之前,我们分别使用线性模型以及二次模型对数据进行拟合,发现模型复杂度越高,越能贴合数据,预测精度越高。因此,我们是否可以认为只要算力条件充足,我们就可以尽可能地使用高复杂度模型进行函数的拟合?这就是本文讨论的主题:使用更复杂的模型会出现的问题以及解决方式。本文将分别使用线性模型、二次模型、五次模型以及七次模型分别进行房价数据的拟合,观察训练集和测试集的分布,以得到模型复杂度与模型性能的关系。 为了使现象更加明显,我们这次仅取少量的数据进行实验:10个数据组成的训练集和5个数据组成的测试集。关于这么做的原因,我们将在下一篇文章中进行解释。数据导入部分代码:
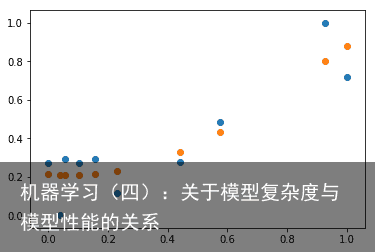
import pandas as pd import numpy as np import matplotlib.pyplot as plt import random # 导入数据 datasFile=pd.read_csv(data/data1810/data.txt,names=[size,price]) datas=np.array(datasFile) # 取前15个数据进行实验,并划分数据集,10个训练数据和5个测试数据 trainSet=datas[0:10,:] testSet=datas[10:15,:] trainX=trainSet[:,0] trainY=trainSet[:,1] testX=testSet[:,0] testY=testSet[:,1] # 归一化数据,最大最小值按照训练数据集来取 trainX_min_max=(trainX-np.min(trainX))/(np.max(trainX)-np.min(trainX)); trainY_min_max=(trainY-np.min(trainY))/(np.max(trainY)-np.min(trainY)); testX_min_max=(testX-np.min(testX))/(np.max(testX)-np.min(testX)); testY_min_max=(testY-np.min(testY))/(np.max(testY)-np.min(testY));导入的数据分布如下: 训练集:  测试集:
测试集: 
首先使用线性模型进行房价预测:
import random # 初始化回归相关参数值 a=random.random()# 随机初始化一个值 b=random.random() x=trainX_min_max y=trainY_min_max lr=0.1# 学习率 iter=500 # 训练次数 cost=0 # 开始训练 for i in range(1,iter+1): predict=a*x+b # 使用线性函数进行预测 # 计算损失函数 J=np.mean((predict-y)*(predict-y)) cost=np.append(cost,J) # 计算损失函数的梯度值 J_grad_a=np.mean((predict-y)*x) J_grad_b=np.mean(predict-y) # 进行参数迭代 a=a-lr*J_grad_a b=b-lr*J_grad_b # 打印参数的值 if i % 100 == 0: print(“iter=%d,” % i) print(“cost=%.3f” % J) print(“a=%.3f,” % a) print(“b=%.3f,” % b) print(“\n”) plt.plot(cost)训练结果如下: 最终训练集的误差为0.019 损失函数曲线:  表明算法已经收敛 将结果可视化:
表明算法已经收敛 将结果可视化: 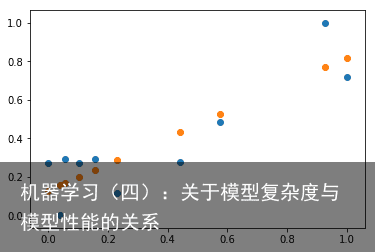 使用训练好的模型进行测试:
使用训练好的模型进行测试:
测试结果如下: 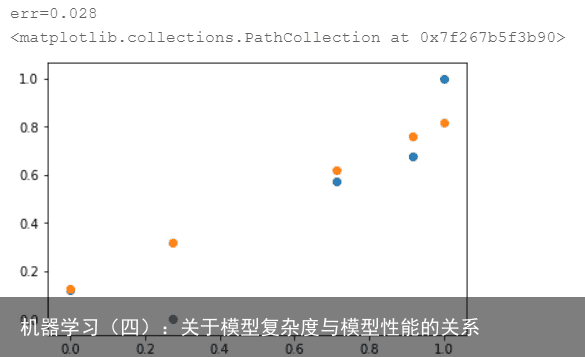 误差为0.028
误差为0.028
训练结果如下: 
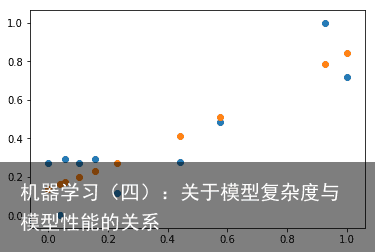 可以看出,算法成功收敛,并且误差为0.016,效果优于线性模型,下面将模型运用到测试集上:
可以看出,算法成功收敛,并且误差为0.016,效果优于线性模型,下面将模型运用到测试集上:
结果如下: 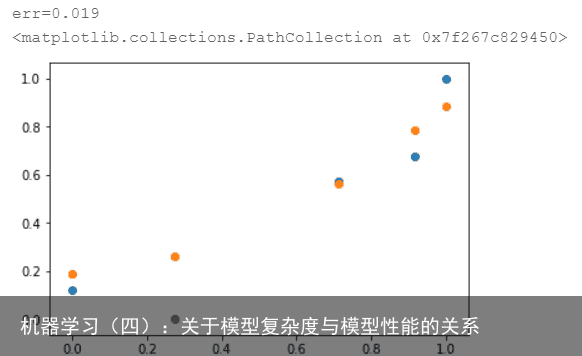 测试集正确率为0.019,优于线性模型,符合我们之前的结论:模型越复杂,效果越好
测试集正确率为0.019,优于线性模型,符合我们之前的结论:模型越复杂,效果越好
训练部分代码:
import random # 初始化回归相关参数值 a=random.random()# 随机初始化一个值 b=random.random() c=random.random() d=random.random() e=random.random() f=random.random() x=trainX_min_max y=trainY_min_max lr=0.1# 学习率 iter=500 # 训练次数 cost=0 # 开始训练 for i in range(1,iter+1): predict=a*np.power(x,5)+b*np.power(x,4)+c*np.power(x,3)+d*np.power(x,2)+e*x+f # 使用五次函数预测 # 计算损失函数 J=np.mean((predict-y)*(predict-y)) cost=np.append(cost,J) # 计算损失函数的梯度值 J_grad_a=np.mean((predict-y)*np.power(x,5)) J_grad_b=np.mean((predict-y)*np.power(x,4)) J_grad_c=np.mean((predict-y)*np.power(x,3)) J_grad_d=np.mean((predict-y)*np.power(x,2)) J_grad_e=np.mean((predict-y)*x) J_grad_f=np.mean(predict-y) # 进行参数迭代 a=a-lr*J_grad_a b=b-lr*J_grad_b c=c-lr*J_grad_c d=d-lr*J_grad_d e=e-lr*J_grad_e f=f-lr*J_grad_f # 打印参数的值 if i % 100 == 0: print(“iter=%d,” % i) print(“cost=%.3f” % J) print(“a=%.3f,” % a) print(“b=%.3f,” % b) print(“c=%.3f,” % c) print(“d=%.3f,” % d) print(“e=%.3f,” % e) print(“f=%.3f,” % f) print(“\n”) plt.plot(cost)训练结果: 
 算法收敛,最终误差为0.015,优于二次模型,且预测更能贴合真实数据,下面来看测试集的效果:
算法收敛,最终误差为0.015,优于二次模型,且预测更能贴合真实数据,下面来看测试集的效果:
结果如图: 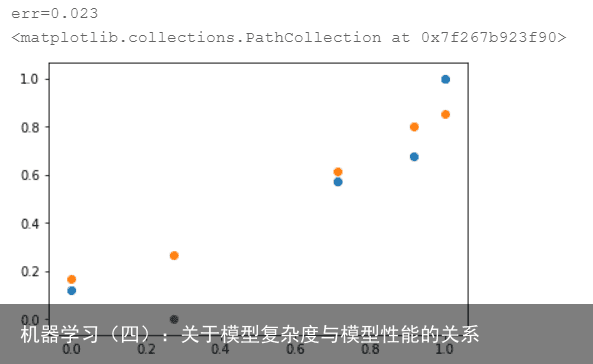 误差为0.023,测试集效果不如线性模型和二次模型。
误差为0.023,测试集效果不如线性模型和二次模型。
训练部分: 代码:
import random # 初始化回归相关参数值 a=random.random()# 随机初始化一个值 b=random.random() c=random.random() d=random.random() e=random.random() f=random.random() g=random.random() h=random.random() x=trainX_min_max y=trainY_min_max lr=0.1# 学习率 iter=2000 # 训练次数 cost=0 # 开始训练 for i in range(1,iter+1): predict=a*np.power(x,7)+b*np.power(x,6)+c*np.power(x,5)+d*np.power(x,4)+e*np.power(x,3)+f*np.power(x,2)+g*x+h # 使用七次函数预测 # 计算损失函数 J=np.mean((predict-y)*(predict-y)) cost=np.append(cost,J) # 计算损失函数的梯度值 J_grad_a=np.mean((predict-y)*np.power(x,7)) J_grad_b=np.mean((predict-y)*np.power(x,6)) J_grad_c=np.mean((predict-y)*np.power(x,5)) J_grad_d=np.mean((predict-y)*np.power(x,4)) J_grad_e=np.mean((predict-y)*np.power(x,3)) J_grad_f=np.mean((predict-y)*np.power(x,2)) J_grad_g=np.mean((predict-y)*x) J_grad_h=np.mean(predict-y) # 进行参数迭代 a=a-lr*J_grad_a b=b-lr*J_grad_b c=c-lr*J_grad_c d=d-lr*J_grad_d e=e-lr*J_grad_e f=f-lr*J_grad_f g=g-lr*J_grad_g h=h-lr*J_grad_h # 打印参数的值 if i % 1000 == 0: print(“iter=%d,” % i) print(“cost=%.3f” % J) print(“a=%.3f,” % a) print(“b=%.3f,” % b) print(“c=%.3f,” % c) print(“d=%.3f,” % d) print(“e=%.3f,” % e) print(“f=%.3f,” % f) print(“g=%.3f,” % g) print(“h=%.3f,” % h) print(“\n”) plt.plot(cost)训练结果如下: 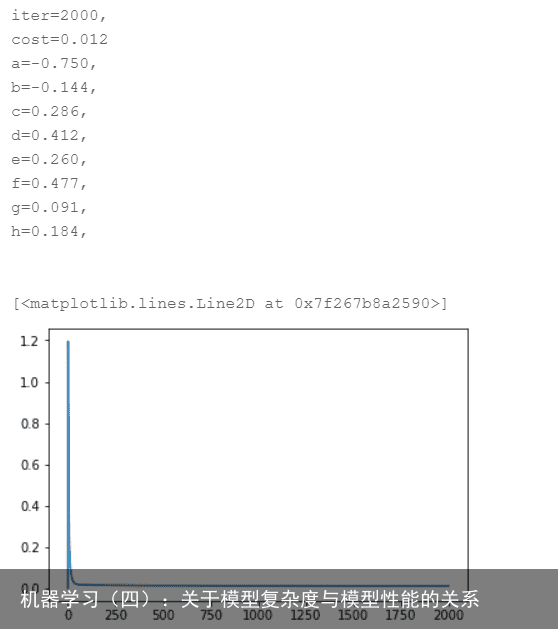
 算法收敛并且误差为0.012,优于上述所有模型。下面来看测试部分的结果: 代码:
算法收敛并且误差为0.012,优于上述所有模型。下面来看测试部分的结果: 代码:
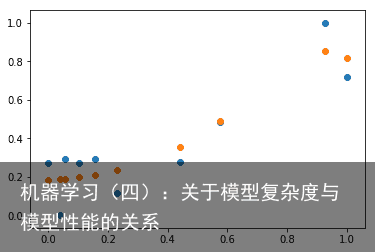
结果如下: 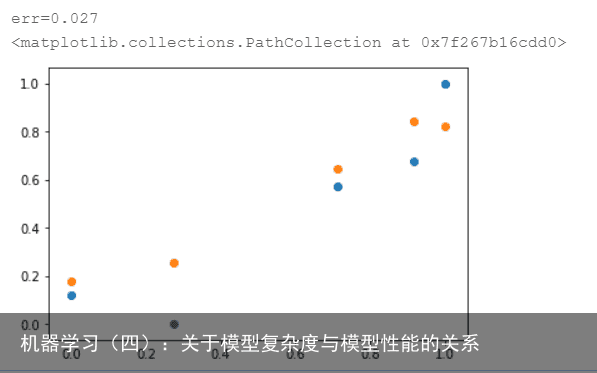 误差竟然高达0.027,效果与线性模型接近
误差竟然高达0.027,效果与线性模型接近
经过上述实验,我们发现,模型越复杂,训练集的误差越低,说明拟合结果确实越来越贴合训练数据,这是合乎情理的。但是我们同时发现,模型越复杂,测试集的误差不一定越低,甚至有可能变大。因此,模型复杂度越高,模型的性能不一定越好。那么我们有没有办法克服这个现象呢?下一篇文章,我们将介绍上述现象产生的原因以及解决方法。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:机器学习(四):关于模型复杂度与模型性能的关系 https://www.yhzz.com.cn/a/12961.html