随着智能驾驶和自动驾驶等应用越发火热,汽车AI芯片市场在最近几年进入了高速发展期。无论是NXP和瑞萨这样的传统汽车芯片厂,还是如英伟达和英特尔这样的消费芯片大厂,甚至是FPGA龙头Xilinx,都对这个市场虎视眈眈。此外,国内外也有一大波初创芯片企业涌入这个市场。
Imagination作为全球半导体IP大厂,已推出多代AI加速产品,获得了良好的市场反响,可以为汽车芯片厂商打造高性能车用AI芯片提供强有力的支持。日前,Imagination发布其最新一代IMG Series4神经网络加速器(NNA)产品,该公司视觉和人工智能部门高级总监Andrew Grant在接受媒体采访时指出:“虽然目前市场上已经有能满足自动驾驶需求的AI芯片,但功耗不够理想。所以,我们花两年时间去了解和评估客户需求,推出了高性能低功耗的4系列NNA产品,并且将自动驾驶作为主打市场”。
Andrew Grant还介绍道,IMG Series4 NNA采用了全新的多核架构,能提供高达600 TOPS的算力,从而为ADAS和自动驾驶等应用提供高效支持。Imagination之所以能提供性能如此强悍的产品,得益于公司多年来在IP领域的深厚积累。
IP专家的步步为“赢”
在谈及Imagination的时候,大家首先想到的就是他们在手机GPU IP市场的影响力。
从Imagination提供的数据也可以看到,他们在移动GPU IP市场的份额已经达到35.5%,这帮助他们超越Arm Mali系列和高通Adreno系列,登上移动GPU IP龙头的位置。除了移动GPU以外,Imagination在车载GPU IP市场也几乎拿下了半壁江山。数据显示,他们在这个市场的占有率高达43%。
此外,Imagination在近来热门的AI 市场也布局多年。据介绍,Imagination在过去七年里持续加大对AI研发的投入,公司迄今已拥有超过80项针对AI领域的专利,并推出了一系列神经网络加速器IP产品。
这系列IP是一个从0开始设计的完整、独立式的硬件IP神经网络加速器,可以同时支持CNN、RNN、LSTM三种神经网络类型,并且可支持caff、caffe2、Google TensorFlow等通用机器学习体系架构,还支持可适用于移动端的TensorFlow Lite、caffe2go等机器学习体系架构。再加上这系列内核可在最小的硅面积上以非常低的功耗实现高性能的神经网络计算,因此自面世以来获得了客户的高度认可。Imagination在过去几年里也在快速迭代该系列IP。
2017年9月,Imagination发布了旗下首款神经网络加速器PowerVR Series 2NX NNA,其单核性能仅覆盖1TOPS到4.1TOPS的范围;而到了2018年推出的第二代PowerVR 3NX,单核性能不但覆盖了0.6TOPS到10TOPS,其多核产品性能更是能做到20TOPS到160TOPS,可以满足从L2级到L5级自动驾驶的边缘推理需求。
而文章开头谈到的IMG Series 4NNA则是Imagination推出的第三代NNA。
Andrew Grant表示,这款公司历时两年打造出来的产品不但在性能上获得大幅度提升,还拥有灵活的多核设计、创新性的Tensor Tiling( Imagination’s Tensor Tiling,ITT)技术、低功耗和满足车规级安全需求等多项优势,从而能为领先的汽车行业颠覆者、一级供应商、整车厂(OEM)和汽车系统级芯片(SoC)厂商提供强大助力。
IMG Series4 NNA 的强势出击
根据Andrew Grant的观点,当前的车载AI芯片拥有三方面的需求,分别是超强性能、超低功耗和超低延迟。当然,作为汽车级别的芯片,安全也是必不可少的,这就是IMG Series 4 NNA的设计指导。
从官方提供的资料我们可以看到,Series4具有以下特性:
首先是多核扩展性和灵活性方面,据Imagination介绍,其多核架构支持在多个核之间对工作负载进行灵活的分配和同步。Imagination的软件提供了精细的控制能力,并通过对多个工作负载进行批处理、拆分和调度而提高了灵活性,现在可以在任意数量的内核上使用。Series4可为每个集群配置 2个、4个、6个或者8个核。

其次是性能。据介绍,Series4的每个单核能够以不到一瓦的功耗提供12.5 TOPS的性能。举例来说,一个8核集群在5nm工艺的加持下,可以提供100 TOPS的算力。那就代表着配有6个8核集群的解决方案可以提供600 TOPS的算力。来到AI推理方面,Series4 NNA的性能比嵌入式GPU快20倍以上,与嵌入式CPU相比,更是快了1000倍。
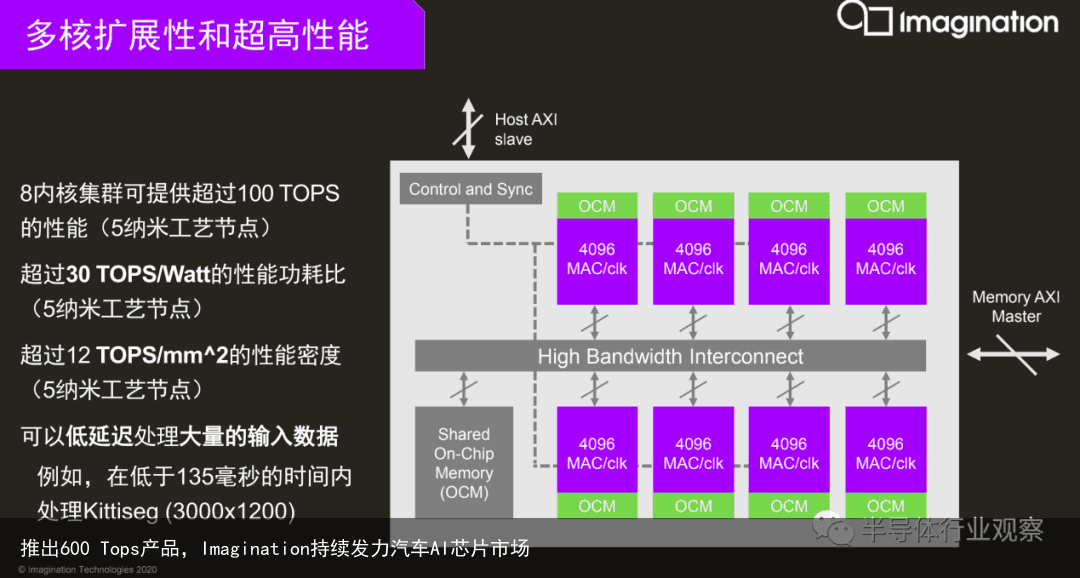
第三,超低延迟也是这一代NNA IP的另一个特性。据了解,通过将多个单核组成2核、4核、6核或8核的多核集群,所有内核可以相互协作,并行处理一个任务。这就降低了处理延迟,缩短响应时间。数据显示,对于一个8核集群,理想情况下延迟会减少为单核独立执行时的1/8。
节省大量带宽则是Imagination新NNA的另一大优势,这主要得益于公司正在申请专利的的Tensor Tiling技术(Imagination’s Tensor Tiling,ITT),这也是Series4中新增的功能。据介绍,借助这项技术,Imagination的Series4可以通过对计算任务进行tiling,充分利用片上存储,提升数据处理效率,并节省访问外部存储的带宽。

在具体操作中,针对不同的任务,有不同的操作方式。据了解,在批处理大量的小型任务时,Tensor Tiling能够把批处理任务分配到各个NNA单核,让每个NNA单核独立工作,提升并行处理的能力;而在面对一些大型网络的时候,Tensor Tiling则可以从多个维度拆分任务,让所有NNA单核共同执行一个推理任务。这不但减少了网络推理的延迟,在理想情况下,协同并行处理的吞吐量与独立并发处理也是相同的。
值得一提的是,这里的拆分都是通过Imagination的编译器来完成的,不需要开发者手动操作,借助NNA的性能分析工具,开发者还能对AI任务进行更好的调度和分配。

另外,因为利用本地数据的依赖性将中间数据保存在片上存储器中,ITT可以最大限度地减少将数据传输至外部存储器,从而将带宽降低多达90%。作为一种可扩展的算法,ITT在拥有大量输入数据的网络上具有显著优势。
车规级安全性则是Series4不得不提的另一个优势。
众所周知,汽车芯片对安全提出了更高的要求。Imagination为其全新的NNA引入了IP级别的安全功能,且产品的设计流程符合ISO 26262标准,这就能帮助客户更容易获得ISO 26262认证。据报道,Series4可以在不影响性能的情况下,安全地进行神经网络推理。硬件安全机制可以保护编译后的网络、网络的执行和数据处理管道。

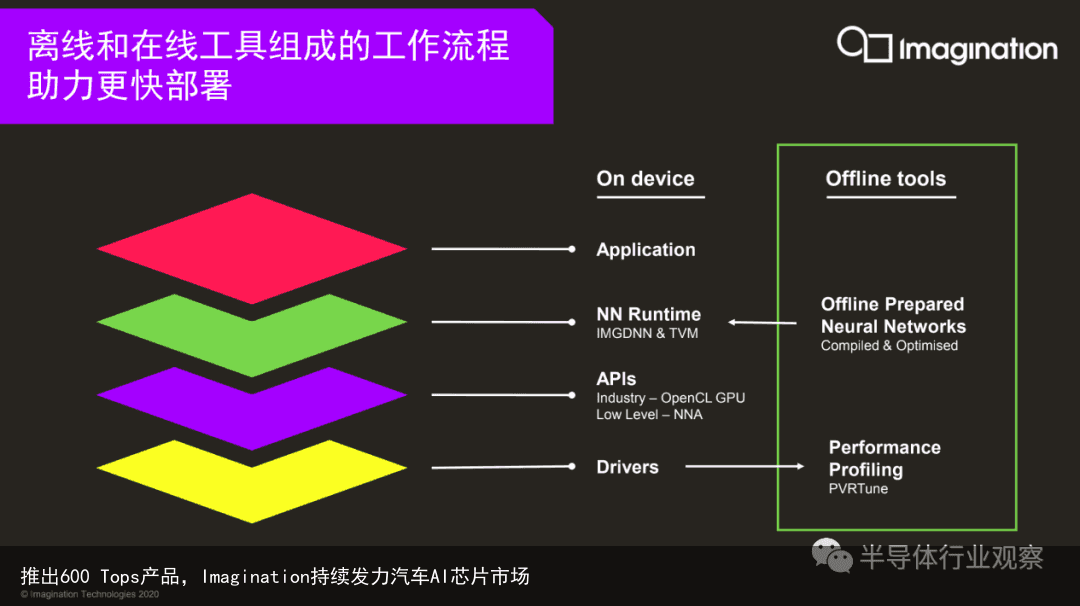
在IMG Series4 NNA的发布会上,Andrew Grant除了介绍新IP的硬件性能外,也同时讲述公司围绕这系列芯片打造的软件生态系统,这与硬件配合,加速了开发者的开发速度,简化了开发流程。而为了给汽车运算提供更多的算力支持,Imagination还打通了NNA多核平台与GPU协同,给开发者提供更多的选择。
Andrew Grant在发布会上表示,公司的IMG Series4 NNA已经开始向客户提供授权,产品也将于2020年12月在市场上全面供应。
ABI Research智慧出行和汽车首席分析师James Hodgson说道:“在从L2和L3级ADAS向L4和L5级全自动驾驶演进的过程中,神经网络的广泛应用将是至关重要的因素。这些系统将要处理数以百计的复杂场景,从多个摄像头和激光雷达等大量传感器中提取数据,从而实现自动代客泊车、十字路口管理和复杂城市环境安全导航等解决方案。高性能、低延迟和高能效的结合将是实现高度自动驾驶的关键所在。”
由此可见,一个全新的大门正在面向Imagination开启。
来自:Todaysemi今日芯片
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:推出600 Tops产品,Imagination持续发力汽车AI芯片市场 https://www.yhzz.com.cn/a/13921.html