上一期我们讲到了Node-RED中函数节点的使用,利用函数节点我们可以调试程序,捕获错误,监听状态的改变,本篇文章我再来给大家讲一下Node-RED中序列sequence分类下的节点,该分类下有4个节点,
主要是用于对消息体的处理,四个都是仿照着数组的方法来实现的. 分别是split, joib,sort,batch,让我们来一个一个地分析如何使用这些节点完成Iot中流的处理。
splitsplit节点可以将一msg.payload基于一个字符串进行分割, 比如有一个字符串 msg.payload = 1;2;3;4;5 调用split节点后,使用;来分割msg.payload,那么split的下一级节点将会被触发5次
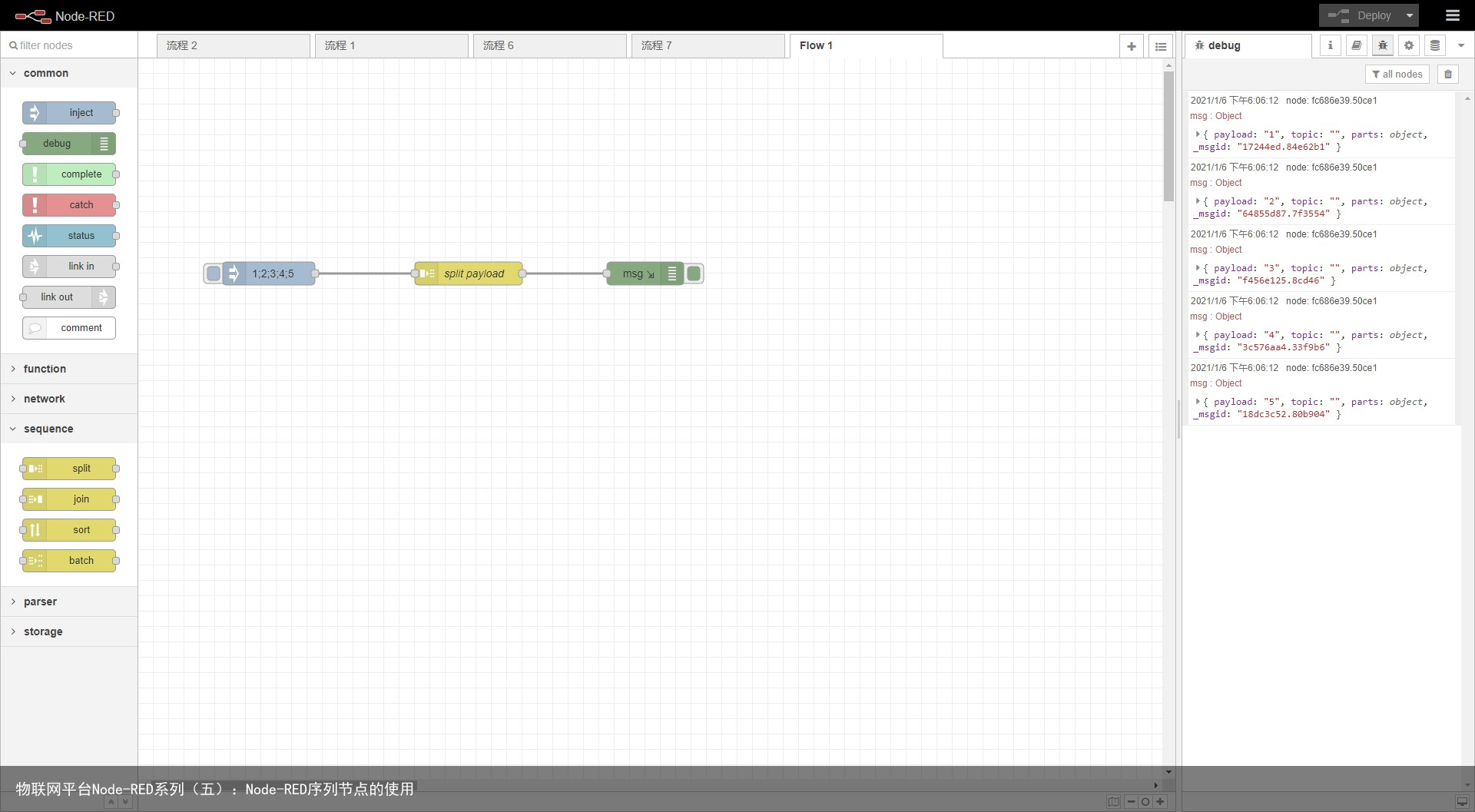
此节点也可以用于处理二进制,使用长度分割。
关于这个节点详细的解释
输入
payload节点的行为由msg.payload的类型决定:
字符串/buffer – 使用指定的字符(默认值:\n),缓冲区序列或固定长度将消息拆分。 数组 – 消息被拆分为单个数组元素或固定长度的数组。 object – 将为对象的每个键/值对发送一条消息。输出 partsobject 此属性包含有关如何将消息与原始消息分开的信息。如果传递给join节点,则可以将序列重组为单个消息。该属性具有以下属性:
id – 一组消息的标识符 index – 组中的位置 count – 如果已知组中的邮件总数。请参阅下面的“流媒体模式” type – 消息的类型-字符串/数组/对象/buffer ch – 对于字符串或buffer,用于将消息拆分为字符串或字节数组的数据 key – 对于对象,创建此消息的属性的键。可以将节点配置为也将此值复制到另一个消息属性,例如msg.topic len – 使用固定长度值拆分消息时,每段子消息的长度在使用join节点将序列重新组合为单个消息之前,推荐使用此节点来轻松地创建跨消息序列,执行通用操作的流。 它使用msg.parts属性跟踪序列的各个部分。
流媒体模式
该节点还可以用于重排消息流。例如,发送换行符终止命令的串行设备可能会传递一条消息,并在其末尾带有部分命令。 在“流模式”下,此节点将拆分一条消息并发送每个完整的段。如果末尾有部分片段,则该节点将保留该片段,并将其添加到收到的下一条消息之前。
在此模式下运行时,该节点将不会设置msg.parts.count属性,因为流中期望的消息数还是未知的。这意味着它不能在自动模式下与join节点一起使用。
join将消息序列合并为一条消息. 此模式假定此节点与split相连, 或者接收到的消息有正确配置的msg.parts属性.
共有三种模式:
自动模式 与split节点配对时,它将自动将已被拆分的消息进行合并。 手动模式 手动地以各种方式合并消息序列。 列聚合模式 对消息列中的所有消息应用表达式以将其简化为单个消息。输入 parts 使用自动模式时,所有的消息都应包含此属性。split节点会生成此属性,但也可以手动进行设置。该属性具有以下属性:
id – 消息组的标识符 index – 组中的位置 count – 如果已知组中的邮件总数。请参阅下面的“流媒体模式” type – 消息的类型-字符串/数组/对象/buffer ch – 对于字符串或buffer,用于将消息拆分为字符串或字节数组的数据 key – 对于对象,创建此消息的属性的键。可以将节点配置为也将此值复制到另一个消息属性,例如msg.topic/li> len – 使用固定长度值拆分消息时,每段子消息的长度complete 如果设置,则节点将以其当前状态发送其输出消息
详细
自动模式 自动模式使用传入消息的parts属性来确定应如何连接序列。这使它可以自动逆转split节点的操作。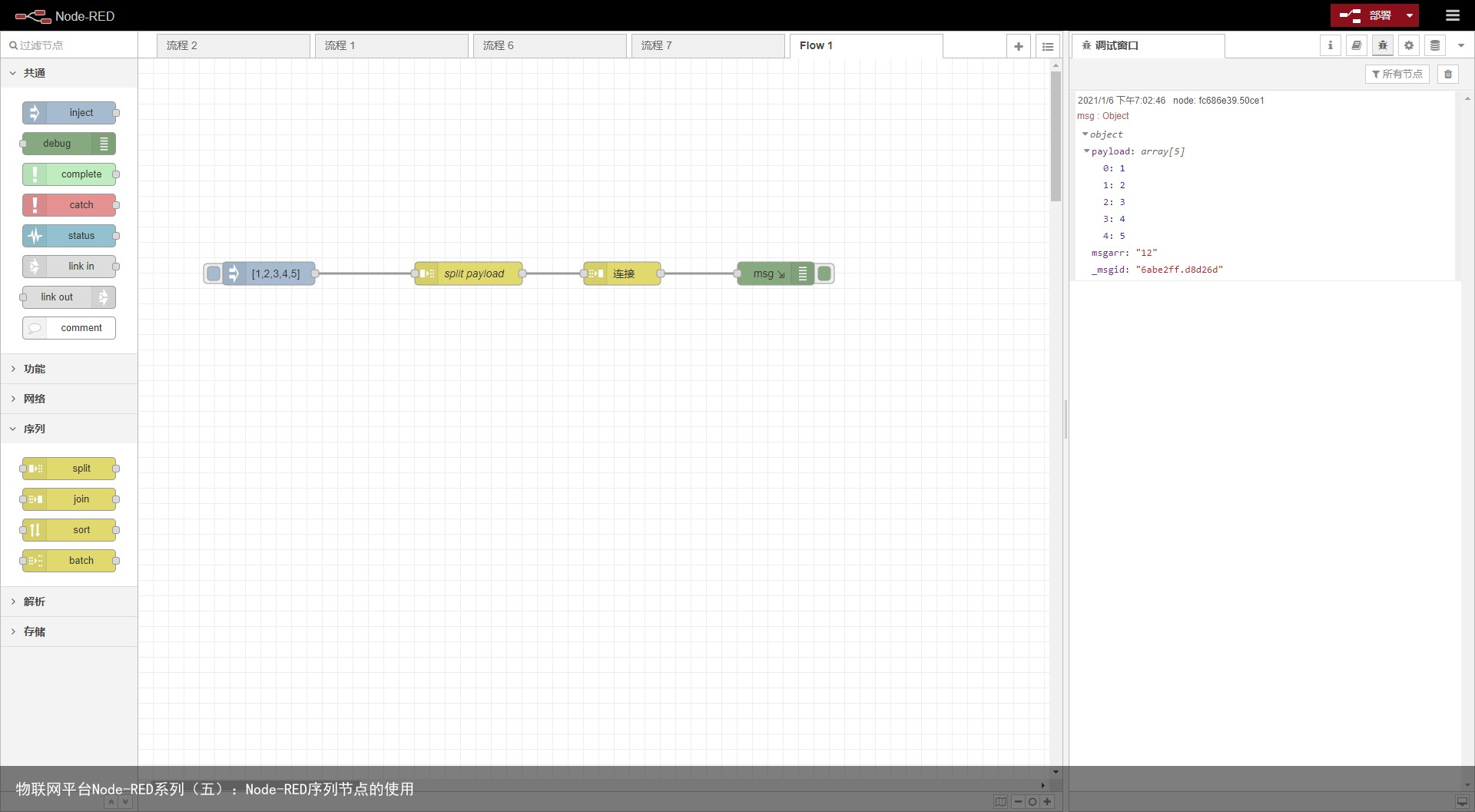
字符串或缓冲区-通过将每条消息的选定属性与指定的连接字符或缓冲区连接起来。 数组 – 通过将每个选定的属性或整个消息添加到输出数组 键/值对象 – 通过使用每个消息的属性来确定存储所需值的键。 merged object – 通过将每个消息的属性合并到一个对象下。 输出消息的其他属性都取自发送结果前的最后一条消息。
可以用计数来确定应接收多少条消息来进行合并。对于对象输出,可以设置为达到此计数后的每条后续消息都发送一条输出。
可以用超时来设置发送新消息之前的等待时间。
如果收到设置了msg.complete属性的消息时发送输出消息并重置消息列数。
如果收到设置了msg.reset属性的消息,则部分收到的消息将被删除而不发送,同时重置消息列数。
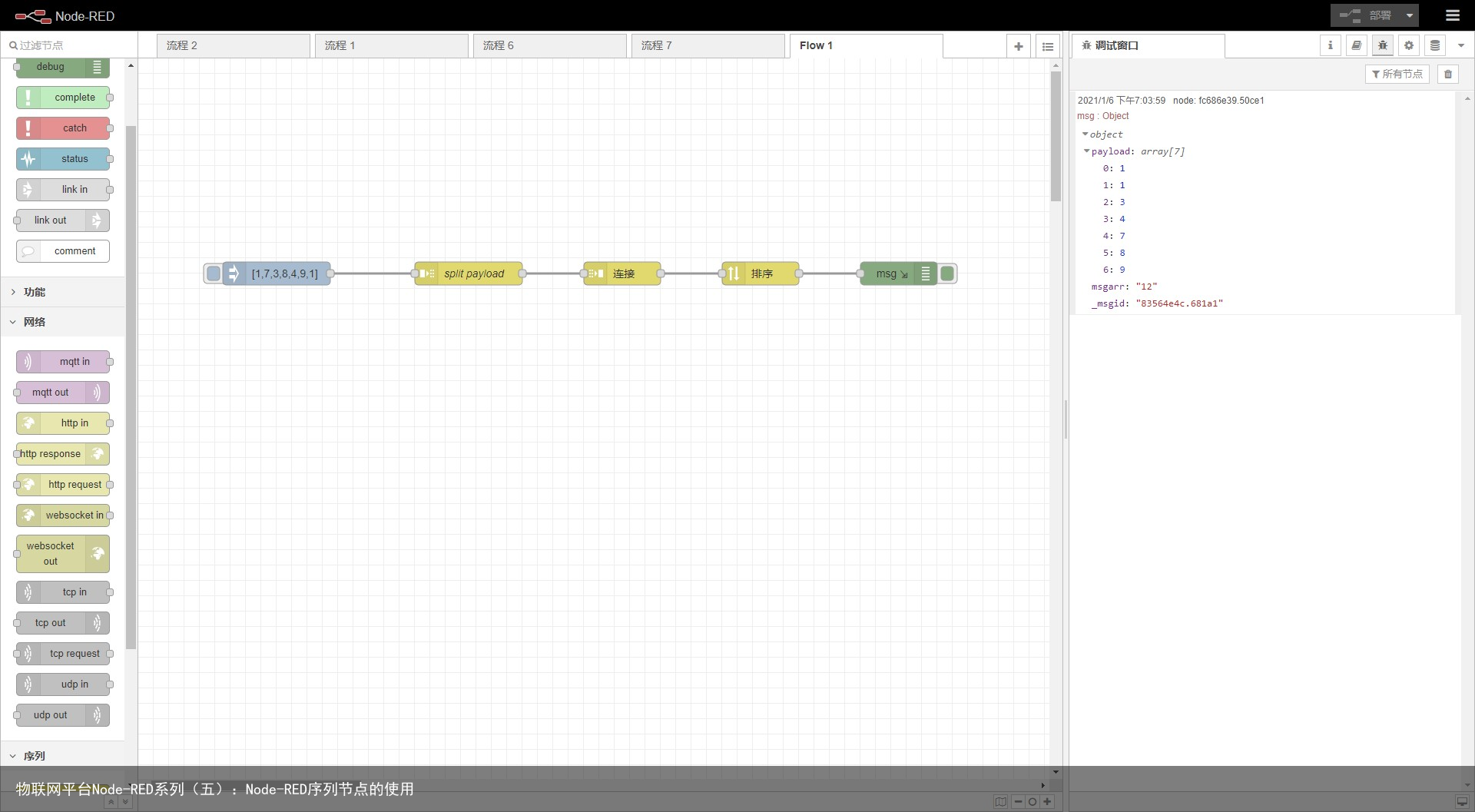
列聚合模式 选择列聚合模式时,将表达式应用于组成消息列的每条消息,并使用聚合值组成一条消息。 sort对消息属性或消息序列进行排序的函数。
当配置为对消息属性进行排序时,节点将对指定消息属性所指向的数组数据进行排序。
当配置为对消息序列排序时,它将对消息重新排序。
排序顺序可以是:
升序 降序 对于数字,可以通过复选框指定数字顺序。排序键可以是元素值,也可以是JSONata表达式来对属性值进行排序,还可以是message属性或JSONata表达式来对消息序列进行排序。
在对消息序列进行排序时,排序节点依赖于接收到的消息来设置msg.parts。拆分节点将生成此属性,但也可以手动创建。它具有以下属性:
id – 消息组的标识符 index – 组中的位置 count – 群组中的邮件总数 注意:在此节点的处理中,消息在内部存储。通过指定要累积的最大消息数,可以防止意外的高内存使用。默认设置是不限制消息数量。nodeMessageBufferMaxLength属性在settings.js中设置。
根据各种规则创建消息序列。
详细 有三种创建消息序列的模式:
讯息数 将消息分组为给定长度的序列。 overlap(重叠)选项指定在一个序列的末尾应重复多少消息。
时间间隔 对在指定时间间隔内到达的邮件进行分组。如果在该时间间隔内没有消息到达,则该节点可以选择发送空消息。
串联序列 通过串联输入序列来创建消息序列。每条消息必须具有msg.topic属性和标识其序列的msg.parts属性。该节点配置有topic值列表,以标识所连接的顺序序列。 储存讯息 该节点将在内部缓冲消息,以便跨序列工作。运行时设置nodeMessageBufferMaxLength可用于限制节点将缓存多少消息
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:物联网平台Node-RED系列(五):Node-RED序列节点的使用 https://www.yhzz.com.cn/a/13244.html