文章目录 【深度学习】Keras实现回归和二分类问题讲解 1 回归问题 1.1 波士顿房价预测数据集 1.2 构建基准模型 1.3 数据预处理 1.4 超参数 2 二分类 2.1 银行营销分类数据集 2.2 预处理 2.3 构建基准模型 2.4 数据格式化 2.5 优化网络图 1 回归问题
1.1 波士顿房价预测数据集
波士顿房价预测是一个较为简单的数据回归问题,通过对已有数据的模拟,从而预测其他房子的房价。 波士顿房产数据集:使用sklearn.datasets.load_boston即可加载相关数据。该数据集共有 506 个观察,13 个输入变量和1个输出变量。 基于该数据对波士顿房产数据集做最简单的线性回归。
import pandas as pd import warnings warnings.filterwarnings(“ignore”) data = pd.read_csv(https://labfile.oss.aliyuncs.com/courses/1363/HousePrice.csv) data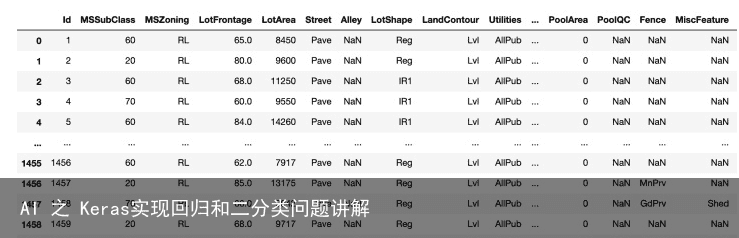

1.2 构建基准模型
from sklearn import datasets import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.wrappers.scikit_learn import KerasRegressor from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV # 导入数据 dataset = datasets.load_boston() x = dataset.data Y = dataset.target # 设定随机种子 seed = 7 np.random.seed(seed)

10折交叉验证:
# 设置算法评估基准 kfold = KFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(model, x, Y, cv=kfold) print(Baseline: %.2f (%.2f) MSE % (results.mean(), results.std()))1.3 数据预处理
保证输入的单位相同。
# 数据正态化,改进算法 steps = [] steps.append((standardize, StandardScaler())) steps.append((mlp, model)) pipeline = Pipeline(steps) kfold = KFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(pipeline, x, Y, cv=kfold) print(Standardize: %.2f (%.2f) MSE % (results.mean(), results.std()))1.4 超参数
# 调参 scaler = StandardScaler() scaler_x = scaler.fit_transform(x) grid = GridSearchCV(estimator=model, param_grid=param_grid) results = grid.fit(scaler_x, Y) # 输出结果 print(Best: %f using %s % (results.best_score_, results.best_params_)) means = results.cv_results_[mean_test_score] stds = results.cv_results_[std_test_score] params = results.cv_results_[params] for mean, std, param in zip(means, stds, params): print(%f (%f) with: %r % (mean, std, param)) 2 二分类2.1 银行营销分类数据集
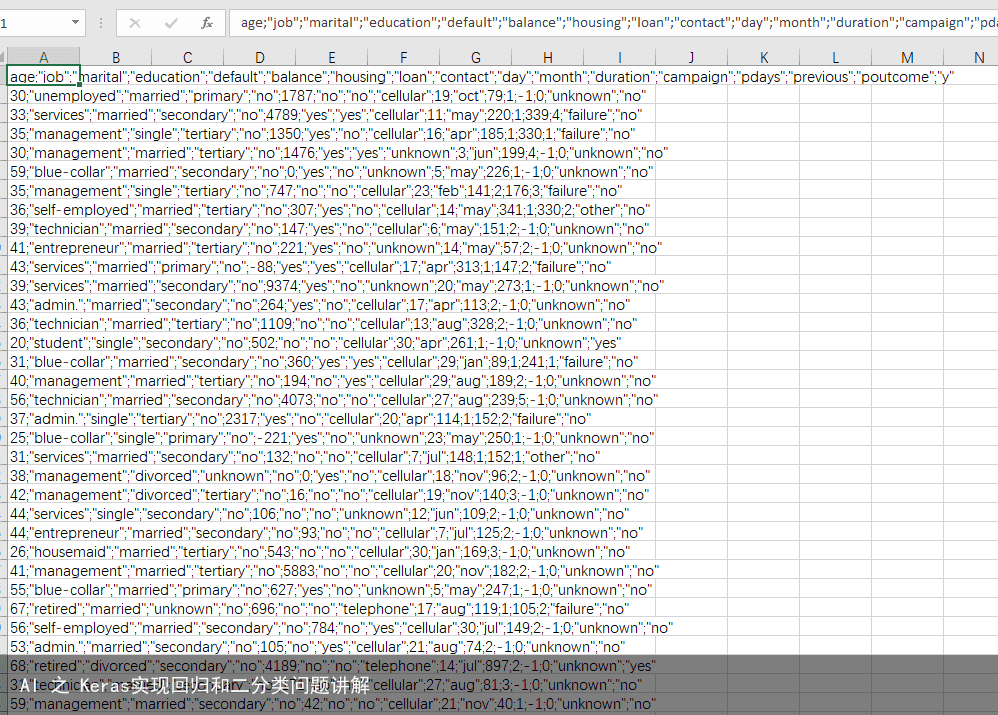
 影响是否购买产品的数据分为三个部分: 用户数据:age,job,maritial(是否结婚),education; 行为数据(信用):default(违约),balance(每年账户平均余额),hosing(房贷),loan(借贷) 业务数据:contact(联系方式),day(最后一次联系时间),month最后一次联系时间),duration(联系持续时间),campaign(活动中与客户交流的次数),pdays(距离上次联系的天数),previous(本次活动之前,与客户交流的次数),poutcome (上次活动结果)
影响是否购买产品的数据分为三个部分: 用户数据:age,job,maritial(是否结婚),education; 行为数据(信用):default(违约),balance(每年账户平均余额),hosing(房贷),loan(借贷) 业务数据:contact(联系方式),day(最后一次联系时间),month最后一次联系时间),duration(联系持续时间),campaign(活动中与客户交流的次数),pdays(距离上次联系的天数),previous(本次活动之前,与客户交流的次数),poutcome (上次活动结果)
2.2 预处理
import numpy as np from keras.models import Sequential from keras.layers import Dense from keras.wrappers.scikit_learn import KerasClassifier from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler from sklearn.model_selection import GridSearchCV from pandas import read_csv # 导入数据并将分类转化为数字 dataset = read_csv(bank.csv, delimiter=;) dataset[job] = dataset[job].replace(to_replace=[admin., unknown, unemployed, management, housemaid, entrepreneur, student, blue-collar, self-employed, retired, technician, services], value=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) dataset[marital] = dataset[marital].replace(to_replace=[married, single, divorced], value=[0, 1, 2]) dataset[education] = dataset[education].replace(to_replace=[unknown, secondary, primary, tertiary], value=[0, 2, 1, 3]) dataset[default] = dataset[default].replace(to_replace=[no, yes], value=[0, 1]) dataset[housing] = dataset[housing].replace(to_replace=[no, yes], value=[0, 1]) dataset[loan] = dataset[loan].replace(to_replace=[no, yes], value=[0, 1]) dataset[contact] = dataset[contact].replace(to_replace=[cellular, unknown, telephone], value=[0, 1, 2]) dataset[poutcome] = dataset[poutcome].replace(to_replace=[unknown, other, success, failure], value=[0, 1, 2, 3]) dataset[month] = dataset[month].replace(to_replace=[jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec], value=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]) dataset[y] = dataset[y].replace(to_replace=[no, yes], value=[0, 1]) # 分离输入输出 array = dataset.values x = array[:, 0:16] Y = array[:, 16] # 设置随机种子 seed = 7 np.random.seed(seed)<
2.3 构建基准模型
# 构建模型函数 def create_model(units_list=[16], optimizer=adam, init=normal): # 构建模型 model = Sequential() # 构建第一个隐藏层和输入层 units = units_list[0] model.add(Dense(units=units, activation=relu, input_dim=16, kernel_initializer=init)) # 构建更多隐藏层 for units in units_list[1:]: model.add(Dense(units=units, activation=relu, kernel_initializer=init)) model.add(Dense(units=1, activation=sigmoid, kernel_initializer=init)) # 编译模型 model.compile(loss=binary_crossentropy, optimizer=optimizer, metrics=[accuracy]) return model model = KerasClassifier(build_fn=create_model, epochs=200, batch_size=5, verbose=0) kfold = KFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(model, x, Y, cv=kfold) print(Accuracy: %.2f%% (%.2f) % (results.mean() * 100, results.std()))<
2.4 数据格式化
new_x = StandardScaler().fit_transform(x) kfold = KFold(n_splits=10, shuffle=True, random_state=seed) results = cross_val_score(model, new_x, Y, cv=kfold) print(Accuracy: %.2f%% (%.2f) % (results.mean() * 100, results.std()))2.5 优化网络图
最牛逼的方案。
# 调参选择最优模型 param_grid = {} param_grid[units_list] = [[16], [30], [16, 8], [30, 8]] # 调参 grid = GridSearchCV(estimator=model, param_grid=param_grid) results = grid.fit(new_x, Y) # 输出结果 print(Best: %f using %s % (results.best_score_, results.best_params_)) means = results.cv_results_[mean_test_score] stds = results.cv_results_[std_test_score] params = results.cv_results_[params] for mean, std, param in zip(means, stds, params): print(%f (%f) with: %r % (mean, std, param))免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:AI 之 Keras实现回归和二分类问题讲解 https://www.yhzz.com.cn/a/12639.html