之前的一系列文章中,我们介绍了Bayes分类器。使用Bayes决策进行分类时,需要确定类的条件概率密度,其形式往往很难确定,即使使用非参数估计,也需要大量样本。所以使用Bayes决策时程序运行耗时长、效率低。我们能不能不使用类的条件概率等概率值作为判别函数,而是根据样本直接设计判别函数呢?答案是肯定的,我们在解决实际问题时,首先给定判别函数的形式,然后根据样本确定判别函数中的未知参数。实际情况中,为了简化问题,我们往往使用线性判别函数,往往从二分类开始,逐渐推广到多分类、非线性的情形中去。本篇文章先为大家介绍一种简单的线性分类器——感知器。
二、感知器 为了更形象化,我们把二分类任务可以看作在二维平面内确定一条直线,直线的一侧为第一类样本,另一侧为第二类样本,如图所示。 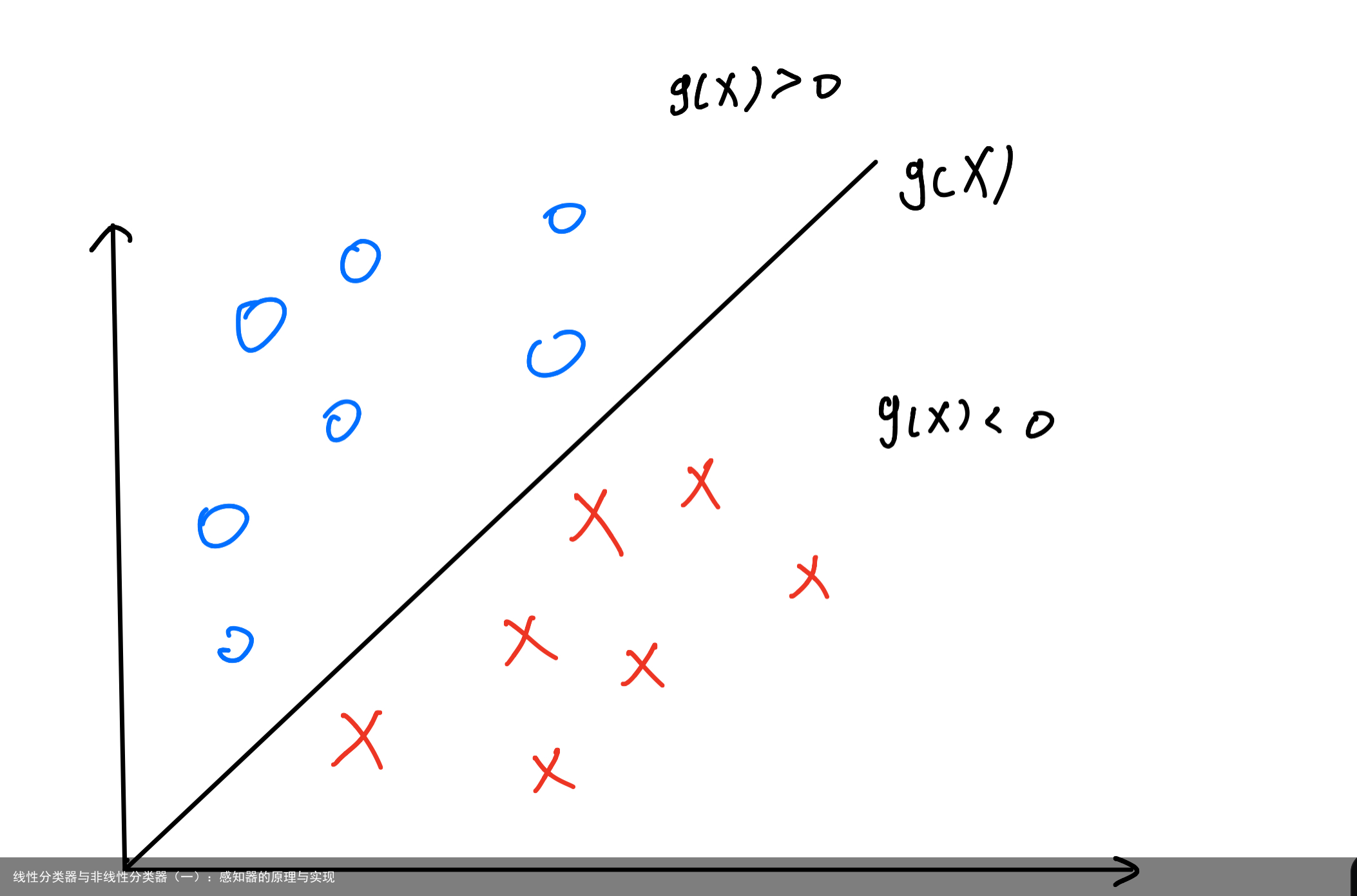 当线性可分时,这条直线一定存在,而且可能不止一条。为了简化,我们现在考虑线性可分的理想情况。我们可以定义一个判别函数g(x),则这条直线上的任意一点都满足g(x)=0,两类样本点分布在直线两侧,如果我们定义第一类样本点满足g(x)>0,则第二类样本点满足g(x)<0。感知器也属于线性分类器,下面将为大家具体介绍一下感知器的原理以及Matlab实现。 使用感知器时,定义g(x)为权值矩阵和样本的乘积,接着将训练样本处理成增广矩阵,然后对训练样本规范化,即对第二类样本数据取相反值,使得全部样本正确分类时满足:判别函数g(x)>0。然后确定初始化权值矩阵,开始“训练”样本,记录每一轮训练中,不满足g(x)>0的样本数量,即错分样本数量,将其定义为准则函数,通过梯度下降法确定使准则函数(错分样本数量)最小时判别时的权值矩阵,达到正确分类的目的。当样本线性可分时,对于所有样本都可以正确分类。 具体实现如下: (1)导入数据并对数据进行处理(增广和规范化)。
当线性可分时,这条直线一定存在,而且可能不止一条。为了简化,我们现在考虑线性可分的理想情况。我们可以定义一个判别函数g(x),则这条直线上的任意一点都满足g(x)=0,两类样本点分布在直线两侧,如果我们定义第一类样本点满足g(x)>0,则第二类样本点满足g(x)<0。感知器也属于线性分类器,下面将为大家具体介绍一下感知器的原理以及Matlab实现。 使用感知器时,定义g(x)为权值矩阵和样本的乘积,接着将训练样本处理成增广矩阵,然后对训练样本规范化,即对第二类样本数据取相反值,使得全部样本正确分类时满足:判别函数g(x)>0。然后确定初始化权值矩阵,开始“训练”样本,记录每一轮训练中,不满足g(x)>0的样本数量,即错分样本数量,将其定义为准则函数,通过梯度下降法确定使准则函数(错分样本数量)最小时判别时的权值矩阵,达到正确分类的目的。当样本线性可分时,对于所有样本都可以正确分类。 具体实现如下: (1)导入数据并对数据进行处理(增广和规范化)。
(2)初始化增广权值矩阵,设置学习率
% 初始化增广权值矩阵 a=zeros(d,5); % 设置学习率为1 learning_rate=1;(3)进行一定次数的训练。遇到错分情况时,对权值进行更新。保存每一轮的权值和错误率。
% 每一轮的错分样本数 error=zeros(1,5); % 进行5轮训练 for epoch=1:5 for t=1:n y=Training_datas(:,t); if a(:,epoch)*y<=0 error(epoch)=error(epoch)+1; a=a+learning_rate*y; end end error_rate=error(epoch)/n; fprintf(第%d轮训练结束,错误率为%f\n,epoch,error_rate); end(4)取错误率最小的一组权值,准备进行预测。
% 取训练数据错误率最小一组的的权向量进行预测 [~,argmin]=min(error); a=a(:,argmin);(5)对测试数据进行增广化,使用训练得到的权值计算判别函数,从而进行分类,并计算正确率。
n=size(Testing,2); temp=ones(1,n); % 将测试数据扩展成为增广矩阵 Testing=[temp;Testing]; predict=0; % 开始预测 for i=1:n y=Testing(:,i); if a*y>0 predict(i)=1; else predict(i)=2; end end acc=sum(predict==Label_Testing)/n; disp([测试集准确度是: num2str(acc)]) toc完整代码如下:
clear load(2-Class Problem.mat) tic % 将训练样本处理成为增广矩阵 n1=size(Training_class1,2); temp=ones(1,n1); Training_class1=[temp;Training_class1]; n2=size(Training_class2,2); temp=ones(1,n2); Training_class2=[temp;Training_class2]; % 第二类的数据进行规范化 Training_class2=-Training_class2; % 将两类训练数据合并 Training_datas=[Training_class1,Training_class2]; [d,n]=size(Training_datas); % 初始化增广权值矩阵 a=zeros(d,5); % 设置学习率为1 learning_rate=1; % 每一轮的错分样本数 error=zeros(1,5); % 进行5轮训练 for epoch=1:5 for t=1:n y=Training_datas(:,t); if a(:,epoch)*y<=0 error(epoch)=error(epoch)+1; a=a+learning_rate*y; end end error_rate=error(epoch)/n; fprintf(第%d轮训练结束,错误率为%f\n,epoch,error_rate); end % 取训练数据错误率最小一组的的权向量进行预测 [~,argmin]=min(error); a=a(:,argmin); n=size(Testing,2); temp=ones(1,n); % 将测试数据扩展成为增广矩阵 Testing=[temp;Testing]; predict=0; % 开始预测 for i=1:n y=Testing(:,i); if a*y>0 predict(i)=1; else predict(i)=2; end end acc=sum(predict==Label_Testing)/n; disp([测试集准确度是: num2str(acc)]) toc运行结果分析:训练到第5轮的时候,错误率为0,所有训练数据可以正确分类,使用第5轮的权值进行测试数据的分类,分类正确率为100%,耗时0.03s。 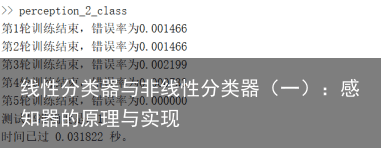
从结果我们可以看到,使用感知器进行二分类任务,运行耗时不到0.1s,而且能够达到100%的分类正确率,相比于bayes分类器,不仅提高了分类效率,而且我们在设计分类器时,不再像设计bayes分类器那样,需要懂得很多概率统计方面的知识,大大提高了程序设计以及程序运行效率。后面我们会发现,感知器的思想和BP神经网络的思想有些接近,只不过感知器无法处理非线性可分的问题。之后的文章将继续为大家介绍一些线性分类器。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:线性分类器与非线性分类器(一):感知器的原理与实现 https://www.yhzz.com.cn/a/13390.html