OpenCV是一个用于图像处理、分析、机器视觉方面的开源函数库.
无论你是做科学研究,还是商业应用,opencv都可以作为你理想的工具库,因为,对于这两者,它完全是免费的。
该库采用C及C++语言编写,可以在windows, linux, mac OSX系统上面运行。该库的所有代码都经过优化,计算效率很高,因为,它更专注于设计成为一种用于实时系统的开源库。opencv采用C语言进行优化,而且,在多核机器上面,其运行速度会更快。它的一个目标是提供友好的机器视觉接口函数,从而使得复杂的机器视觉产品可以加速面世。该库包含了横跨工业产品检测、医学图像处理、安防、用户界面、摄像头标定、三维成像、机器视觉等领域的超过500个接口函数。 同时,由于计算机视觉与机器学习密不可分,该库也包含了比较常用的一些机器学习算法。或许,很多人知道,图像识别、机器视觉在安防领域有所应用。但,很少有人知道,在航拍图片、街道图片(例如google street view)中,要严重依赖于机器视觉的摄像头标定、图像融合等技术。 近年来,在入侵检测、特定目标跟踪、目标检测、人脸检测、人脸识别、人脸跟踪等领域,opencv可谓大显身手,而这些,仅仅是其应用的冰山一角。 如今,来自世界各地的各大公司、科研机构的研究人员,共同维护支持着opencv的开源库开发。这些公司和机构包括:微软,IBM,索尼、西门子、google、intel、斯坦福、MIT、CMU、剑桥。。。 安装:
apt-get install python3-matplotlibapt-get install python-OpenCV 1 读取图像 import numpy as np import matplotlib.pyplot as plt import cv2 %matplotlib inline img = cv2.imread(xxx.jpg) print(img.shape) plt.imshow(img)opencv 默认使用 BGR编码,相比RGB,第三个维度是反的,需要转换为 RGB。
# 方法1. 直接操作数组 fig = plt.figure(figsize=(10, 6)) ax1 = fig.add_subplot(121) ax2 = fig.add_subplot(122) ax1.imshow(img[:,:,np.array([2,1,0])]) # 方法2. 调用 opencv 函数 ax2.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) 2 修改图像尺寸 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img_gray_small = cv2.resize(img_gray, (360, 240)) plt.imshow(img_gray_small, cmap=”gray”) 3 矩阵操作处理图像3.1 剪切图像
ball = img[280:340, 330:390] img[273:333, 100:160] = ball cv2.putText(img,”Messi”,(10,50), cv2.FONT_HERSHEY_PLAIN, 4,(255,255,255),2,cv2.LINE_AA) plt.imshow(img[:,:,np.array([2,1,0])])3.2 二维码转矩阵代码(部分)
import seaborn as sns import tensorflow as tf from sklearn.cluster import KMeans sns.set_style(white) def QR_code_to_mat(img_input, num_out): np_rawToQr_idx = np.linspace(0, num_out-0.1, img_input.shape[0]).astype(np.int) np_rawToQr_mesh = np.meshgrid(np_rawToQr_idx,np_rawToQr_idx) np_QR_counts = np.zeros([num_out, num_out]) for row_idx in range(img_input.shape[0]): for col_idx in range(img_input.shape[1]): col_num_25 = np_rawToQr_mesh[0][row_idx][col_idx] row_num_25 = np_rawToQr_mesh[1][row_idx][col_idx] #print(row_idx, col_idx) if img_input[row_idx][col_idx] == 255: np_QR_counts[row_num_25][col_num_25] += 1 return np_QR_counts def AvgPool(img_input, num_out): mat_input = tf.placeholder(tf.float32) k_size = int(img_input.shape[0]/num_out)+1 op = tf.nn.avg_pool(value=mat_input, ksize=[1,9,9,1], strides=[1, 9, 9, 1], padding=SAME) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) res = (sess.run(op, feed_dict={mat_input: img_input[np.newaxis,:,:,np.newaxis]})) bigger_label = 1 kmeans = KMeans(n_clusters=2, random_state=0).fit(res.ravel().reshape(-1,1)) if kmeans.cluster_centers_[0] > kmeans.cluster_centers_[1]: bigger_label = 0 threshold = min(res.ravel()[kmeans.labels_==bigger_label]) return res[0,:,:,0] > threshold np_25_counts = QR_code_to_mat(img_jizhiQR, 25) np_25_counts_tf = AvgPool(img_jizhiQR, 25) fig = plt.figure(figsize=(15,5)) ax1 = fig.add_subplot(131) ax2 = fig.add_subplot(132) ax3 = fig.add_subplot(133) sns.distplot(np_25_counts.ravel(), ax=ax1) ax2.imshow(np_25_counts>40, cmap=”gray”) ax3.imshow(np_25_counts_tf, cmap=”gray”)作者系统的研究了网络深度(Depth)、宽度(Width)和分辨率(resolution)对网络性能的影响,然后提出了一个新的缩放方法–使用简单但高效的复合系数均匀地缩放深度/宽度/分辨率的所有尺寸,在MobileNets 和 ResNet上证明了有效性。
同时,使用神经架构搜索来设计新的baseline并进行扩展以获得一系列模型,称EfficientNets,比之前的ConvNets更accuracy和更efficiency。其中EfficientNet-B7实现了ImageNet的state-of-the-art,即84.4% top-1 / 97.1% top-5 accuracy,同时该模型比现存最好的ConvNets的size小8.4倍,速度快6.1倍。
模型扩展Model scaling一直以来都是提高卷积神经网络效果的重要方法。 比如说,ResNet可以增加层数从ResNet18扩展到ResNet200。这次,我们要介绍的是最新的网络结构——EfficientNet,就是一种标准化的模型扩展结果,通过下面的图,我们可以体会到EfficientNet b0-b7在ImageNet上的效果:对于ImageNet历史上的各种网络而言,可以说EfficientNet在效果上实现了碾压 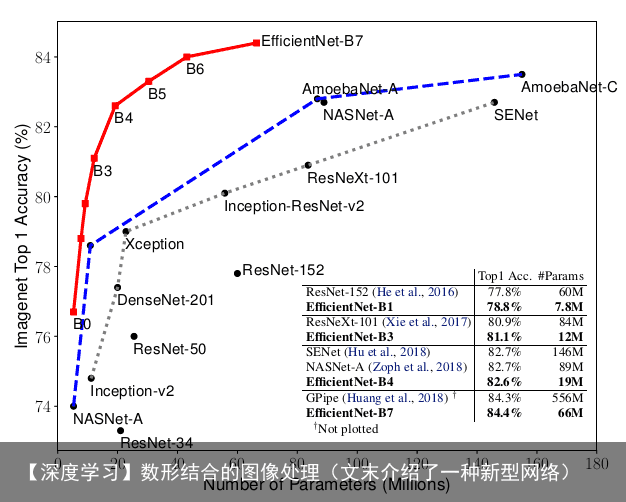
5.1 相关介绍
对网络的扩展可以通过增加网络层数(depth,比如从 ResNet (He et al.)从resnet18到resnet200 ), 也可以通过增加宽度,比如WideResNet (Zagoruyko & Komodakis, 2016)和Mo-bileNets (Howard et al., 2017) 可以扩大网络的width (#channels), 还有就是更大的输入图像尺寸(resolution)也可以帮助提高精度。如下图所示: (a)是基本模型,(b)是增加宽度,(c)是增加深度,(d)是增大属兔图像分辨率,(d)是EfficientNet,它从三个维度均扩大了,但是扩大多少,就是通过作者提出来的复合模型扩张方法结合神经结构搜索技术获得的。
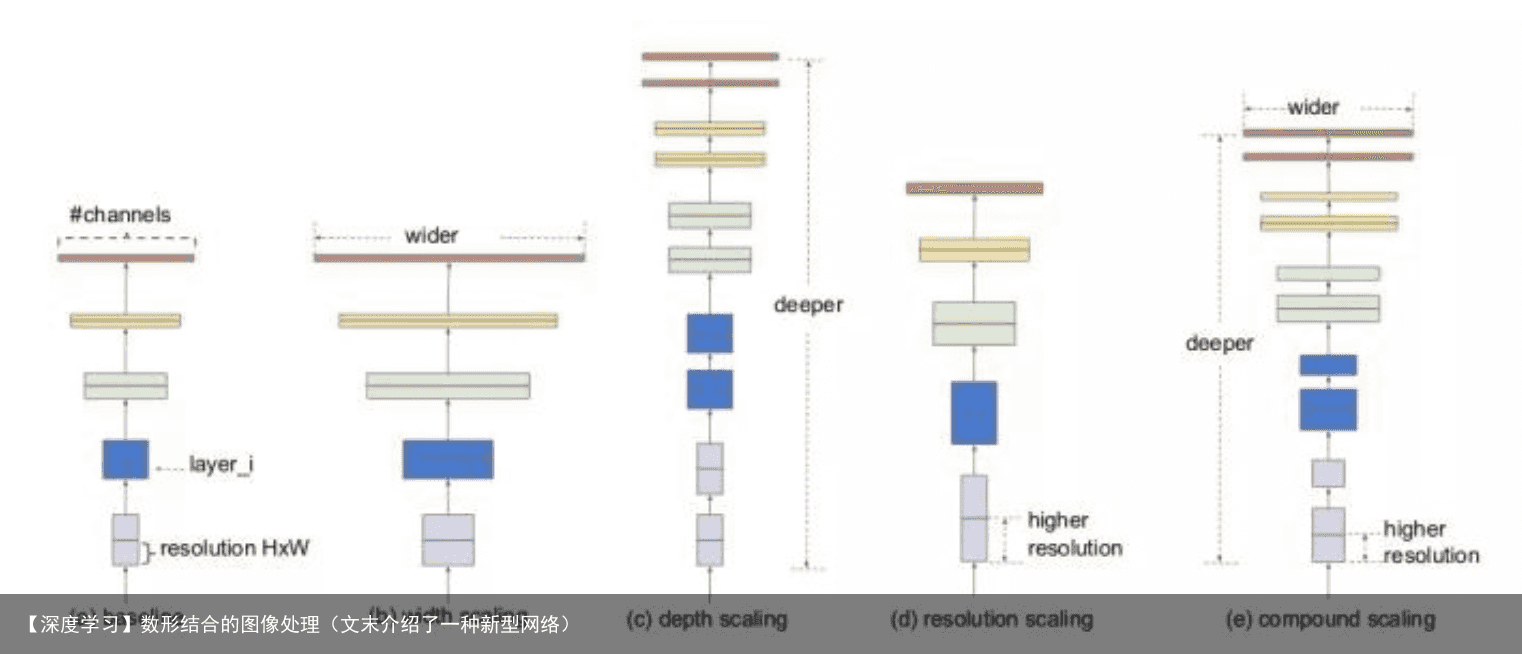 现在我们已经知道了,作者是要从depth, width, resolution 这三个维度去缩放模型,现在来看看具体是怎么做的。
现在我们已经知道了,作者是要从depth, width, resolution 这三个维度去缩放模型,现在来看看具体是怎么做的。
5.2 如何高效的进行多尺度特征融合(efficient multi-scale feature fusion)
提到多尺度融合,在融合不同的输入特征时,以往的研究(FPN以及一些对FPN的改进工作)大多只是没有区别的将特征相加;然而,由于这些不同的输入特征具有不同的分辨率,我们观察到它们对融合输出特征的贡献往往是不平等的,为了解决这一问题,作者提出了一种简单而高效的加权(类似与attention)双向特征金字塔网络(BiFPN),它引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自下而上的多尺度特征融合。
BiFPN结构
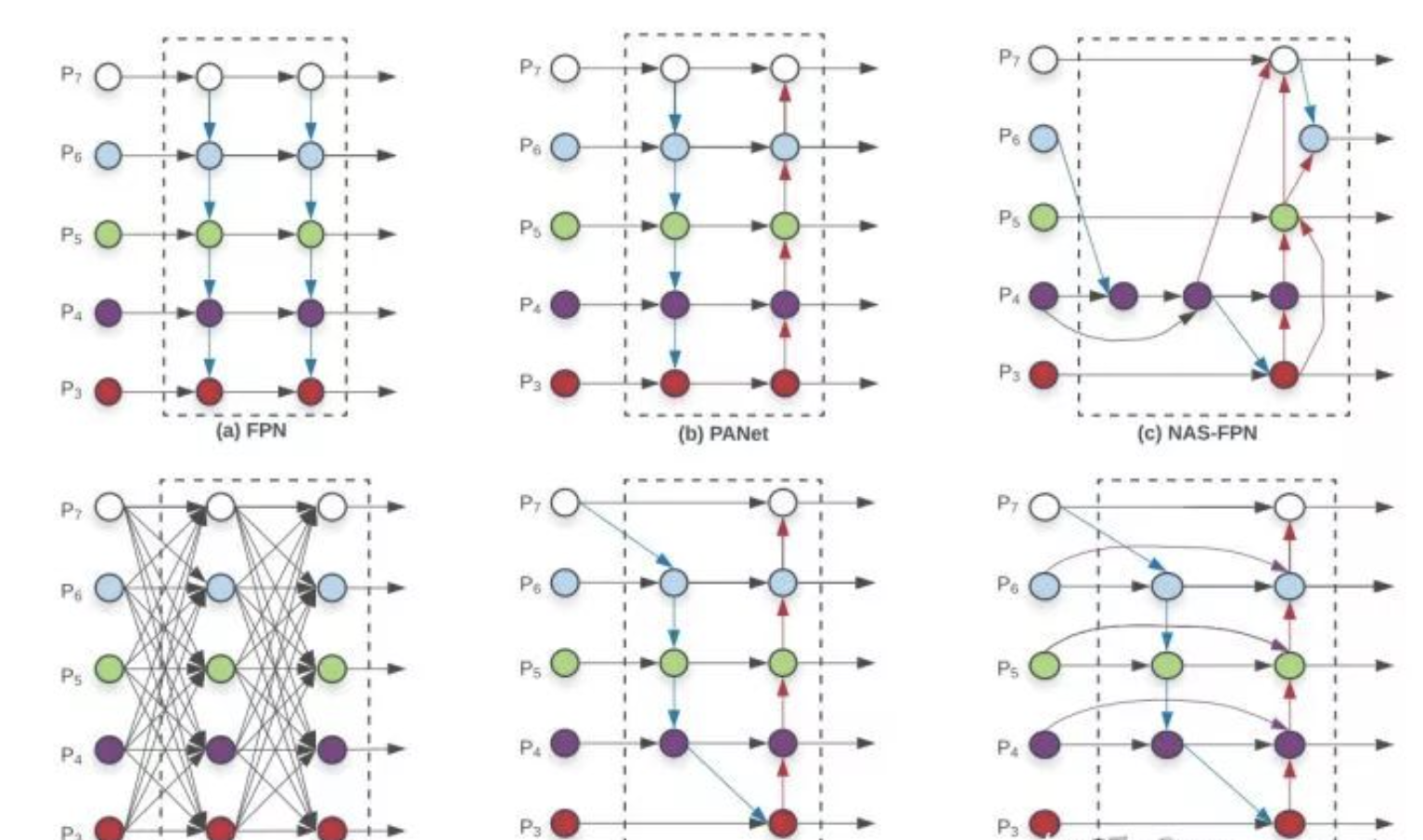
5.3 EfficientDet结构
组合了backbone(使用了EfficientNet)和BiFPN(特征网络)和Box prediction net,整个框架就是EfficientDet的基本模型,结构如下图:
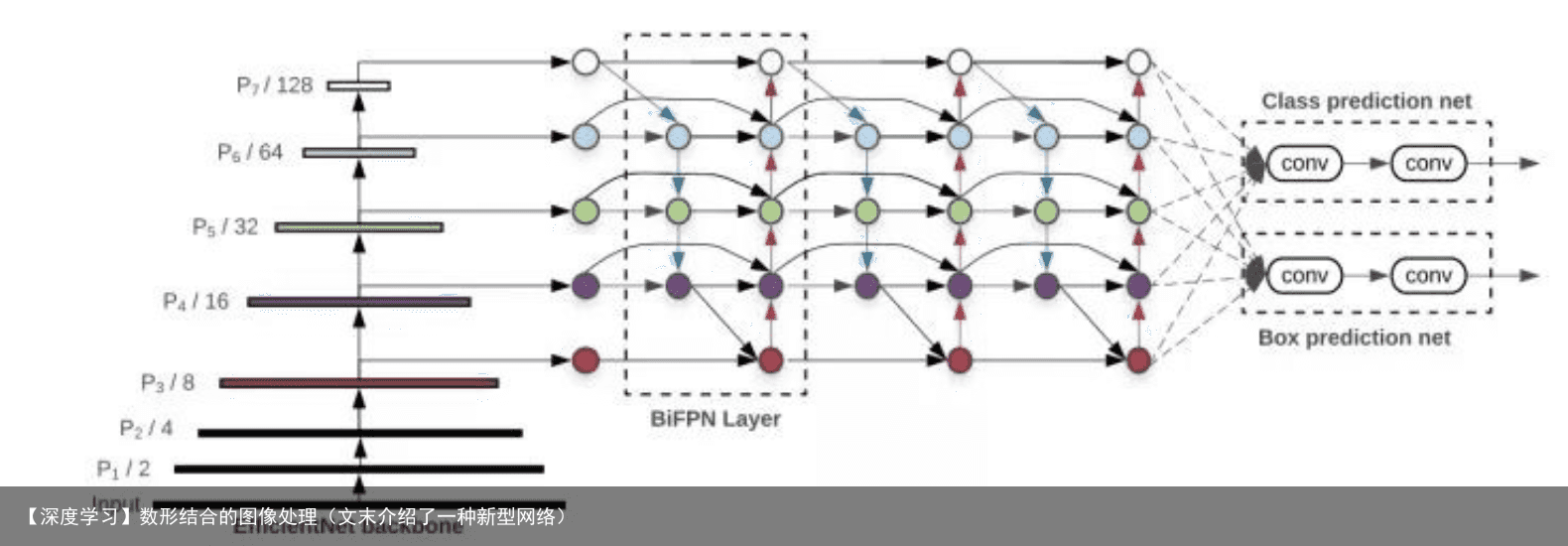
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】数形结合的图像处理(文末介绍了一种新型网络) https://www.yhzz.com.cn/a/12615.html