1.1 Dense
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer=glorot_uniform, bias_initializer=zeros, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Dense layer 就是常提到和用到的全连接层 。Dense 实现的操作为:output = activation(dot(input, kernel) + bias) 其中 activation 是按逐个元素计算的激活函数,kernel 是由网络层创建的权值矩阵,以及 bias 是其创建的偏置向量 (只在 use_bias=True 时才有用)。
全连接层(Dense) 就是Linear层,即y= wx+b,计算乘法以及加法。由于矩阵乘法的特点,我们可以通过乘法操作,连接所有输入点以及输出点,因此也被称作全连接层。
1.2 Activation层
 激活函数是什么? 激活函数,英文Activation Function,个人理解,激活函数是实现神经元的输入和输出之间非线性化。
激活函数是什么? 激活函数,英文Activation Function,个人理解,激活函数是实现神经元的输入和输出之间非线性化。
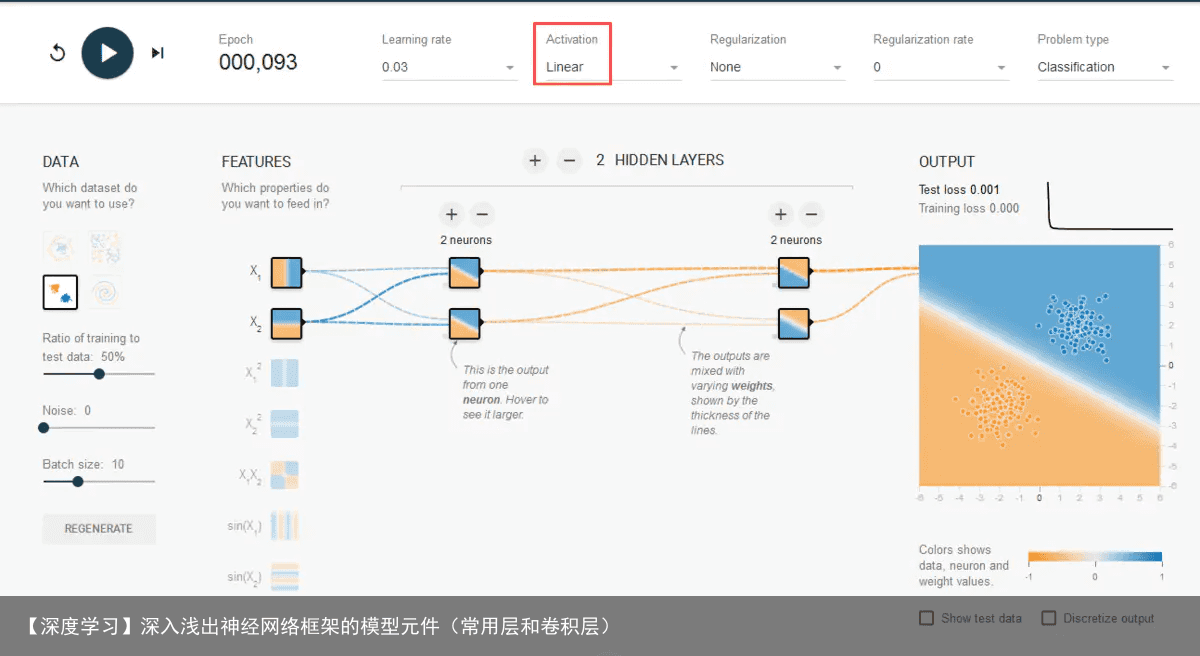
以下通过“游乐场”里的例子看看线性函数的局限性。
对于明显的“一刀切”问题,线性函数还可以解决。
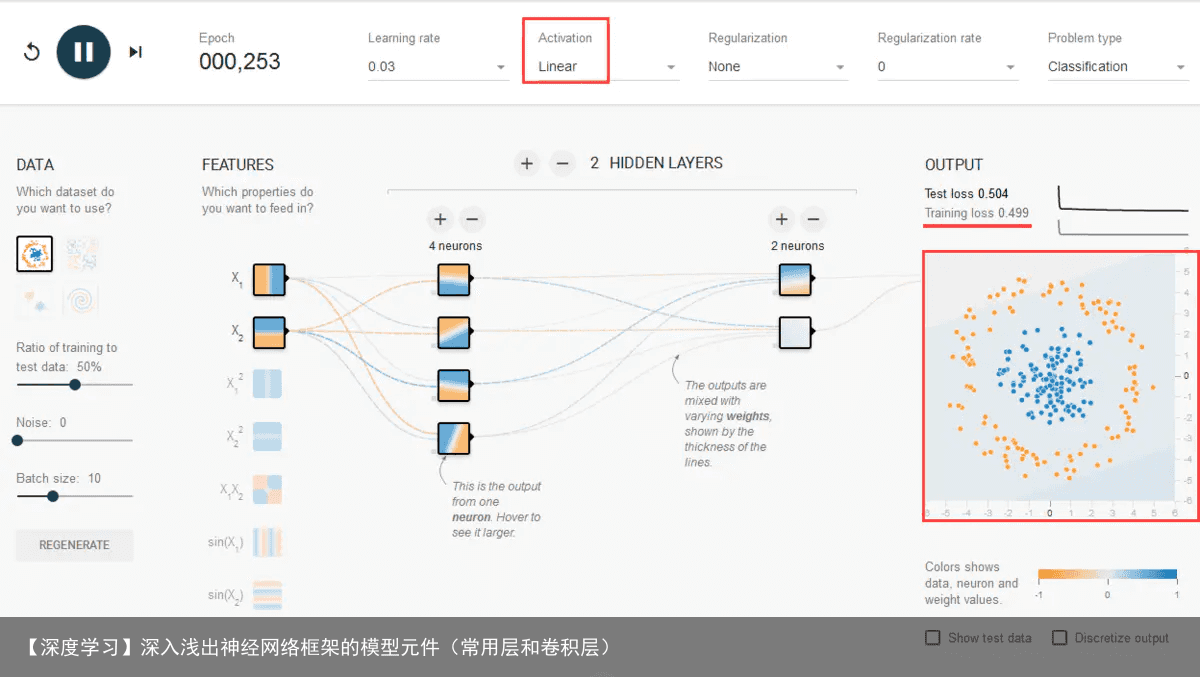
 但是,对于要画曲线的问题就“无能为力”,但是现实世界中能简单“一刀切”的问题毕竟少,更广泛的是下图的非线性问题。
但是,对于要画曲线的问题就“无能为力”,但是现实世界中能简单“一刀切”的问题毕竟少,更广泛的是下图的非线性问题。
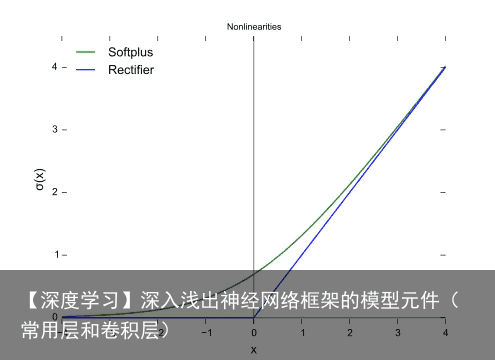
 有哪些激活函数(activation function) 重点参考以下网站:https://blog.csdn.net/u011684265/article/details/78039280
有哪些激活函数(activation function) 重点参考以下网站:https://blog.csdn.net/u011684265/article/details/78039280
ReLU Tanh Sigmoid
ReLU Rectified Linear Unit(ReLU) – 用于隐层神经元输出
公式  sigmoid
sigmoid 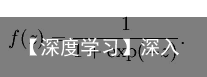
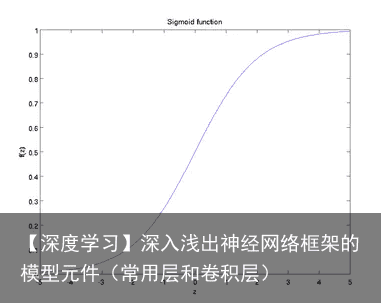 sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。 在特征相差比较复杂或是相差不是特别大时效果比较好。
sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。 在特征相差比较复杂或是相差不是特别大时效果比较好。
sigmoid缺点:
激活函数计算量大,反向传播求误差梯度时,求导涉及除法
反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练
Sigmoids函数饱和且kill掉梯度。
Sigmoids函数收敛缓慢。
Tanh 公式 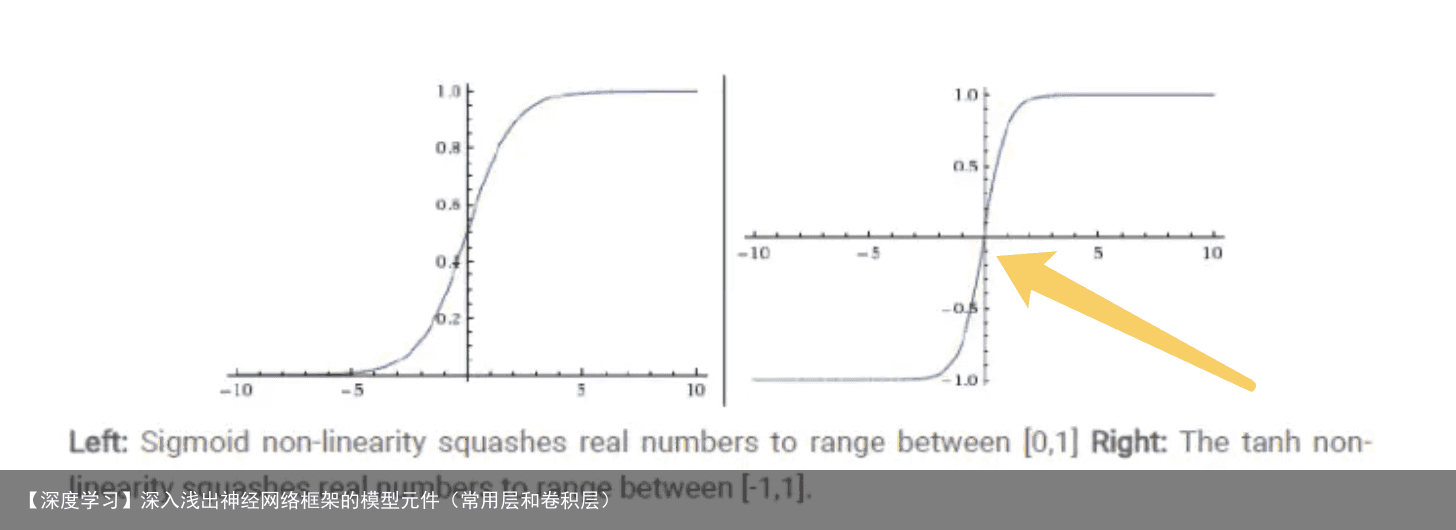
也称为双切正切函数,取值范围为[-1,1]。 tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。 与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好
1.3 Dropout
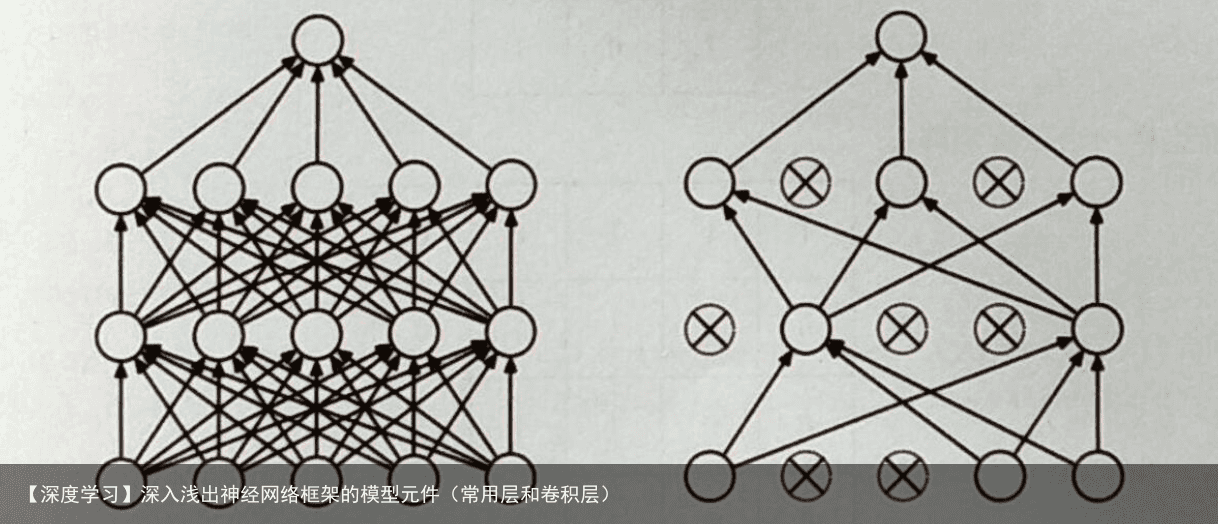
解决过拟合 百分比(rate) 的输入神经元。正则化会给所有参数乘以一个系数,共同计算损失函数,为了避免损失函数过高,模型参数的数量、数值都会缩小。而这里使用Dropout随机断开连接,就等于是削减了参数的数量,这种方式可以用于防止过拟合。
1.4 Flatten
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
从vgg16网络中可以看出,但是在后来的网络中用GlobalAveragePooling2D代替了flatten层,可以从vgg16与inceptionV3网络对比看出。从参数的对比可以看出,显然这种改进大大的减少了参数的使用量,避免了过拟合现象。
model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Dropout(0.5)) model.add(layers.Flatten()) model.add(layers.Dense(512,kernel_regularizer=regularizers.l2(weight_decay))) model.add(layers.Activation(relu)) model.add(layers.BatchNormalization()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(self.num_classes)) # model.add(layers.Activation(softmax)) 2 卷积层
2.1 Cov2D
二维卷积可以处理二维数据
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)) 参数: in_channel: 输入数据的通道数,例RGB图片通道数为3; out_channel: 输出数据的通道数,这个根据模型调整; kennel_size: 卷积核大小,可以是int,或tuple;kennel_size=2,意味着卷积大小(2,2), kennel_size=(2,3),意味着卷积大小(2,3)即非正方形卷积 stride:步长,默认为1,与kennel_size类似,stride=2,意味着步长上下左右扫描皆为2, stride=(2,3),左右扫描步长为2,上下为3; padding: 零填充 例子 输入数据X[10,16,30,32],其分别代表:10组数据,通道数为16,高度为30,宽为32
import torch import torch.nn as nn x = torch.randn(10, 16, 30, 32) # batch, channel , height , width print(x.shape) m = nn.Conv2d(16, 33, (3, 2), (2,1)) # in_channel, out_channel ,kennel_size,stride print(m) y = m(x) print(y.shape)
维度转换很随意的,比如曾经用2dU-net网络训练三维医学图像哦,效果好极了,非常好,目前是我取得做好的结果。
2.2 Cropping2D层
keras.layers.convolutional.Cropping1D(cropping=(1, 1))
对2D输入(图像)进行裁剪,将在空域维度,即宽和高的方向上裁剪。
2.3 Cropping3D层
keras.layers.convolutional.Cropping3D(cropping=((1, 1), (1, 1), (1, 1)), data_format=None)
对2D输入(图像)进行裁剪。
2.4 ZeroPadding2D层
ZeroPadding2D,传入的参数如果是一个二维的tuple,((top_pad, bottom_pad), (left_pad, right_pad)),它表示在上下左右分别补多少层零。
from keras.layers import ZeroPadding2D, Input from keras import Model from numpy import * image = array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) image = image.reshape((1, 3, 3, 1)) inputs = Input(shape=(3, 3, 1)) pad = ZeroPadding2D(((1, 0), (1, 0)))(inputs) model = Model(inputs, pad) out = model.predict(image) print(reshape(out, (4, 4))) >>> [[0. 0. 0. 0.] [0. 1. 2. 3.] [0. 4. 5. 6.] [0. 7. 8. 9.]]
将参数改为((2, 0), (2, 0)),则
pad = ZeroPadding2D(((2, 0), (2, 0)))(inputs) [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 1. 2. 3.] [0. 0. 4. 5. 6.] [0. 0. 7. 8. 9.]]
((1, 1), (1, 1))则在上下左右都补一层零
pad = ZeroPadding2D(((1, 1), (1, 1)))(inputs) [[0. 0. 0. 0. 0.] [0. 1. 2. 3. 0.] [0. 4. 5. 6. 0.] [0. 7. 8. 9. 0.] [0. 0. 0. 0. 0.]]
 下次还会更新一些其他的模型元件~
下次还会更新一些其他的模型元件~
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】深入浅出神经网络框架的模型元件(常用层和卷积层) https://www.yhzz.com.cn/a/12589.html