如前文所述,在 PyTorch 训练过程中,一个主要的性能瓶颈就是数据集的导入和预处理。
在一般情况下,PyTorch 的 DataLoader 是实现了 __iter__ 和 __next__ 方法的,在 for 循环中,临时来从硬盘中导入数据,进行预处理并送入显存。这是 PyTorch 的一般实践,可以保证训练稳定地进行而不会出错。但是另一方面,稳定就代表不够高效。以 CIFAR10 数据集为例,在正常的训练中,每次导入训练数据大概 64 至 128 张图片左右,每张图片的尺寸为 [3, 32, 32]。再加上预处理的时间,每个 batch 的导入就需要花费近数秒钟。而整个训练过程动辄需要导入 200k+ 的 batch,花费的额外时间可想而知。
如果我们充分从代码层面上减少数据导入所用到的时间,就可以充分利用硬件的性能,来提高整个训练过程的效率。
数据导入时的并行优化
默认情况下,一个 batch 的数据导入也是串行的。显然,这是非常不合理的,因为数据与数据之间没有任何的依赖关系。现在的主流 CPU 至少 4 个物理核心起步,好一点的服务器甚至有几百个物理核之多。这时候就需要在 DataLoader 实例化的时候进行定义。
DataLoader(…, pin_memory=True, num_workers=xxx, …)其中,pin_memory=True 表示将数据导入到 GPU 的固定显存中,压缩数据加载和转移的时间。而 num_workers 就很明显了,顾名思义,就是指导入进程时的子进程数。一般来说,建议设置为 CPU 的总线程数。
这样,数据就会以并行的方式加载到显存中以供调用。
数据导入时的异步优化
我们可以设想以下两种过程:
所有的过程都是同步的。在一个周期内,需要先等待时间开销为 t1 的数据加载完成,然后进行时间开销为 t2 的训练过程,总时间开销为 t1+t2; 异步地进行数据加载。在进行训练的同时,加载下一次训练所需要的数据,并等待训练完成。这样的总时间开销为 t2。显然,对于数据量越大的任务,t1 会带来更大的影响。
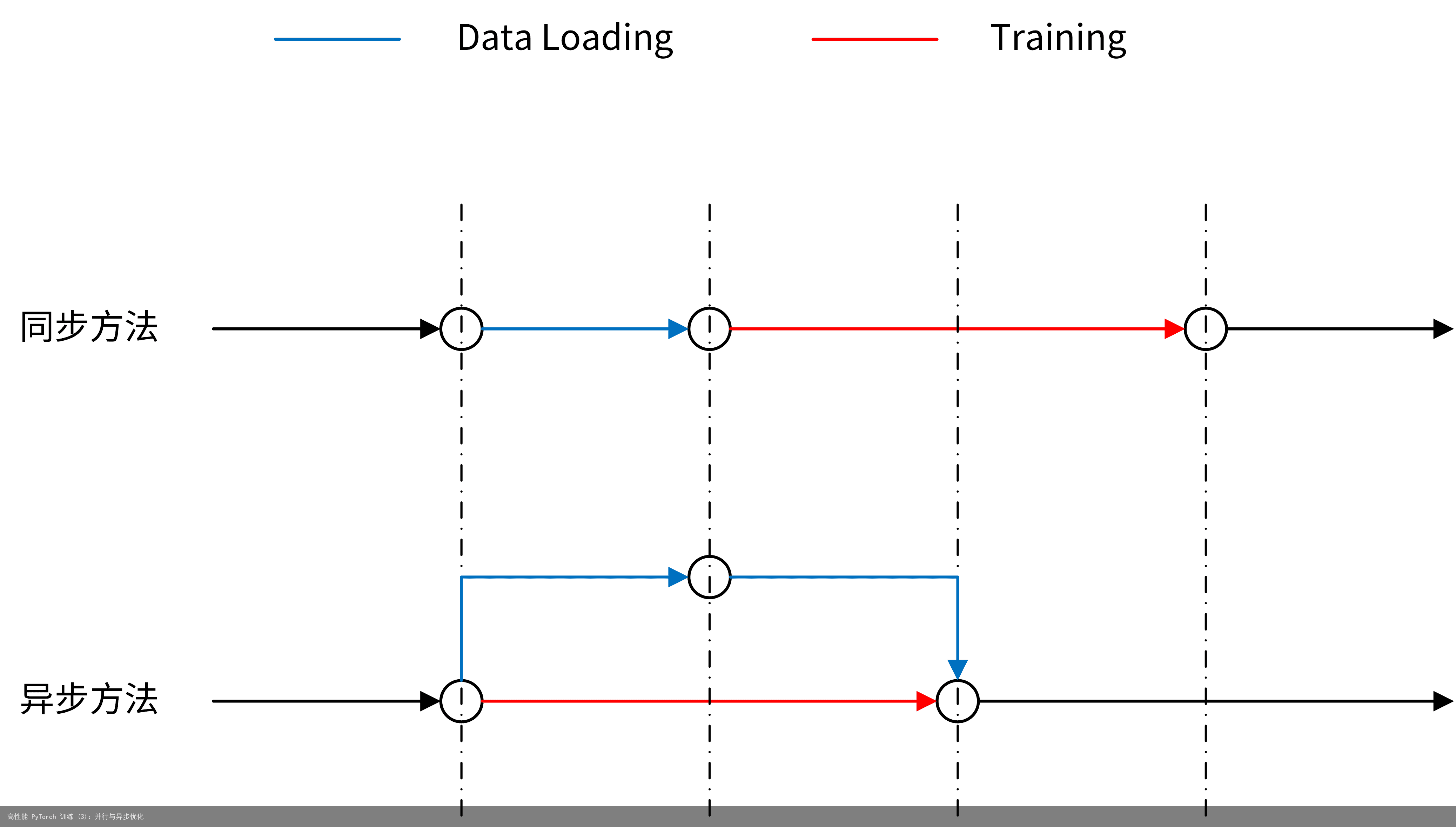
实现这种异步加载的方式也很简单。我们知道,CPU 和 GPU 之间是类似于 C/S 架构的关系,即由 CPU 发出指令并进行由一个线程进行异步等待,而 GPU 收到指令后分配一定的资源进行运算,并返回给阻塞等待的线程。可以充分利用这种关系,通过异步的形式来实现整个的加速过程。
class CudaDataLoader: “”” 异步预先将数据从 CPU 加载到 GPU 中 “”” def __init__(self, loader, device, queue_size=2): self.device = device self.queue_size = queue_size self.loader = loader self.load_stream = torch.cuda.Stream(device=device) self.queue = Queue(maxsize=self.queue_size) self.idx = 0 self.worker = Thread(target=self.load_loop) self.worker.setDaemon(True) self.worker.start() def load_loop(self): “”” 不断的将 cuda 数据加载到队列里 “”” # The loop that will load into the queue in the background while True: for i, sample in enumerate(self.loader): self.queue.put(self.load_instance(sample)) def load_instance(self, sample): “”” 将 batch 数据从 CPU 加载到 GPU 中 “”” if torch.is_tensor(sample): with torch.cuda.stream(self.load_stream): return sample.to(self.device, non_blocking=True) elif sample is None or type(sample) in (list, str): return sample elif isinstance(sample, dict): return {k: self.load_instance(v) for k, v in sample.items()} else: return [self.load_instance(s) for s in sample] def __iter__(self): self.idx = 0 return self def __next__(self): # 加载线程意外退出了 if not self.worker.is_alive() and self.queue.empty(): self.idx = 0 self.queue.join() self.worker.join() raise StopIteration # 一个 epoch 加载完了 elif self.idx >= len(self.loader): self.idx = 0 raise StopIteration # 下一个 batch else: out = self.queue.get() self.queue.task_done() self.idx += 1 return out def next(self): return self.__next__() def __len__(self): return len(self.loader) @property def sampler(self): return self.loader.sampler @property def dataset(self): return self.loader.dataset这样,多 CPU 线程加载数据然后异步转移到 GPU 上整一条链路都进行了优化。
我们还可以继续进行一定的优化。在使用中,我发现在每个 epoch 开始加载数据的时候,DataLoader 还是会重新初始化 CPU 线程以及队列之类的,凭空消耗了相当多的垃圾时间。可以直接使用上次的就好。
class _RepeatSampler(object): “”” 一直repeat的sampler “”” def __init__(self, sampler): self.sampler = sampler def __iter__(self): while True: yield from iter(self.sampler) class MultiEpochsDataLoader(torch.utils.data.DataLoader): “”” 多 epoch 训练时,DataLoader 对象不用重新建立线程和 batch_sampler 对象,以节约每个 epoch 的初始化时间 “”” def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) object.__setattr__(self, batch_sampler, _RepeatSampler(self.batch_sampler)) self.iterator = super().__iter__() def __len__(self): return len(self.batch_sampler.sampler) def __iter__(self): for i in range(len(self)): yield next(self.iterator)综上,真正使用时,只需要上面的代码,重新封装 DataLoader 即可。
loader = MultiEpochsDataLoader(data_set, batch_size=128, shuffle=True, num_workers=32, pin_memory=True) if torch.cuda.is_available(): loader = CudaDataLoader(loader, cuda) for image in loader: train_model(image)在我的实际使用中,每个 epoch 可以加速接近 40%。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:高性能 PyTorch 训练 (3):并行与异步优化 https://www.yhzz.com.cn/a/13773.html