根据微软官方的介绍,CNTK 是一个统一的计算网络框架,它将深层神经网络描述为一系列通过有向图的计算步骤。在有向图中,每个节点代表一个输入值或一个网络参数,每个边表示在其中的一个矩阵运算。CNTK 提供了实现前向计算和梯度计算的算法。CNTK中预定义了很多主流的计算网络结构,用户可以轻松地在开源许可证下扩展节点类型。社区可以利用它来更方便地来推进关于人工智能的研究。
注意安装CNTK在Linux系统需要安装依赖包,openMPI。 对比:
 从另一方面看到,由于CNTK在最近几年才被推出,在网上有关于CNTK的资料还是很有限的,并且很多新的资料均为英文版。我们缺乏本土的,有关CNTK框架的教学内容。在搜索引擎进行相关的搜索,排名靠前的结果均是介绍使用BrainScript来使用CNTK框架的文章。 在这里将会通过一个非常简单的 Python 脚本,来演示如何使用 CNTK ,初步认识 CNTK 在这个示例中,将会定义两个列表,并利用 CNTK 对这两个列表进行减法运算, 代码如下:
从另一方面看到,由于CNTK在最近几年才被推出,在网上有关于CNTK的资料还是很有限的,并且很多新的资料均为英文版。我们缺乏本土的,有关CNTK框架的教学内容。在搜索引擎进行相关的搜索,排名靠前的结果均是介绍使用BrainScript来使用CNTK框架的文章。 在这里将会通过一个非常简单的 Python 脚本,来演示如何使用 CNTK ,初步认识 CNTK 在这个示例中,将会定义两个列表,并利用 CNTK 对这两个列表进行减法运算, 代码如下:
这个示例虽然简单,但是演示了CNTK强大的向量矩阵运算。
2 Tensorflow2.1 介绍
Tensor Flow 是一个采用数据流图( Data Flow Graphs ),用于数值计算的开源软件库,节点( Node )在图中表示数学操作,图中的线( Edge )则表示在节点间相互联系的多维数据数组(Tensor), 它灵活的架构可以在多种平台上展开计算,台式计算机中的一个或多个 CPU (或 GPU )、服务器、移动设备等 。
2.2 安装
TensorFlow 2 软件包现已推出 tensorflow:支持 CPU 和 GPU 的最新稳定版(适用于 Ubuntu 和 Windows) tf-nightly:预览 build(不稳定)。Ubuntu 和 Windows 均包含 GPU 支持。 旧版 TensorFlow 对于 TensorFlow 1.x,CPU 和 GPU 软件包是分开的: tensorflow==1.15:仅支持 CPU 的版本 tensorflow-gpu==1.15:支持 GPU 的版本(适用于 Ubuntu 和 Windows) 系统要求 Python 3.5-3.8 若要支持 Python 3.8,需要使用 TensorFlow 2.2 或更高版本。 pip 19.0 或更高版本(需要 manylinux2010 支持) Ubuntu 16.04 或更高版本(64 位) macOS 10.12.6 (Sierra) 或更高版本(64 位)(不支持 GPU) Windows 7 或更高版本(64 位) 适用于 Visual Studio 2015、2017 和 2019 的 Microsoft Visual C++ 可再发行软件包 Raspbian 9.0 或更高版本 GPU 支持需要使用支持 CUDA® 的卡(适用于 Ubuntu 和 Windows)2.3 简单例子

输出4.0
3 Keras3.1 介绍
构建在CNTK和TensorFlow之上的类库。 Keras是一个非常方便的深度学习框架,它以TensorFlow或Theano为后端。用它可以快速地搭建深度网络,灵活地选取训练参数来进行网路训练。总之就是:灵活+快速!
3.2 安装Keras
# GPU 版本 >>> pip install –upgrade tensorflow-gpu # CPU 版本 >>> pip install –upgrade tensorflow # Keras 安装 >>> pip install keras -U –pre3.3 使用Keras构建深度学习模型

3.4 一个例子
# Regressor example # Code: https://github.com/keloli/KerasPractise/edit/master/Regressor.py import numpy as np np.random.seed(1337) from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt # 创建数据集 X = np.linspace(-1, 1, 200) np.random.shuffle(X) # 将数据集随机化 Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, )) # 假设我们真实模型为:Y=0.5X+2 # 绘制数据集plt.scatter(X, Y) plt.show() X_train, Y_train = X[:160], Y[:160] # 把前160个数据放到训练集 X_test, Y_test = X[160:], Y[160:] # 把后40个点放到测试集 # 定义一个model, model = Sequential () # Keras有两种类型的模型,序贯模型(Sequential)和函数式模型 # 比较常用的是Sequential,它是单输入单输出的 model.add(Dense(output_dim=1, input_dim=1)) # 通过add()方法一层层添加模型 # Dense是全连接层,第一层需要定义输入, # 第二层无需指定输入,一般第二层把第一层的输出作为输入 # 定义完模型就需要训练了,不过训练之前我们需要指定一些训练参数 # 通过compile()方法选择损失函数和优化器 # 这里我们用均方误差作为损失函数,随机梯度下降作为优化方法 model.compile(loss=mse, optimizer=sgd) # 开始训练 print(Training ———–) for step in range(301): cost = model.train_on_batch(X_train, Y_train) # Keras有很多开始训练的函数,这里用train_on_batch() if step % 100 == 0: print(train cost: , cost) # 测试训练好的模型 print(\nTesting ————) cost = model.evaluate(X_test, Y_test, batch_size=40) print(test cost:, cost) W, b = model.layers[0].get_weights() # 查看训练出的网络参数 # 由于我们网络只有一层,且每次训练的输入只有一个,输出只有一个 # 因此第一层训练出Y=WX+B这个模型,其中W,b为训练出的参数 print(Weights=, W, \nbiases=, b) # plotting the prediction Y_pred = model.predict(X_test) plt.scatter(X_test, Y_test) plt.plot(X_test, Y_pred) plt.show()训练结果: 最终的测试cost为:0.00313670327887,可视化结果如下图: 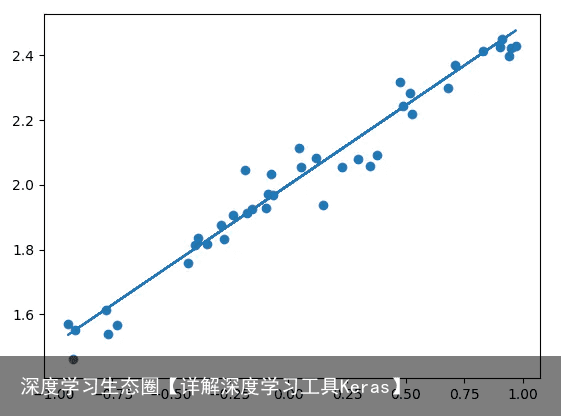
 我这里推荐阿里云的GPU服务器,我个人喜欢阿里云的服务!
我这里推荐阿里云的GPU服务器,我个人喜欢阿里云的服务!
进入阿里云官网。
在导航栏中选择“产品”-“云计算基础”-“GPU云服务器”
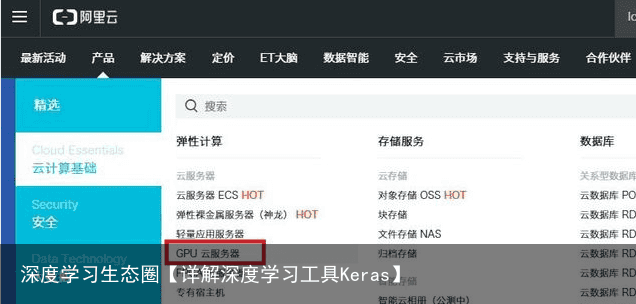
在云服务器界面选择“GN5(P100)购买” 接下来,我们便跳转到了阿里云服务器购买界面。默认情况下,系统为我们推荐“包年包月”的计费方式。每月上千的GPU租赁费用对大部分用户来说过于昂贵,而且我们只是偶尔会使用GPU计算服务,以月为单位租赁服务器有点浪费。 除了包年包月,我们还可以选择“按量付费”或者“抢占式实例”。按量付费是以小时为单位进行计费,计算完毕后需手动关闭服务器以停止计费。“抢占式实例”也是按小时计费,价格随市场波动,出价高的一批用户获得GPU服务器的使用权。
“抢占式实例”价格相对便宜,但当市场价格高于我们的出价时,我们的实例将会被释放,服务器将会被他人使用。不过使用“自动出价”可以让我们避免上述风险。
按量付费实例停机后不收费,抢占式网络虽然便宜,但必须释放实例实例后才会停止收费。
如果只是想体验一下,计费方式可选择“抢占式实例”。地域选择“华北5(呼和浩特)”会有优惠,价格大约在五到七块每小时(价格会随时间有些许波动)。读者若想以后长期间断使用服务器,一定要选“按量付费”,根据配置不同,价格在八到十三块每小时。(实际费用以秒为单位进行计算)  读者也可以选择使用“镜像市场”中的镜像。如下图中的镜像,已经预装了GPU驱动和tensorflow等框架。纯小白建议选择这个方法,此处就免去了文本第三步环境安装的过程。
读者也可以选择使用“镜像市场”中的镜像。如下图中的镜像,已经预装了GPU驱动和tensorflow等框架。纯小白建议选择这个方法,此处就免去了文本第三步环境安装的过程。  存储选择默认设置。本地存储440G空间会随着我们的实例释放后消除。一般我们的代码都放在系统盘,40G的系统盘满足大部分AI比赛或项目的存储需求。若有额外需求,读者可适当增加数据盘。这里保持默认不更改。
存储选择默认设置。本地存储440G空间会随着我们的实例释放后消除。一般我们的代码都放在系统盘,40G的系统盘满足大部分AI比赛或项目的存储需求。若有额外需求,读者可适当增加数据盘。这里保持默认不更改。
之后按照正常云服务配置流程使用即可。 就到这啦~
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:深度学习生态圈【详解深度学习工具Keras】 https://www.yhzz.com.cn/a/12676.html