本文是使用Python和NLTK(开源自然语言工具包)的情感分析系列的第二篇。在本文中,我们将查看NLTK提供的数据集,以及将文本语料库以进行分析的示例。
情绪分析系列的目标是使用Python和开源自然语言工具包(NLTK)构建一个库,该库扫描社区帖子的回复,并检测回复是否使用负面、敌对或其他不友好的语言。
要开始使用自然语言工具包(NLTK)这样的库,进行自然语言处理(NLP),我们需要一些文本数据来开始探索。我们将查看NLTK提供的数据集,以及文本语料库以进行分析。
另外,我们还将探索Reddit API如何用于捕获NLP分析中有趣的评论数据。
NLTK数据集的分析
NLTK带来的一个便利是与工具包集成了丰富的数据集。您可以使用NLTK直接下载多个附加数据集。
让我们看一个包含在NLTK语料库中的数据集的例子,使用nltk.corpus.movie_reviews来查看数据。movie_reviews是来自IMDB的2,000个电影评论的集合,这些评论被标记为正面或负面评论。
如果要使用这些评论,首先要下载movie_reviews语料库。
import nltk nltk.download(movie_reviews) from nltk.corpus import movie_reviews它只是一个文本文件的集合,其中包含了最初写在评论中的单词。
~/nltk_data/corpora/movie_reviews ├── README ├── neg │ ├── cv000_29416.txt │ ├── cv001_19502.txt │ … │ ├── cv997_5152.txt │ ├── cv998_15691.txt │ └── cv999_14636.txt └── pos ├── cv000_29590.txt ├── cv001_18431.txt ├── cv002_15918.txt ├── …此标记数据集可用于机器学习应用程序。在积极或消极的评论中最常用的词语可以用于监督培训,这样你就可以根据从分析中建立的模型来探索新的数据集。
我们将在第二部分回到这个想法。确实有数据集在NLTK网站上,如亚马逊的产品评论,Twitter的社交媒体帖子,等等。
如果要使用NLTK语料库中的数据集以外的数据集,怎么办?
NLTK不附带Reddit语料库,所以让我们以它为例来说明如何自己收集一些NLP数据。
从Reddit收集NLP数据
假设我们想要进行NLP情绪分析。我们需要一个包含用户或客户之间公开对话文本的数据集。
NLTK没有用于此类分析的现有数据集,因此我们需要为自己收集类似的数据集。在本练习中,我们将使用Reddit讨论中公开提供的数据。
为什么是Reddit?
Reddit,它是一个用户生成的文章、照片、视频和基于文本的文章的社区,这些文章来自一个非常大的不同兴趣群体。
该网站拥有超过4亿用户和13.8万活跃的感兴趣区域,该网站一直排在互联网上访问量最大的10个网站之列。
它也是人们讨论和询问有关技术、技术、新产品、书籍和许多其他主题的问题的地方。它在18-35岁的人群中特别受欢迎,受到许多营销者的追捧。
不管你的业务是做什么,都可以在Reddit中找到有相同兴趣的人一起讨论它。
数据是通过Reddit API向公众提供的,所以我们需要做一些设置来访问API。
开始使用Reddit API
要开始使用Reddit API,您需要完成几个步骤。
创建一个帐户 注册Reddit API访问 创建Reddit应用程序创建一个帐户应该很简单。去Https://reddit.com并点击“注册”,或登录。
接下来,注册Reddit API访问。您可以在这里找到有关如何访问的详细信息:Https://www.reddit.com/wiki/api.
为了生产目的,阅读这些使用条款并接受它以进行API访问是很重要的。
注册后,您将登陆一个URL,用于创建Reddit应用程序:Https://www.reddit.com/prefs/apps/.
您可以选择任何适合您需要的值,但至少需要输入一个名称(我使用的是“sentiment analysis”)、类型(“script”)和重定向url(“http://localhost.com”).“)
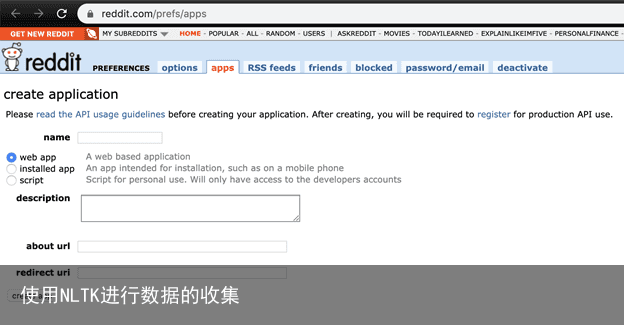
一旦你点击创建应用程序,您将能够在应用程序中检索需要的信息。
安装Reddit API客户端
可以使用API调用,也可以使用这个Python应用程序端库Python Reddit API包装器(PRW)来调用。
使用PythonPip包管理器在终端或命令提示符中安装PythonAPI客户端:
pip install praw要初始化客户端,需要按照Reddit的建议传递client_id, client_secret,以及user_agent,使用术语或标识您的应用程序。
我喜欢将这些设置为环境变量,这样它们就不会意外地包含在代码中。您可以通过使用标准Python中的函数来读取这些值。oslibrary。然后初始化os和praw库:
import os import praw reddit = praw.Reddit( client_id = os.environ[REDDIT_CLIENT_ID], client_secret = os.environ[REDDIT_CLIENT_SECRET], user_agent = “script:sentiment-analysis:v0.0.1 (by {})”.format(os.environ[REDDIT_USERNAME]) )在初始化Reddit API之后,我们将看到一些有用的方法来获取用于情绪分析的数据。
从Subreddit检索提交
如果您有一个您感兴趣的产品、技术、活动或社区,您可以在讨论它的地方找到并订阅Subreddit。例如,python下面的Subreddit允许用户发布提交的内容(供讨论的主题),其他用户可以对其进行投票(向上或向下),并发布自己的评论或关于该主题的问题。
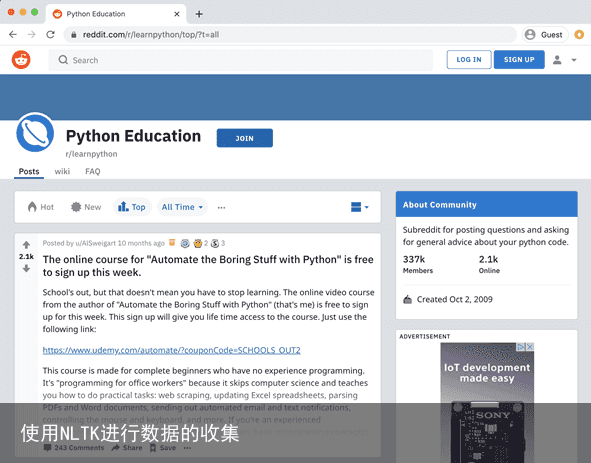
根据您的喜好,有几种方法可以对这些帖子进行排序或排序:
New-最近提交的帖子。 Top-在编辑投票系统中得票率最高的职位。 Up–最近出现了上升和评论的帖子。 Hot–最近的帖子不断上升/评论。 Controversial –这些帖子和评论既得到了支持,也得到了反对。在Reddit API中,每个方法都有相应的方法。以下是几个例子:
# Query for a subreddit by name sub = reddit.subreddit(learnpython) # Can query for top posts for a time period, the top 20 posts, or the # 10 most controversial posts of the past month top_posts_of_the_day = sub.top(day) hot_posts = sub.hot(limit=20) controversial_posts = sub.controversial(month, limit=10) # Can also search for use of a keyword nltk_posts = sub.search(‘nltk’) # Sample of some of the more interesting data about a # submission that could make for interesting analysis for submission in controversial_posts: print(“TITLE: {}”.format(submission.title)) print(“AUTHOR: {}”.format(submission.author)) print(“CREATED: {}”.format(submission.created)) print(“COMMENTS: {}”.format(submission.num_comments)) print(“UPS: {}”.format(submission.ups)) print(“DOWNS: {}”.format(submission.downs)) print(“URL: {}”.format(submission.url))Reddit上的每个提交都有一个URL。因此,无论我们是使用搜索、按日期进行过滤、还是只使用直接链接,我们都可以开始查看提交的内容,以获取用户评论。
如何在帖子上获得评论
当用户在帖子上发表评论时,其他用户可以回复。如果我们想了解我们的受众对提到我们的产品、服务或内容的帖子的反应,我们需要的主要数据是用户生成的评论,这样我们就可以对它们进行情感分析。
如果您知道某个特定帖子的URL很有趣,您可以直接从该链接检索提交:
post = “https://www.reddit.com/r/learnpython/comments/fwhcas/whats_the_difference_between_and_is_not” # Instead of getting submissions by querying a subreddit, this time # we go directly to a url for the post. submission = reddit.submission(url=post) submission.comments.replace_more(limit=None) # We can get the comments which the API returns as a generator, but # we can turn it into a list. comments = submission.comments.list():如果你在看这个网站,你只会看到超过一个特定阈值的评论。
您需要单击一个按钮来加载更多的注释。通过在查询注释之前取消限制,我们排除了那些嵌套的占位符,只获得了我们的情感分析所需的用户注释。
下一章
您已经看到了一些访问NLP预配置数据集的技术,以及从Reddit API和Reddit注释构建自己的数据集的技术。
NLP分析的下一章将在本文中讨论。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:使用NLTK进行数据的收集 https://www.yhzz.com.cn/a/13372.html