1.1 MaxPooling2D
同样的我们看看官方的文档,对于最大池化的函数定义:
tf.keras.layers.MaxPool2D( pool_size=(2, 2), strides=None, padding=valid, data_format=None, **kwargs )这个函数给出了4个关键字参数,都是有 默认值的,这意味着你如果一个参数都不给,也是可以的。 pool_size = (2,2),池化核的尺寸,默认是2×2 strides = None,移动步长的意思 ,默认是池化核尺寸,即2, padding = ‘valid’,是否填充,,默认是不填充 data_format = ‘channels_last’,输入数据的格式为(batch_size, pooled_rows, pooled_cols, channels)) 0、当你使用tf.keras.layers.MaxPooling2D(),直接使用,结果如下 : 此时输出的output_shape = (input_shape – pool_size + 1) / strides
1.2 MaxPooling1D:
也是在steps维度(也就是第二维)求最大值。但是限制每一步的池化的大小。 比如,输入数据维度是[10, 4, 10],池化层大小pooling_size=2,步长stride=1,那么经过MaxPooling(pooling_size=2, stride=1)后,输出数据维度是[10, 3, 10]。 实例: 只考虑一条样本,可以认为是SGD(随机梯度下降),假设这条样本三个字,词向量(eg.word2vec)如下所示,数据维度是 [1,4,3]。一般我们不会直接将数据送进池化层,此处假设更方便。
the [[.7, -0.2, .1] |池化大小是2,所以一次选两个字,首先对 boy [.8, -.3, .2] | 前两个向量求最大值,也就是the和boy。 | 步长是1,移动到 will [.2, -.1, .4] | boy和will live [.4 -.4, .8]]1.3 AveragePooling2D
与最大池化不同,采取的是平均池化。
2D输入的平均池层(如图像). 参数: pool_size:2个整数的整数或元组/列表:(pool_height,pool_width),用于指定池窗口的大小;可以是单个整数,以指定所有空间维度的相同值. strides:2个整数的整数或元组/列表,指定池操作的步幅.可以是单个整数,以指定所有空间维度的相同值. padding:一个字符串,填充方法:“valid”或“same”,不区分大小写. data_format:一个字符串,输入中维度的排序,默认为channels_last(默认)并且支持channels_first,channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入. name:一个字符串,图层的名称. 属性 activity_regularizer 可选的调节功能用于该层的输出. dtype graph input 检索图层的输入张量. 只适用于图层只有一个输入,即如果它连接到一个输入层. 返回: 输入张量或输入张量列表. 可能引发的异常: AttributeError:如果图层连接到多个输入图层. RuntimeError:如果在Eager模式下调用. AttributeError:如果找不到入站节点. input_shape 检索图层的输入形状. 只适用于层只有一个输入,即如果它连接到一个输入层,或者如果所有输入具有相同的形状. 返回: 输入形状,作为整数形状元组(或形状元组列表,每个输入张量一个元组). 可能引发的异常: AttributeError:如果图层没有定义input_shape. RuntimeError:如果在Eager模式下调用. losses 与此Layer相关的损失. 请注意,在急切执行时,获取此属性会计算regularizers.当使用图形执行时,变量正则化操作已经创建完成,并简单地在这里返回. 返回: 张量列表. name non_trainable_variables non_trainable_weights output 检索图层的输出张量. 只适用于图层只有一个输出的情况,即,如果它连接到一个输入层. 返回: 输出张量或输出张量列表. 可能引发的异常: AttributeError:如果图层连接到多个输入图层. RuntimeError:如果在Eager模式下调用. output_shape 检索图层的输出形状. 仅适用于图层具有一个输出,或者所有输出具有相同形状的情况. 返回: 输出形状,作为整数形状元组(或形状元组列表,每个输出张量一个元组). 可能引发的异常: AttributeError:如果图层没有定义的输出形状. RuntimeError:如果在Eager模式下调用. scope_name trainable_variables trainable_weights updates variables 返回所有图层变量/权重的列表. 返回: 变量列表. weights 返回所有图层变量/权重的列表. 返回:变量列表.1.4 深度学习的可解释性|Global Average Pooling(GAP)
在常见的卷积神经网络中,全连接层之前的卷积层负责对图像进行特征提取,在获取特征后,传统的方法是接上全连接层之后再进行激活分类,而GAP的思路是使用GAP来替代该全连接层(即使用池化层的方式来降维),更重要的一点是保留了前面各个卷积层和池化层提取到的空间信息\语义信息,所以在实际应用中效果提升也较为明显!,另外,GAP去除了对输入大小的限制!,而且在卷积可视化Grad-CAM中也有重要的应用. 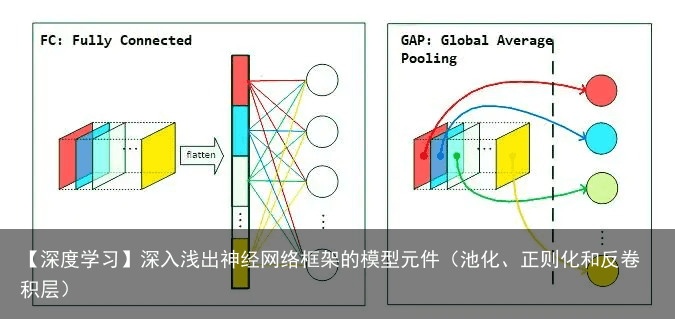 GAP直接从 feature map 的通道信息下手,比如我们现在的分类有N种,那么最后一层的卷积输出的 feature map 就只有N个通道,然后对这个 feature map 进行全局池化操作,获得长度为N的向量,这就相当于直接赋予了每个通道类别的意义。
GAP直接从 feature map 的通道信息下手,比如我们现在的分类有N种,那么最后一层的卷积输出的 feature map 就只有N个通道,然后对这个 feature map 进行全局池化操作,获得长度为N的向量,这就相当于直接赋予了每个通道类别的意义。
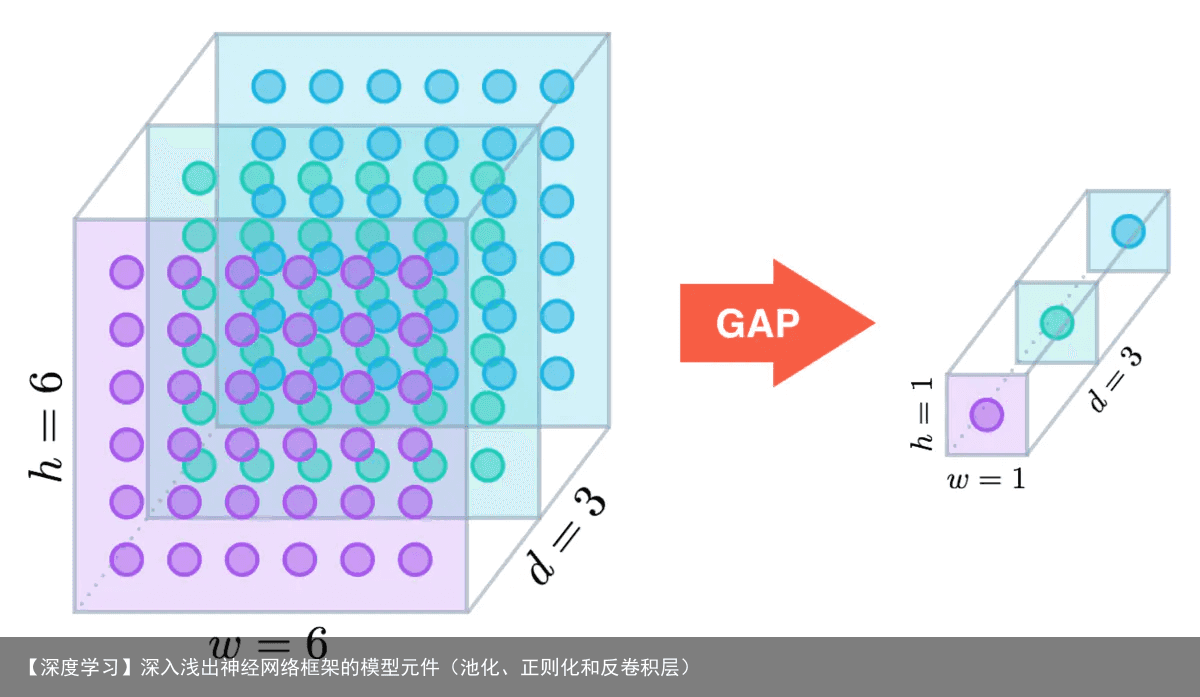
GAP层,通过减少模型中的参数总数来最小化过度拟合。 与最大池层类似,GAP层用于减小三维张量的空间维度。 然而,GAP层执行更极端类型的维数减少,其中尺寸为的张量的尺寸减小为具有的尺寸。 GAP层通过简单地获取所有值的平均值,将每个特征映射层减少为单个数字.
可以这样使用GAP层,即GAP层之后是一个密集连接的层,其中softmax激活函数产生预测的对象类。
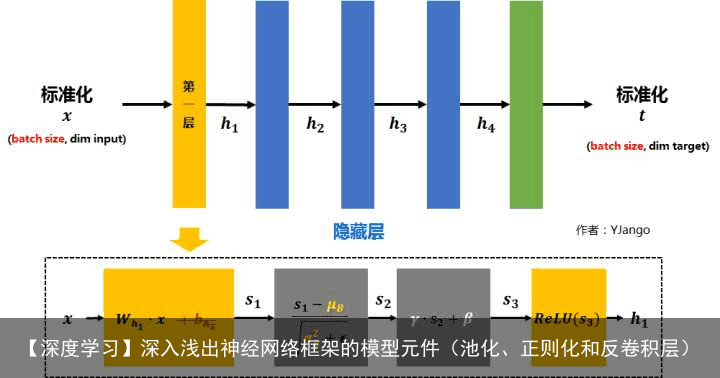
2 正则化2.1 BatchNormalization
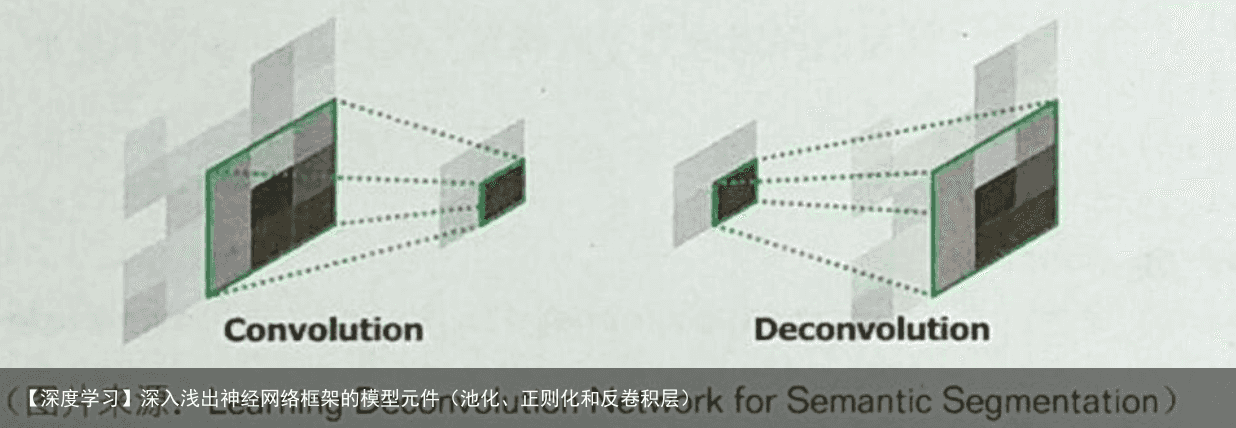
3.1 UpSampling2D
class UpSampling2D(Layer): “”” Nearest neighbor up sampling of the input. Repeats the rows and columns of the data by size[0] and size[1] respectively. Parameters: ———– size: tuple (size_y, size_x) – The number of times each axis will be repeated. “”” def __init__(self, size=(2,2), input_shape=None): self.prev_shape = None self.trainable = True self.size = size self.input_shape = input_shape def forward_pass(self, X, training=True): self.prev_shape = X.shape # Repeat each axis as specified by size X_new = X.repeat(self.size[0], axis=2).repeat(self.size[1], axis=3) return X_new def backward_pass(self, accum_grad): # Down sample input to previous shape accum_grad = accum_grad[:, :, ::self.size[0], ::self.size[1]] return accum_grad def output_shape(self): channels, height, width = self.input_shape return channels, self.size[0] * height, self.size[1] * width缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
3.2 循环层(RNN)
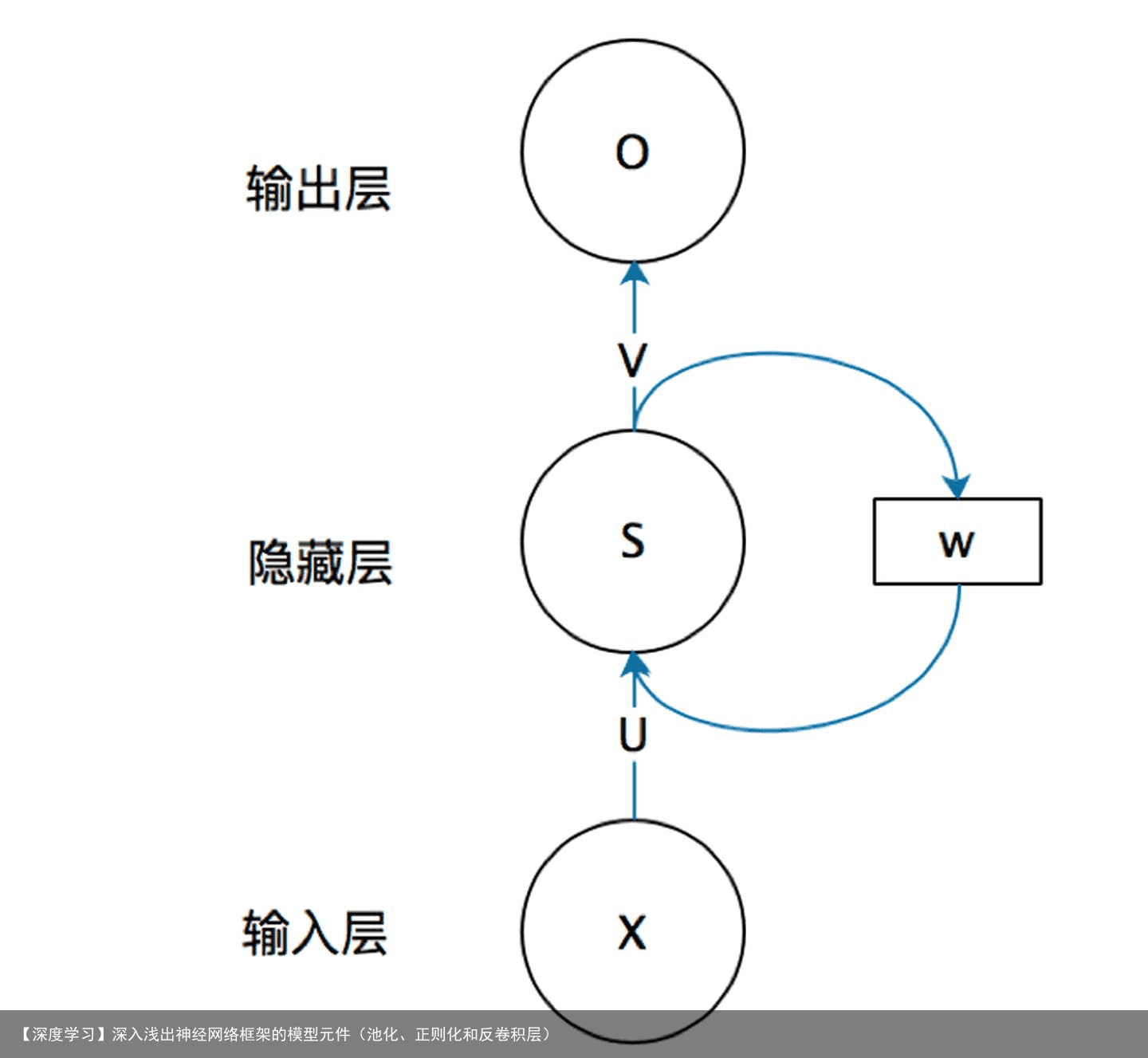 除此之外还有为了解决梯度爆炸或者弥撒问题而发明的LSTM网络,我使用它很好的应用在疫情的时间序列预测上,这里不在多少。
除此之外还有为了解决梯度爆炸或者弥撒问题而发明的LSTM网络,我使用它很好的应用在疫情的时间序列预测上,这里不在多少。
3.3 GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
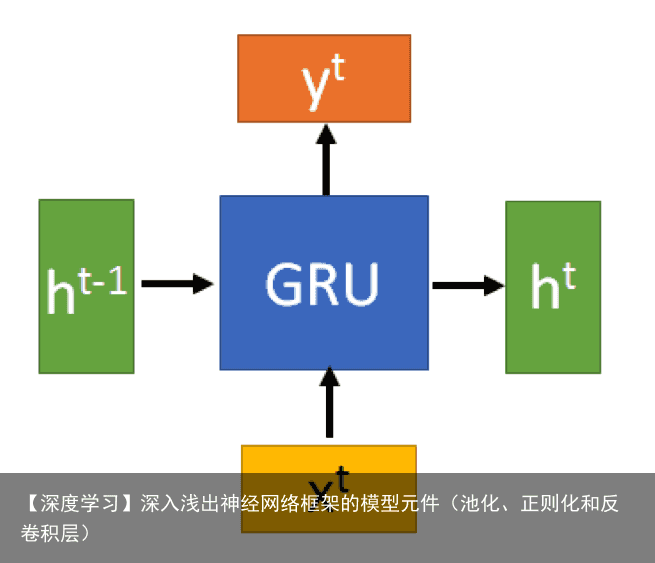
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。 就到这啦!!
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】深入浅出神经网络框架的模型元件(池化、正则化和反卷积层) https://www.yhzz.com.cn/a/12587.html