1.1 自动评估
在Keras中设置验证集大小实现。
#训练模型并自动评估模型 model . fit(x=x , y=Y , epochs=l50 , batch_ size=lO , validation_split=0.2)1.2 手动评估
x train, x validation, Y train, Y validation =train_test_split(x,Y,test_size=0.2 , random_state=seed)1.3 k折交叉验证
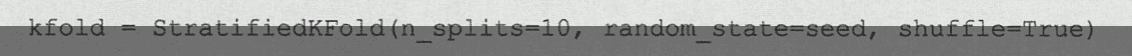
 代码中的循环会增加计算复杂程度,但是可以找到一个更优秀的模型。
代码中的循环会增加计算复杂程度,但是可以找到一个更优秀的模型。
代码使用KerasClassifier为例子: 目的是为了更好使用机器学习库中的一些方法。
from keras.models import Sequential from keras.layers import Dense import numpy as np from sklearn.model_selection import cross_val_score from sklearn.model_selection import StratifiedKFold from keras.wrappers.scikit_learn import KerasClassifier # 构建模型 def create_model(): # 构建模型 model = Sequential() model.add(Dense(units=12, input_dim=8, activation=relu)) model.add(Dense(units=8, activation=relu)) model.add(Dense(units=1, activation=sigmoid)) # 编译模型 model.compile(loss=binary_crossentropy, optimizer=adam, metrics=[accuracy]) return model seed = 7 # 设定随机数种子 np.random.seed(seed) # 导入数据 dataset = np.loadtxt(pima-indians-diabetes.csv, delimiter=,) # 分割输入x和输出Y x = dataset[:, 0 : 8] Y = dataset[:, 8] #创建模型 for scikit-learn model = KerasClassifier(build_fn=create_model, epochs=150, batch_size=10, verbose=0) # 10折交叉验证 kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(model, x, Y, cv=kfold) print(results.mean())这种自动化选择超参数的手段只适用于小型数据集哈。
from keras.models import Sequential from keras.layers import Dense import numpy as np from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # 构建模型 def create_model(optimizer=adam, init=glorot_uniform): # 构建模型 model = Sequential() model.add(Dense(units=12, kernel_initializer=init, input_dim=8, activation=relu)) model.add(Dense(units=8, kernel_initializer=init, activation=relu)) model.add(Dense(units=1, kernel_initializer=init, activation=sigmoid)) # 编译模型 model.compile(loss=binary_crossentropy, optimizer=optimizer, metrics=[accuracy]) return model seed = 7 # 设定随机数种子 np.random.seed(seed) # 导入数据 dataset = np.loadtxt(pima-indians-diabetes.csv, delimiter=,) # 分割输入x和输出Y x = dataset[:, 0 : 8] Y = dataset[:, 8] #创建模型 for scikit-learn model = KerasClassifier(build_fn=create_model, verbose=0) # 构建需要调参的参数 param_grid = {} param_grid[optimizer] = [rmsprop, adam] param_grid[init] = [glorot_uniform, normal, uniform] param_grid[epochs] = [50, 100, 150, 200] param_grid[batch_size] = [5, 10, 20] # 调参 grid = GridSearchCV(estimator=model, param_grid=param_grid) results = grid.fit(x, Y) # 输出结果 print(Best: %f using %s % (results.best_score_, results.best_params_)) means = results.cv_results_[mean_test_score] stds = results.cv_results_[std_test_score] params = results.cv_results_[params] for mean, std, param in zip(means, stds, params): print(%f (%f) with: %r % (mean, std, param))4.1 数据集分析
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
样本局部截图: 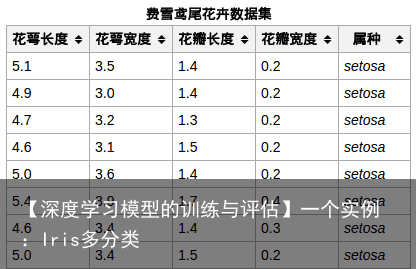 将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称),如图所示:
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称),如图所示: 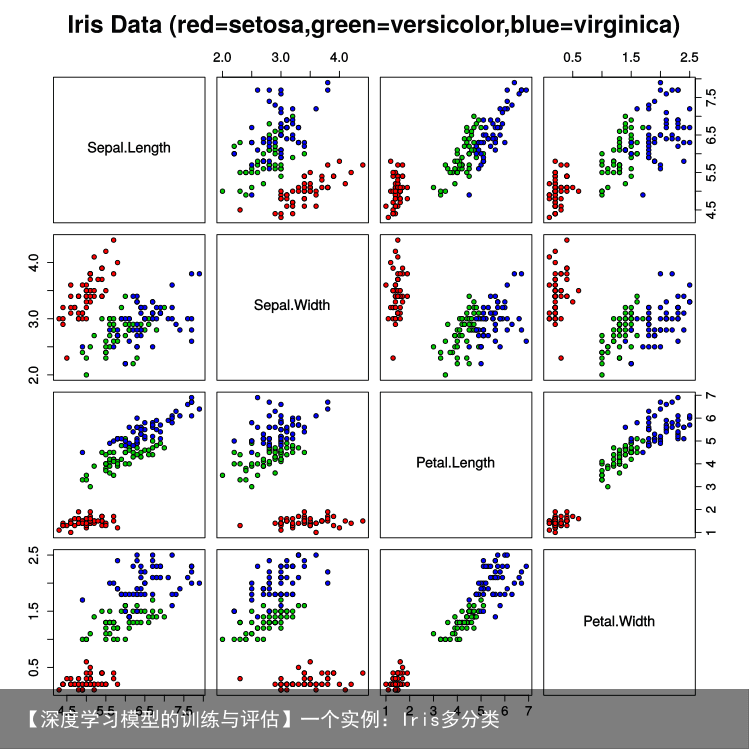
4.2 代码
from sklearn import datasets import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.wrappers.scikit_learn import KerasClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold # 导入数据 dataset = datasets.load_iris() x = dataset.data Y = dataset.target # 设定随机种子 seed = 7 np.random.seed(seed) # 构建模型函数 def create_model(optimizer=adam, init=glorot_uniform): # 构建模型 model = Sequential() model.add(Dense(units=4, activation=relu, input_dim=4, kernel_initializer=init)) model.add(Dense(units=6, activation=relu, kernel_initializer=init)) model.add(Dense(units=3, activation=softmax, kernel_initializer=init)) # 编译模型 model.compile(loss=categorical_crossentropy, optimizer=optimizer, metrics=[accuracy]) return model model = KerasClassifier(build_fn=create_model, epochs=200, batch_size=5, verbose=0) kfold = KFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(model, x, Y, cv=kfold) print(Accuracy: %.2f%% (%.2f) % (results.mean()*100, results.std()))解释: 不同的层可能使用不同的关键字来传递初始化方法,一般来说指定初始化方法的关键字是kernel_initializer 和 bias_initializer,例如:
model.add(Dense(64, kernel_initializer=random_uniform, bias_initializer=zeros))随机初始化+Batch Normalization np.random.randn()的结果是以0为均值、以1为标准差的正态分布,其值可正可负。
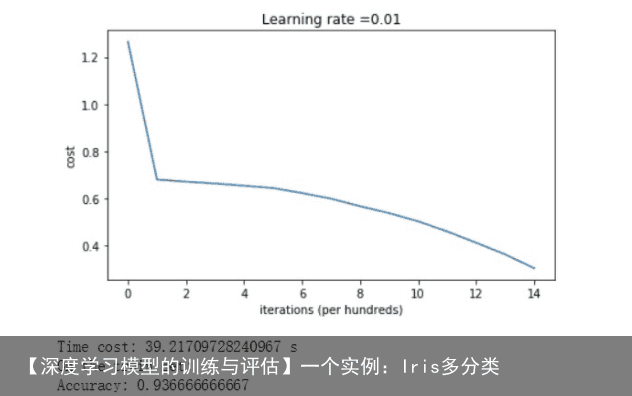
for l in range(1,L): W = np.random.randn(num_of_dim[l-1],num_of_dim[l]) b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)如图2所示,cost最后降到比较低,分类准确率为92%。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习模型的训练与评估】一个实例:Iris多分类 https://www.yhzz.com.cn/a/12656.html