上一篇文章AI社交距离检测器:在视频帧中进行目标检测我们学习了如何在视频帧中检测目标对象。
在本文中,我们将从测试数据集(包括存储在视频文件中的视频序列)对帧执行对象检测。
在这里,我们将使用MobileNet对象检测器来查找视频序列中的人。运行代码后,我们注意到检测并不完美。
对象检测器通常应用于来自各种摄像机的视频流。有时,在视频帧执行对象检测中会检测到并不是人的对象,在对象,并且必须查找特定的对象。在本文中,我们将从这一点开始,实现如何过滤掉不是我们要的检测结果,以便只显示人。我们将实现以下图片所示的结果(注意后面的图片没有检测到自行车)。
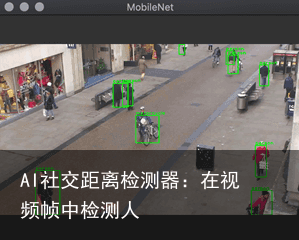
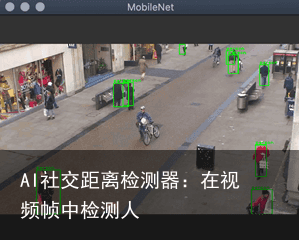
读取视频文件
为了读取视频文件,我创建了一个reader.py来读取视频文件。在内部,这个类使用OpenCV的VideoCapture从摄像机中读取画面,需要将文件路径传递给VideoCapture进行初始化:
def __init__(self, file_path): try: self.video_capture = opencv.VideoCapture(file_path) except expression as identifier: print(identifier)然后,通过调用read方法VideoCapture类实例:
def read_next_frame(self): (capture_status, frame) = self.video_capture.read() # Verify the status if(capture_status): return frame else: return None使用VideoReader类,首先调用初始化程序以提供输入视频文件,然后调用read_next_frame方法读取帧所需的次数。当方法到达文件末尾时,它将返回None.
检测人
为了检测人员,我从前面创建的模块开始,包括Inference和ImageHelper类。我将在main.py中引用它们。这些模块的源代码在前一篇文章中有解释。
为了引用模块,我修改了main.py文件:
import sys sys.path.insert(1, ../Part_03/) from inference import Inference as model from image_helper import ImageHelper as imgHelper因此,我们可以轻松地访问视频文件的帧上的对象检测:
# Load and prepare model model_file_path = ../Models/01_model.tflite labels_file_path = ../Models/02_labels.txt # Initialize model ai_model = model(model_file_path, labels_file_path) # Initialize video reader video_file_path = ../Videos/01.mp4 video_reader = videoReader(video_file_path) # Get frame from the video file frame = video_reader.read_next_frame() # Detect objects score_threshold = 0.5 results = ai_model.detect_objects(frame, score_threshold)然而问题是,这会检测到所有的对象,但是我们只要检测人员,我们需要过滤掉其他对象,我们可以使用detect_objects方法。过滤方法实现如下:
def detect_people(self, image, threshold): # Detect objects all_objects = self.detect_objects(image, threshold) # Return only those with label of person people = filter(lambda r: r[label] == person, all_objects) return list(people)我加入了上面的方法,detect_people和Inference类。一个detect_people函数内部调用detect_objects然后使用filter,一个内置的Python函数。第一个参数是滤波方法。在这里,我使用一个返回布尔值的匿名lambda函数。它是True当当前检测结果的标签为“Person”时,不然的话为False。
显示检测结果
为了显示检测到的人,我使用静态display_image_with_detected_objects方法的image_helper模块。但是,display_image_with_detected_objects方法用于显示图像,直到用户按下键。如果我将其用于视频序列,用户将需要按下每个帧的键。为了将其改编为视频,我添加了另一个参数来修改该方法:delay。我把这个参数的值传递给OpenCV的waitKey方法来强制执行等待超时:
@staticmethod def display_image_with_detected_objects(image, inference_results, delay = 0): # Prepare window opencv.namedWindow(common.WINDOW_NAME, opencv.WINDOW_GUI_NORMAL) # Draw rectangles and labels on the image for i in range(len(inference_results)): current_result = inference_results[i] ImageHelper.draw_rectangle_and_label(image, current_result[rectangle], current_result[label]) # Display image opencv.imshow(common.WINDOW_NAME, image) # Wait until the user presses any key opencv.waitKey(delay)默认情况下,延迟为0,因此该方法仍将处理对它的调用,这些调用期望它等待按键。
把东西放在一起
在所有组件准备就绪后,我们可以将它们放在一起:
import sys sys.path.insert(1, ../Part_03/) from inference import Inference as model from image_helper import ImageHelper as imgHelper from video_reader import VideoReader as videoReader if __name__ == “__main__”: # Load and prepare model model_file_path = ../Models/01_model.tflite labels_file_path = ../Models/02_labels.txt # Initialize model ai_model = model(model_file_path, labels_file_path) # Initialize video reader video_file_path = ../Videos/01.mp4 video_reader = videoReader(video_file_path) # Detection and preview parameters score_threshold = 0.4 detect_only_people = False delay_between_frames = 5 # Perform object detection in the video sequence while(True): # Get frame from the video file frame = video_reader.read_next_frame() # If frame is None, then break the loop if(frame is None): break # Perform detection if(detect_only_people): results = ai_model.detect_people(frame, score_threshold) else: results = ai_model.detect_objects(frame, score_threshold) # Display results imgHelper.display_image_with_detected_objects(frame, results, delay_between_frames)这里有两个开关来控制脚本的执行。首先,有detect_only_people变量,该变量控制脚本是否检测到所有对象(False)或只有人(True)。第二,有delay_between_frames变量,它控制帧之间的延迟,从而控制结果预览的速度。默认情况下,我将其设置为5ms。
总结
在本文中,我们使用MobileNet对象检测器来查找视频序列中的人。运行代码后,我们注意到检测并不完美。有些人不被认出来。即使检测分数降低,这也不会得到改善。我们稍后将通过使用更完善的对象检测来解决这个问题。但是首先,我们将学习如何计算图像中人与人之间的距离,以检查他们是否太近。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:AI社交距离检测器:在视频帧中检测人 https://www.yhzz.com.cn/a/13484.html