https://www.yhzz.com.cn/a/13963.html