多层感知器是最简单的神经网络模型,用于处理机器学习中的分在介绍单层感知器的时候,我们提到对于非线性可分问题,单层感知器是很难解决的,比如下面这个例子: 类与回归问题。 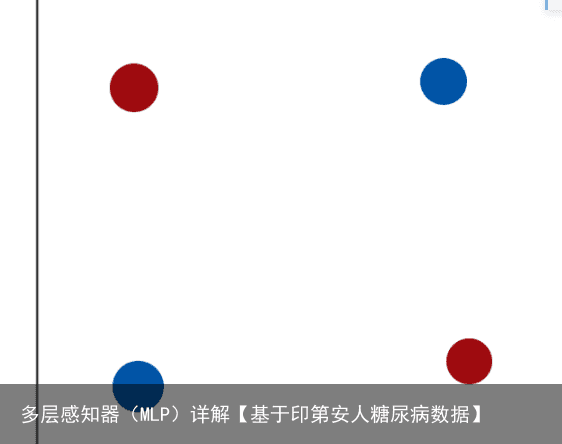 很简单的一个分布,但事实上就是无法用直线进行分类,后来就出现了多层感知器,主要改变的地方是把第一层的感知器的输出作为第二层感知器的输入,即使只是简单添加一层感知器,也足以解决xor问题,关键的原因是,多了一层感知器,就像对原来的输入做了一个映射,第一层感知器的目的是对输入进行映射使得数据在新的空间能够线性可分,然后我们再利用第二层感知器对数据进行分类,我们通过训练模型,使得第一层感知器能更好地重新映射原输入,第二层感知器能更好地分类。
很简单的一个分布,但事实上就是无法用直线进行分类,后来就出现了多层感知器,主要改变的地方是把第一层的感知器的输出作为第二层感知器的输入,即使只是简单添加一层感知器,也足以解决xor问题,关键的原因是,多了一层感知器,就像对原来的输入做了一个映射,第一层感知器的目的是对输入进行映射使得数据在新的空间能够线性可分,然后我们再利用第二层感知器对数据进行分类,我们通过训练模型,使得第一层感知器能更好地重新映射原输入,第二层感知器能更好地分类。
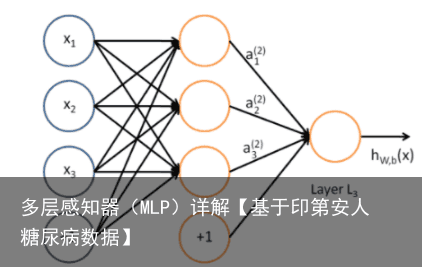 从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:
注:神经网络中的Sigmoid型激活函数:
1. 为嘛使用激活函数? a. 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。 b. 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。 激活函数需要具备以下几点性质: 1. 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参 数。 2. 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。 3. 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。多层感知器,又叫深度前馈网络、前馈神经网络。最左边的是输入层,就是我们的输入数据,最右边的是输出层,中间的就是隐藏层(因为训练数据并没有直接表明隐藏层的每一层的所需输出),实际上就是由感知器构成。从现在开始,感知器就开始称为神经元,而这整个包含了输入层、隐藏层和输出层的结构就是大名鼎鼎的神经网络。可以看到相邻层之间的神经元是全连接的。
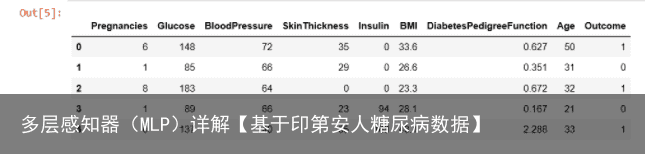
这个例子没有很多代码,本章将会一步一步地实现这个例子,以便清晰地展示如何 创建一个模型 将按照以下步骤创建第一个神经网络模型 导入数据 定义模型 编译模型 训练 评估 汇总代码 2 Pima印第安人数据集该数据集最初来自国家糖尿病/消化/肾脏疾病研究所。数据集的目标是基于数据集中包含的某些诊断测量来诊断性的预测患者是否患有糖尿病。 从较大的数据库中选择这些实例有几个约束条件。尤其是,这里的所有患者都是Pima印第安至少21岁的女性。 数据集由多个医学预测变量和一个目标变量组成Outcome。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。  数据前五行:
数据前五行: 
 分割数据集 前8列为输入。
分割数据集 前8列为输入。
我们先使用了初始化随机数种子,确保输出结果的可重复,然后完成了导入数据的操作。接下来就开始构建第一个神经网络模型。
4 定义模型
也就是指定优化器和学习率,loss等。
# 编译模型 model.compile(loss=binary_crossentropy, optimizer=adam, metrics=[accuracy]BCE二进制交叉熵作为损失函数。 公式分析 binary_crossentropy损失函数的公式如下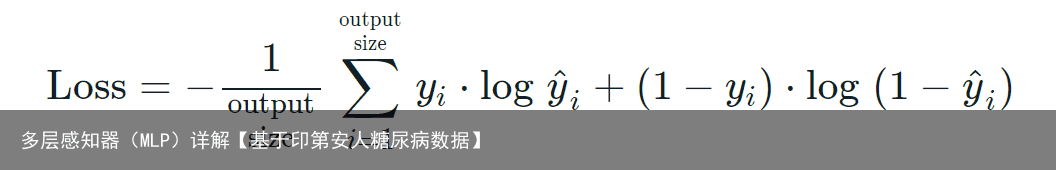 根据公式我们可以发现,i∈[1,output_size] 中每个i是相互独立的,互不干扰,因此它一般用于多标签分类(yolov3的分类损失函数就是用这个),比如说我们有标签 ‘人’,‘男人’, ‘女人’ ,如果使用categorical_crossentropy,由于它的数学公式含义,标签只能是其中一个,而binary_crossentropy各个i是相互独立的,意味着是有可能出现一下这种情况:(举例) ‘人’ 标签的概率是0.9, ‘男人’ 标签概率是0.6,‘女人’ 标签概率是0.3。 那么我们有足够的说服力断定他是 ‘人’,并且很可能是 ‘男人’。
根据公式我们可以发现,i∈[1,output_size] 中每个i是相互独立的,互不干扰,因此它一般用于多标签分类(yolov3的分类损失函数就是用这个),比如说我们有标签 ‘人’,‘男人’, ‘女人’ ,如果使用categorical_crossentropy,由于它的数学公式含义,标签只能是其中一个,而binary_crossentropy各个i是相互独立的,意味着是有可能出现一下这种情况:(举例) ‘人’ 标签的概率是0.9, ‘男人’ 标签概率是0.6,‘女人’ 标签概率是0.3。 那么我们有足够的说服力断定他是 ‘人’,并且很可能是 ‘男人’。
(一般搭配sigmoid激活函数使用): 其他的损失函数这里不做过多介绍。
6 训练
metrics_names[1]是ACC,scores[1]*100是ACC得分。 就到这啦,关于数据集网上随便一搜下载即可。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:多层感知器(MLP)详解【基于印第安人糖尿病数据】 https://www.yhzz.com.cn/a/12662.html