图像是二维或三维景物呈现在人们眼中的影像。例如人眼所见景物,照片,电视电影等。
更确切地说,图像是用各种观测系统以不同形式和手段观测客观世界而获得的,可以直接或间接作用于人眼并进而产生视知觉的实体 。 数字图像的定义
数字图像是指物理图像的连续信号值被离散化后,由被称作像素的小块区域组成的二维矩阵。将物理图像行列划分后,每个小块区域称为像素(Pixel)。每个像素包括两个属性:位置和色彩(或亮度) 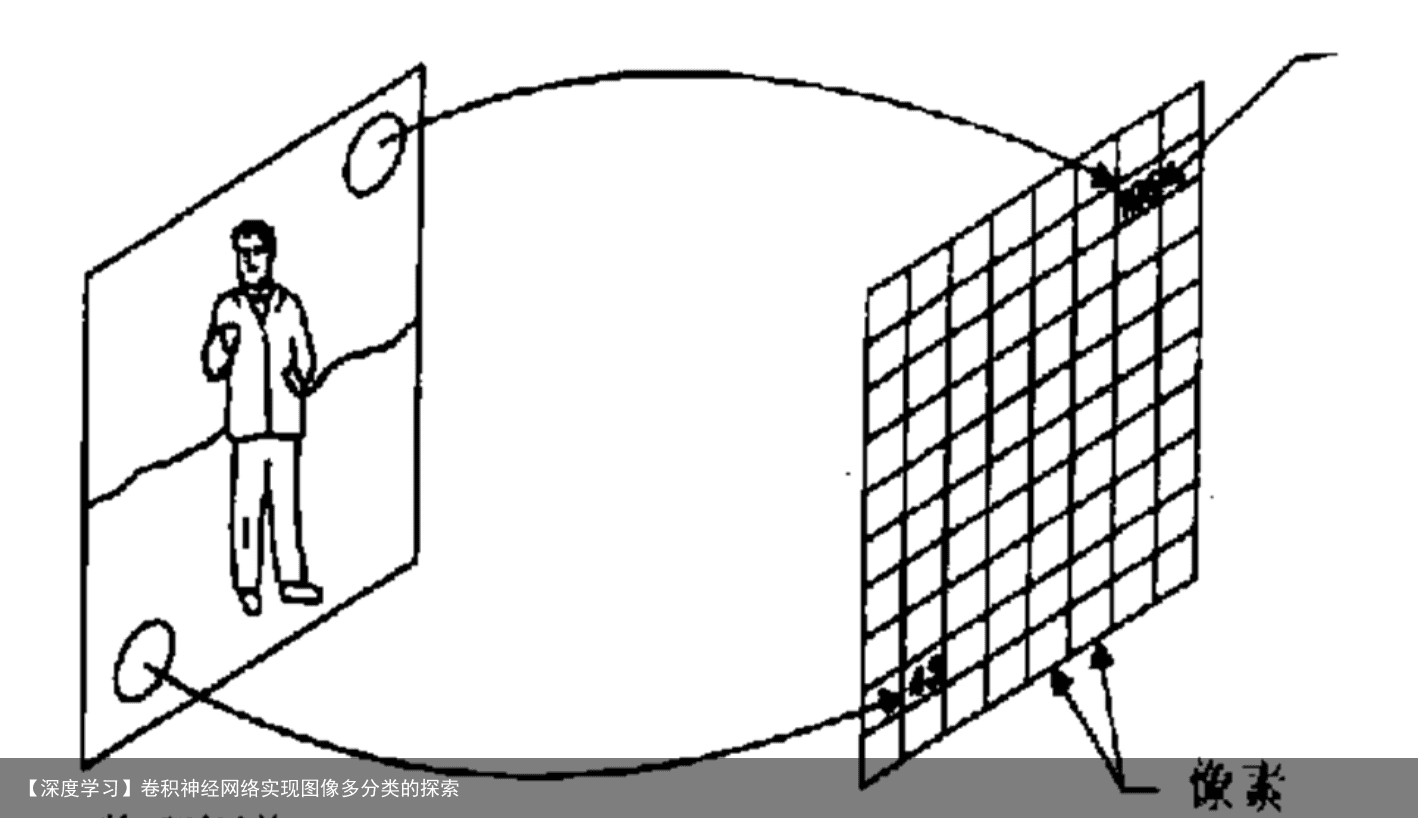
灰度图像实例 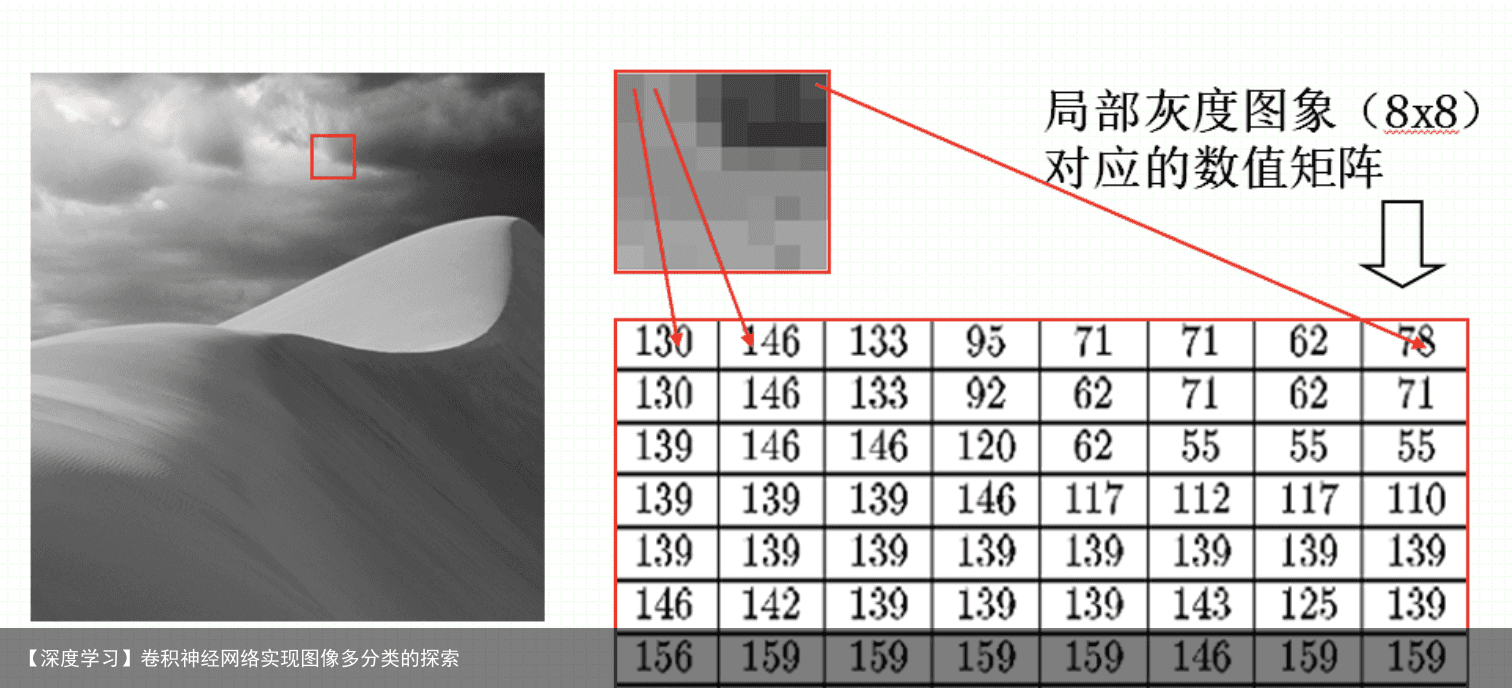 彩色图像
彩色图像 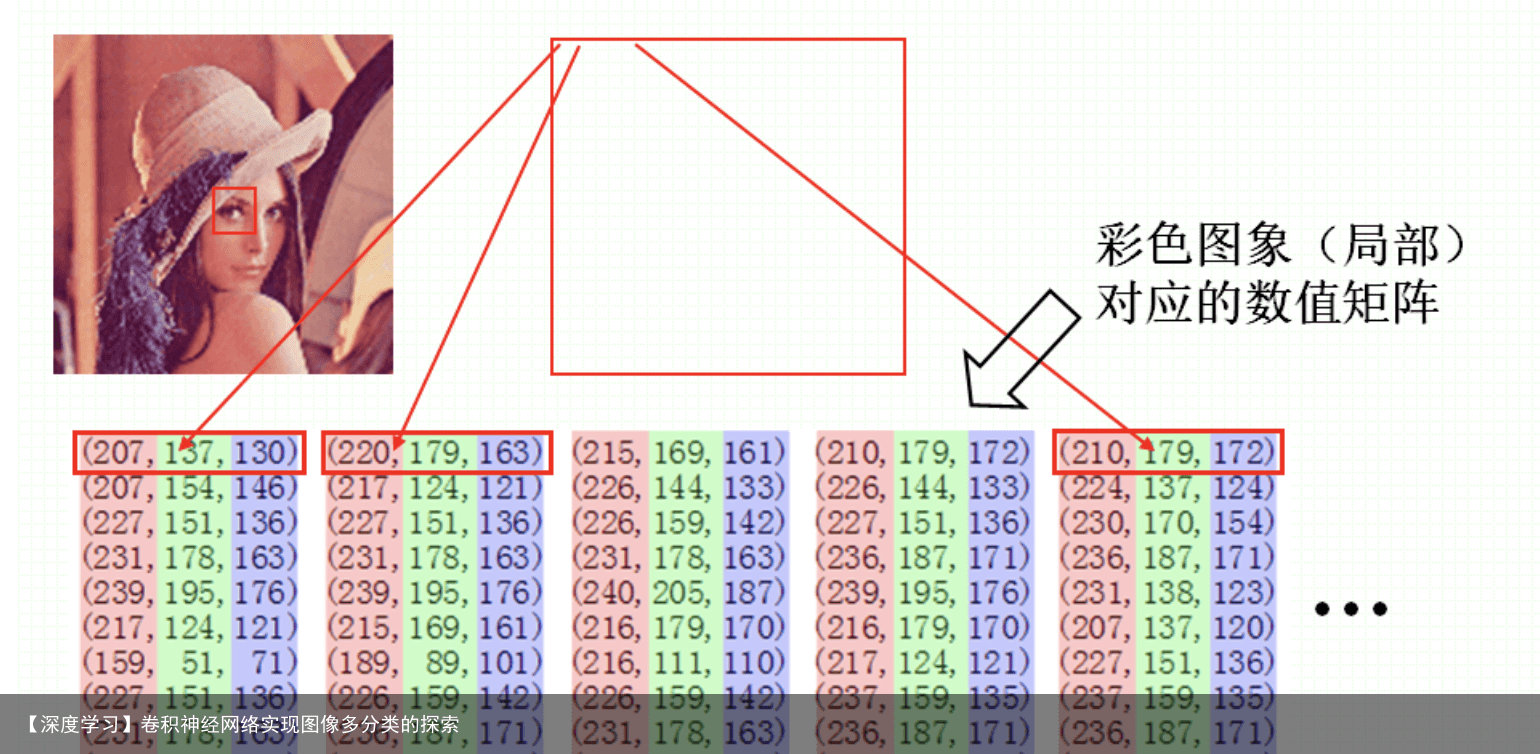
通常,三元组的每个数值也是在0到255之间,0表示相应的基色在该像素中没有,而255则代表相应的基色在该像素中取得最大值。 图像的离散化
由一幅物理图像(信号值连续)获取一幅满足需求的数字图像的离散化过程称为图像数字化。这里涉及到两个重要的概念:采样与量化。采样——位置离散化
物理图像在空间位置上连续点的离散化被称为图像采样,采样确定水平和垂直方向上的像素个数I、J。
 上图:I = 20,J = 14 水平方向采样20 个点, 垂直方向采样14个点 分辨率:单位长度上采样的像素个数,DPI(dot/inch)。
上图:I = 20,J = 14 水平方向采样20 个点, 垂直方向采样14个点 分辨率:单位长度上采样的像素个数,DPI(dot/inch)。
采样越密、分辨率越高、图像越清晰、存储量也越大~!
1611采样  3322采样 😩 66*45采样 😩 就不一一截图了 总之越来越清晰就对了
3322采样 😩 66*45采样 😩 就不一一截图了 总之越来越清晰就对了  量化——色彩/亮度离散化(矩阵)
量化——色彩/亮度离散化(矩阵)
量化是图像在采样后,将图像色彩/亮度浓淡的连续变化值离散化为整数值的过程。 黑白图: 用一个二进制位1和0表示纯白、纯黑两种情况。
灰度图: 亮度的量化级为256。
真彩图: R、G、B三种基色量化级均为256。
量化级越高、色彩越丰富、存储量也越大。
2 cifar10数据集踩坑CIFAR-10数据集由10个类的60000个32×32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。 数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类的恰好1000个随机选择的图像。训练批次包含随机顺序的图像,但一些训练批次可能包含来自一个种类的图像比另一个类更多。总的训练批次包含来自每个类的正好5000张图像。 以下是数据集中的类,以及来自每个类的10个随机图像:

一种网络优化(这里不详细说明): 
3.1 导入数据
import numpy as np from keras.datasets import cifar10 from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import Flatten from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.optimizers import SGD from keras.constraints import maxnorm from keras.utils import np_utils from keras import backend backend.set_image_data_format(channels_first) # 设定随机种子 seed = 7 np.random.seed(seed=seed) # 导入数据 (X_train, y_train), (X_validation, y_validation) = cifar10.load_data() # 格式化数据到0-1之前 X_train = X_train.astype(float32) X_validation = X_validation.astype(float32) X_train = X_train / 255.0 X_validation = X_validation / 255.0 # one-hot编码 y_train = np_utils.to_categorical(y_train) y_validation = np_utils.to_categorical(y_validation) num_classes = y_train.shape[1]
3.2 浅层CNN


input_shape是3,32,32的彩色图像。
def create_model(epochs=25): model = Sequential() model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), padding=same, activation=relu, kernel_constraint=maxnorm(3))) model.add(Dropout(0.2)) model.add(Conv2D(32, (3, 3), activation=relu, padding=same, kernel_constraint=maxnorm(3))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(512, activation=relu, kernel_constraint=maxnorm(3))) model.add(Dropout(0.5)) model.add(Dense(10, activation=softmax)) lrate = 0.01 decay = lrate / epochs sgd = SGD(lr=lrate, momentum=0.9, decay=decay, nesterov=False) model.compile(loss=categorical_crossentropy, optimizer=sgd, metrics=[accuracy]) return model Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
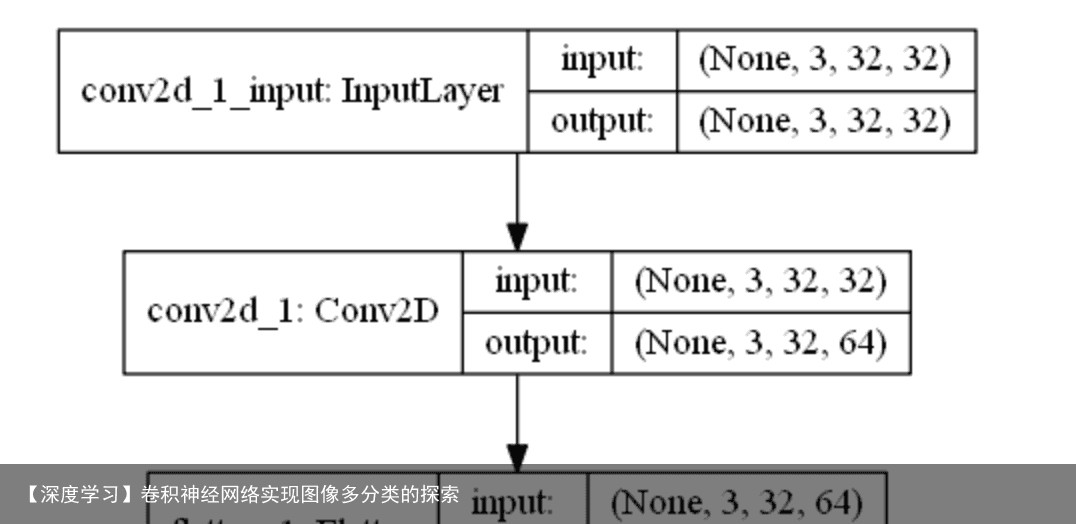 上图Flatten最终输出是33264=6144.
上图Flatten最终输出是33264=6144.
3.3 深层CNN


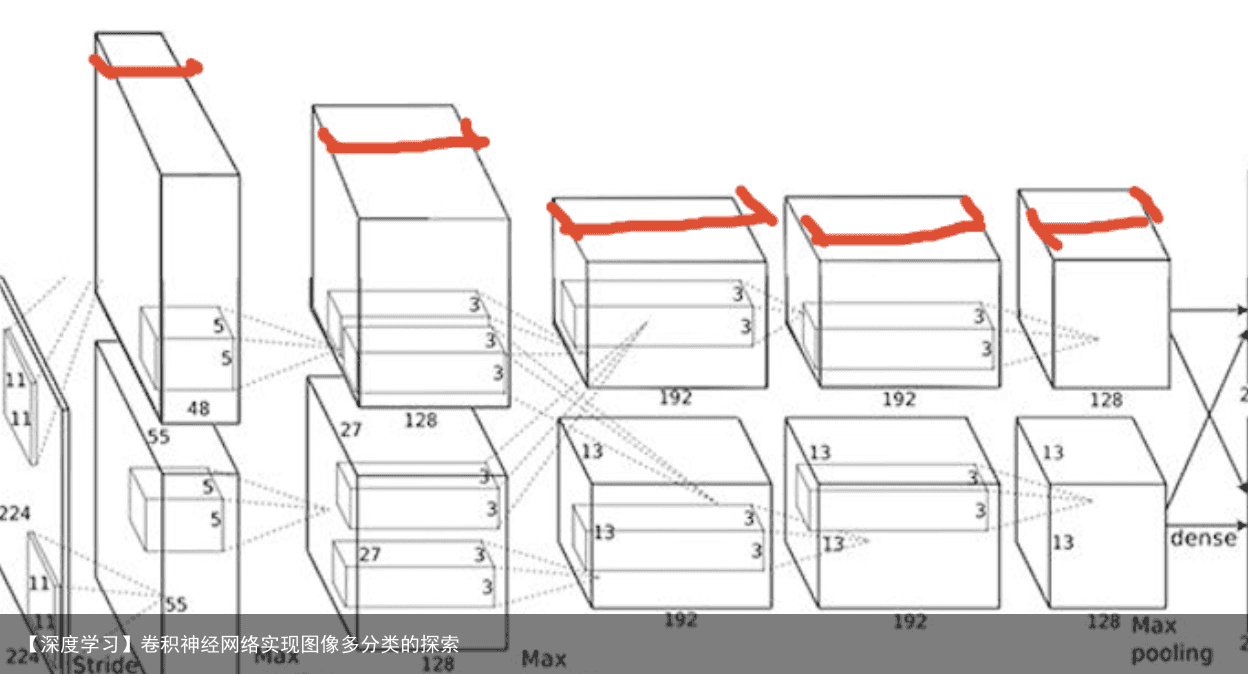
feature map(下图红线标出) 即:该层卷积核的个数,有多少个卷积核,经过卷积就会产生多少个feature map,
也就是下图中 豆腐皮儿的层数、同时也是下图豆腐块的深度(宽度)!!这个宽度可以手动指定,一般网络越深的地方这个值越大,因为随着网络的加深,feature map的长宽尺寸缩小,本卷积层的每个map提取的特征越具有代表性(精华部分),所以后一层卷积层需要增加feature map的数量,才能更充分的提取出前一层的特征,一般是成倍增加(不过具体论文会根据实验情况具体设置)! 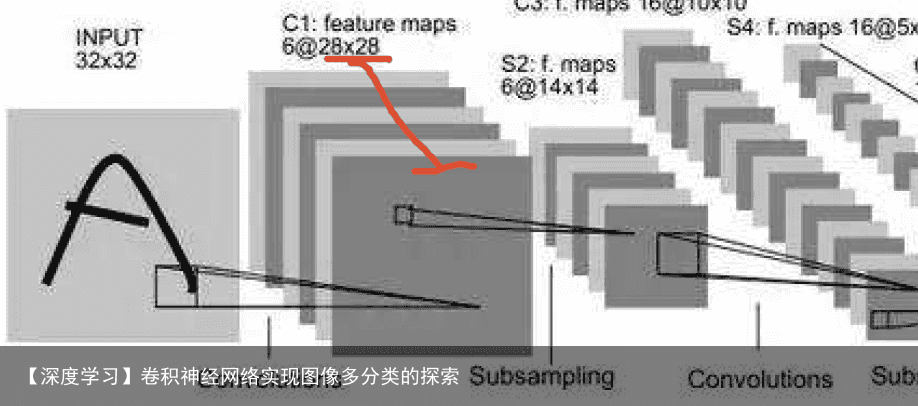
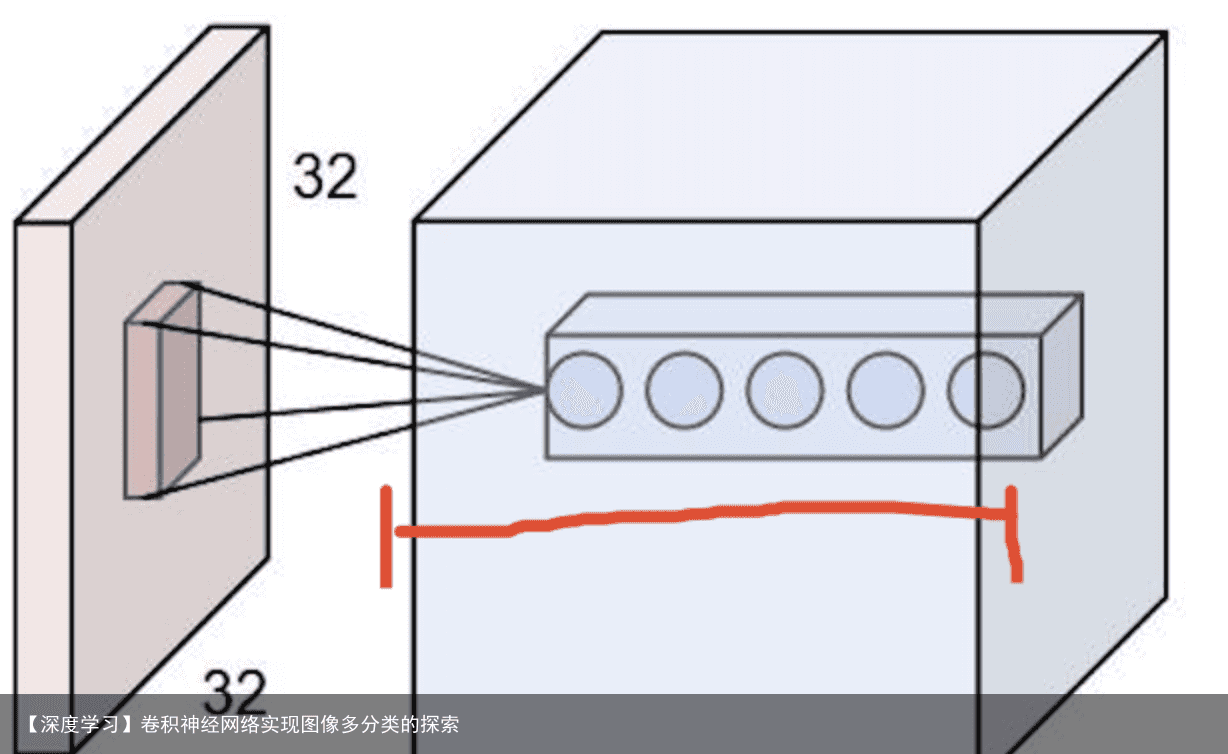
3.4 进一步改进



上面的model并没有添加dense层哦。! 就到这啦。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】卷积神经网络实现图像多分类的探索 https://www.yhzz.com.cn/a/12619.html