前言
广义的音频重采样包括: 1、采样格式转化:比如采样格式从16位整形变为浮点型 2、采样率的转换:降采样和升采样,比如44100采样率降为2000采样率 3、存放方式转化:音频数据从packet方式变为planner方式。有的硬件平台在播放声音时需要的音频数据是planner格式的,而有的可能又是packet格式的,或者其它需求原因经常需要进行这种存放方式的转化
通常意义上的音频重采样是指上述的第2点,即升采样和降采样,这个对音质有一定影响
重采样相关函数流程图
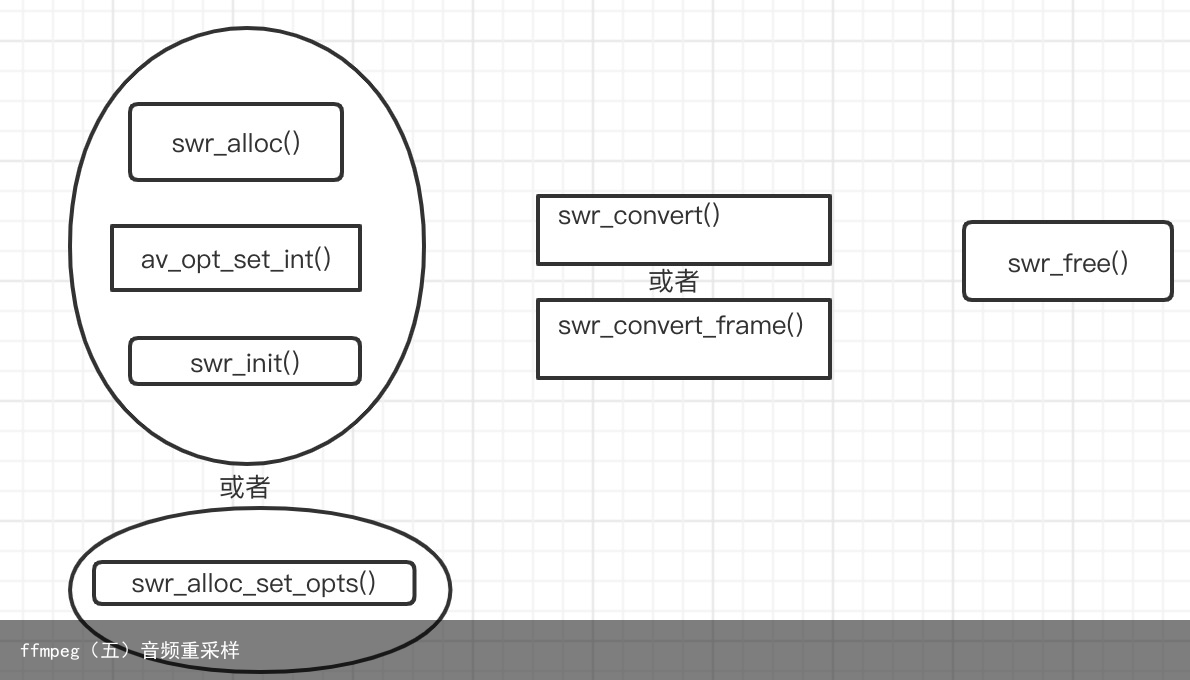
重采样ffmpeg相关函数介绍
这些重采样函数都位于头文件<libswresampe/swresample.h>
1、SwrContext 实现重采样的上下文,它是一个结构体,具体定义未知 2、SwrContext *swr_alloc(); 分配上下对象 3、 int av_opt_set_int(void obj,char name,int64_t val,int search_flags); int av_opt_set_sample_fmt(void obj,char name,enum AVSampleFormat fmt,int search_flags); 给上下文对象设置重采样的转换参数 4、int swr_init(struct SwrContext * swrCtx); 设置参数之后初始化重采样上下文 5、struct SwrContext swr_alloc_set_opts(struct SwrContext swr_ctx, int64_t out_ch_layout,enum AVSampleFormat out_sample_fmt,int out_sample_rate, int64_t in_ch_layout,enum AVSampleFormat in_ch_layout,int in_sample_rate ); 此函数功能相当于上面1、2、3、4所有函数的功能 6、int swr_convert(struct SwrContext *swrCtx,uint8_t out,int out_count, const uint8_t int,int in_count) 进行格式转换,返回值为实际转换的采样数,该值小于等于out_count 7、int swr_convert_frame(struct SwrContext *swrCtx,AVFrame **outframe,AVFrame inframe); 返回值为0代表转换成功。当进行升采/降样的时候,内部缓冲中会包含部分数据,要想全部获取这些数据,inframe要传递NULL 8、void swr_free(struct SwrContext **s); 释放上下文ffmpeg实现音频重采样
ffmpeg提供了实现广义重采样的方式,通过libswresample库实现,可以通过具体实现代码如下: 头文件
#ifndef audio_resample_hpp #define audio_resample_hpp #include <stdio.h> #include <string> #include “cppcommon/CLog.h” using namespace std; extern “C” { #include <libswresample/swresample.h> #include <libavutil/opt.h> #include <libavutil/channel_layout.h> #include <libavcodec/avcodec.h> #include <libavutil/avutil.h> } /** 广义的音频的重采样包括: * 1、采样格式转化:比如采样格式从16位整形变为浮点型 * 2、采样率的转换:降采样和升采样,比如44100采样率降为2000采样率 * 3、存放方式转化:音频数据从packet方式变为planner方式。有的硬件平台在播放声音时需要的音频数据是 * planner格式的,而有的可能又是packet格式的,或者其它需求原因经常需要进行这种存放方式的转化 */ class AudioResample { public: AudioResample(); ~AudioResample(); void doResample(); void doResampleAVFrame(); private: }; #endif /* audio_resample_hpp */<
上面doResample()对应swr_convert()函数,doResampleAVFrame()函数对应 swr_convert_frame()函数
具体实现: /** av_frame_get_buffer()给AVFrame分配的音频内存和av_samples_alloc_array_and_samples()分配的音频内存块的区别 * 1、前者内存由引用计数管理,而且对于planner方式音频,是两个独立的内存块,内存块首地址不一样; * 2、后者内存和普通的内存管理方式一样,需要自己手动释放,对于planner方式音频,它也是一个连续的内存块,只不过每个planner对应的首地址分别存储于 * 指向的数组指针中;释放由函数av_freep(dataAddr),dataAddr指的连续内存块的首地址 */ /** 重采样实验: * 1、44100的采样率,升采样48000或者降采样24000 后对音质影响不大,存储到文件中的数值会变化 * 2、float类型的采样数据,转换成32位整数型采样数据 对音质影响也不大,存储到文件中的数值会变化 */ void AudioResample::doResample() { string curFile(__FILE__); unsigned long pos = curFile.find(“ffmpeg-demo”); if (pos == string::npos) { // 未找到 return; } string resouceDic = curFile.substr(0,pos)+”ffmpeg-demo/filesources/”; // 原pcm文件中存储的是float类型音频数据,小端序;packet方式 string pcmpath = resouceDic+”test_441_f32le_2.pcm”; string dstpath1 = “test_240_s32le_2.pcm”; FILE *srcFile = fopen(pcmpath.c_str(), “rb+”); if (srcFile == NULL) { LOGD(“fopen srcFile fail”); return; } FILE *dstFile = fopen(dstpath1.c_str(), “wb+”); if (dstFile == NULL) { LOGD(“fopen dstFile fail”); return; } // 音频数据 uint8_t **src_data,**dst_data; // 声道数 int src_nb_channels=0,dst_nb_channels=0; int64_t src_ch_layout = AV_CH_LAYOUT_STEREO,dst_ch_layout = AV_CH_LAYOUT_STEREO; // 采样率 int64_t src_rate = 44100,dst_rate = 48000; // 采样格式和音频数据存储方式 const enum AVSampleFormat src_sample_fmt = AV_SAMPLE_FMT_FLT,dst_sample_fmt = AV_SAMPLE_FMT_S32P; int src_nb_samples=1024,dst_nb_samples,max_dst_nb_samples; int src_linesize,dst_linesize; // 1、创建上下文SwrContext SwrContext *swrCtx; swrCtx = swr_alloc(); if (swrCtx == NULL) { LOGD(“swr_allock fail”); return; } // 2、设置重采样的相关参数 这些函数位于头文件 <libavutil/opt.h> av_opt_set_int(swrCtx, “in_channel_layout”, src_ch_layout, 0); av_opt_set_int(swrCtx, “in_sample_rate”, src_rate, 0); av_opt_set_sample_fmt(swrCtx, “in_sample_fmt”, src_sample_fmt, 0); av_opt_set_int(swrCtx, “out_channel_layout”, dst_ch_layout, 0); av_opt_set_int(swrCtx, “out_sample_rate”, dst_rate, 0); av_opt_set_sample_fmt(swrCtx, “out_sample_fmt”, dst_sample_fmt, 0); // 3、初始化上下文 int ret = 0; ret = swr_init(swrCtx); if (ret < 0) { LOGD(“swr_init fail”); return; } src_nb_channels = av_get_channel_layout_nb_channels(src_ch_layout); dst_nb_channels = av_get_channel_layout_nb_channels(dst_ch_layout); // 根据src_sample_fmt、src_nb_samples、src_nb_channels为src_data分配内存空间,和设置对应的的linesize的值;返回分配的总内存的大小 int src_buf_size = av_samples_alloc_array_and_samples(&src_data, &src_linesize, src_nb_channels, src_nb_samples, src_sample_fmt, 0); // 根据src_nb_samples*dst_rate/src_rate公式初步估算重采样后音频的nb_samples大小 max_dst_nb_samples = dst_nb_samples = (int)av_rescale_rnd(src_nb_samples, dst_rate, src_rate, AV_ROUND_UP); int dst_buf_size = av_samples_alloc_array_and_samples(&dst_data, &dst_linesize, dst_nb_channels, dst_nb_samples, dst_sample_fmt, 0); size_t read_size = 0; while ((read_size = fread(src_data[0], 1, src_buf_size, srcFile)) > 0) { /** 因为有转换时有缓存,所以要不停的调整转换后的内存的大小。估算重采样后的的nb_samples的大小,这里swr_get_delay()用于获取重采样的缓冲延迟 * dst_nb_samples的值会经过多次调整后区域稳定 */ dst_nb_samples = (int)av_rescale_rnd(swr_get_delay(swrCtx, src_rate)+src_nb_samples, dst_rate, src_rate, AV_ROUND_UP); if (dst_nb_samples > max_dst_nb_samples) { LOGD(“要重新分配内存了”); // 先释放以前的内存,不管sample_fmt是planner还是packet方式,av_samples_alloc_array_and_samples()函数都是分配的一整块连续的内存 av_freep(&dst_data[0]); // 再重新分配内存 dst_buf_size = av_samples_alloc_array_and_samples(&dst_data, &dst_linesize, dst_nb_channels, dst_nb_samples, dst_sample_fmt, 0); max_dst_nb_samples = dst_nb_samples; } // 开始重采样,重采样后的数据将根据前面指定的存储方式写入ds_data内存块中,返回每个声道实际的采样数 /** * 遇到问题:转换后声音不对 * 原因分析:swr_convert()函数返回的result是实际转换的采样个数,该值肯定小于等于预计采样数dst_nb_samples,所以写入文件的时候不能用dst_nb_samples的 * 值,而应该用result值 **/ int result = swr_convert(swrCtx, dst_data, dst_nb_samples, (const uint8_t **)src_data, src_nb_samples); if (result < 0) { LOGD(“swr_convert fail %d”,result); break; } LOGD(“read_size %d dst_nb_samples %d src_nb_samples %d result %d”,read_size,dst_nb_samples,src_nb_samples,result); // 将音频数据写入pcm文件 if (av_sample_fmt_is_planar(dst_sample_fmt)) { // planner方式,而pcm文件写入时一般都是packet方式,所以这里要注意转换一下 int size = av_get_bytes_per_sample(dst_sample_fmt); // 这里必须是result,而不能用dst_nb_samples,因为result才代表此次实际转换的采样数 它肯定小于等于dst_nb_samples for (int i=0; i<result;i++) { for (int j=0; j<dst_nb_channels; j++) { fwrite(dst_data[j]+i*size, 1, size, dstFile); } } } else { // 最后一个参数必须为1 否则会因为cpu对齐算出来的大小大于实际的数据大小 导致多写入数据 从而造成错误 dst_buf_size = av_samples_get_buffer_size(&dst_linesize,dst_nb_channels, result,dst_sample_fmt,1); fwrite(dst_data[0], 1, dst_buf_size, dstFile); } } // 还有剩余的缓存数据没有转换,第三个传递NULL,第四个传递0即可将缓存中的全部取出 do { int real_nb_samples = swr_convert(swrCtx,dst_data,dst_nb_samples,NULL,0); if (real_nb_samples <=0) { break; } LOGD(“余量 %d”,real_nb_samples); if (av_sample_fmt_is_planar(dst_sample_fmt)) { int size = av_get_bytes_per_sample(dst_sample_fmt); for (int i=0; i<real_nb_samples; i++) { for (int j=0; j<dst_nb_channels; j++) { fwrite(dst_data[j]+i*size,1,size,dstFile); } } } else { int size = av_samples_get_buffer_size(NULL,dst_nb_channels,real_nb_samples,dst_sample_fmt,1); fwrite(dst_data[0], 1, size, dstFile); } } while (true); // 释放资源 av_freep(&src_data[0]); av_freep(&dst_data[0]); swr_free(&swrCtx); fclose(srcFile); fclose(dstFile); }<
代码解读
1、要进行转换的PCM数据位于项目同级目录下的filesources文件夹中,这里采用的是test_441_f32le_2.pcm,代表采样格式float类型小端序,采样率44100 声道数2的数据
2、src_channel_layout,src_sample_rate,src_sample_fmt三个变量要与步骤1中的对应起来。dst_channel_layout,dst_sample_rate,dst_sample_fmt则可以按照自己的需求进行转换
3、代码 dst_nb_samples = (int)av_rescale_rnd(swr_get_delay(swrCtx, src_rate)+src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
为不停调整转后后的预计目标采样数大小,此代码可有可无,不是必须的
4、swr_convert()函数返回的是实际转换的目标采样数大小,所以dst_data中数据的大小应该是该函数返回的值,而非前面通过dst_nb_samples计算出来的值
5、转换过程中可能会有部分为转换的数据存在于内部缓冲中,通过int real_nb_samples = swr_convert(swrCtx,dst_data,dst_nb_samples,NULL,0);
代码将这些剩余的数据转换完毕
void AudioResample::doResampleAVFrame()
{
string curFile(__FILE__);
unsigned long pos = curFile.find(“ffmpeg-demo”);
if (pos == string::npos){
LOGD(“cannot find file”);
return;
}
string srcpcm = curFile.substr(0,pos)+”ffmpeg-demo/filesources/test_441_f32le_2.pcm”;
string dstpcm = “test_441_s32le_2.pcm”;
uint64_t src_channel_layout = AV_CH_LAYOUT_STEREO,dst_channel_layout = AV_CH_LAYOUT_STEREO;
int src_nb_channels = av_get_channel_layout_nb_channels(src_channel_layout);
int dst_nb_channels = av_get_channel_layout_nb_channels(dst_channel_layout);
int64_t src_nb_samples = 1024,dst_nb_samples,max_dst_nb_samples;
int64_t src_sample_rate = 44100,dst_sample_rate=44100;
const enum AVSampleFormat src_sample_fmt = AV_SAMPLE_FMT_FLT,dst_sample_fmt = AV_SAMPLE_FMT_S32P;
FILE *srcFile,*dstFile;
if ((srcFile = fopen(srcpcm.c_str(), “rb”)) == NULL) {
LOGD(“open srcpcm fail”);
return;
}
if ((dstFile = fopen(dstpcm.c_str(),”wb+”)) == NULL) {
LOGD(“open dstpcm fail”);
return;
}
AVFrame *srcFrame,*dstFrame;
srcFrame = av_frame_alloc();
srcFrame->nb_samples = (int)src_nb_samples;
srcFrame->format = src_sample_fmt;
srcFrame->sample_rate = (int)src_sample_rate;
srcFrame->channel_layout = src_channel_layout;
srcFrame->channels = src_nb_channels;
int ret = av_frame_get_buffer(srcFrame,0);
if (ret < 0) {
LOGD(“av_frame_get_buffer() return faile %d”,ret);
return;
}
ret = av_frame_make_writable(srcFrame);
if (ret < 0) {
LOGD(“av_frame_make_writable() fail %d”,ret);
return;
}
// 采样数跟采样率有关 目标采样数根据由采样率根据比例公式计算出
// R2 = R1*(β2/β1) R1 称作参考源 与R2是同一类型数据,β1、β2称作比例因子,影响系数。R1,β2,β1一次对应这个公式的第一二三个系数
max_dst_nb_samples = dst_nb_samples = (int)av_rescale_rnd(src_nb_samples,dst_sample_rate,src_sample_rate,AV_ROUND_UP);
dstFrame = av_frame_alloc();
dstFrame->sample_rate = (int)dst_sample_rate;
dstFrame->format = dst_sample_fmt;
dstFrame->nb_samples = (int)dst_nb_samples;
dstFrame->channel_layout = dst_channel_layout;
dstFrame->channels = dst_nb_channels;
ret = av_frame_get_buffer(dstFrame,0);
if(ret < 0) {
LOGD(“av_frame_get_buffer2 failt %d”,ret);
return;
}
ret = av_frame_make_writable(dstFrame);
if (ret < 0){
LOGD(“av_frame_make_writable() 2 failt %d”,ret);
return;
}
// 1、创建上下文
SwrContext *swr_ctx = swr_alloc();
if (swr_ctx == NULL) {
LOGD(“swr_alloc fail”);
return;
}
// 2、设置转换参数 在<libswresample/options.c>文件中可以找到定义
av_opt_set_int(swr_ctx,”in_channel_layout”,src_channel_layout,AV_OPT_SEARCH_CHILDREN);
av_opt_set_int(swr_ctx,”in_sample_rate”,src_sample_rate,AV_OPT_SEARCH_CHILDREN);
av_opt_set_sample_fmt(swr_ctx,”in_sample_fmt”,src_sample_fmt,AV_OPT_SEARCH_CHILDREN);
av_opt_set_int(swr_ctx,”out_channel_layout”,dst_channel_layout,AV_OPT_SEARCH_CHILDREN);
av_opt_set_int(swr_ctx,”out_sample_rate”,dst_sample_rate,AV_OPT_SEARCH_CHILDREN);
av_opt_set_sample_fmt(swr_ctx,”out_sample_fmt”,dst_sample_fmt,AV_OPT_SEARCH_CHILDREN);
// 3、执行初始化
ret = swr_init(swr_ctx);
if (ret < 0) {
LOGD(“swr_init fail”);
return;
}
int require_size = av_samples_get_buffer_size(NULL,src_nb_channels,(int)src_nb_samples,src_sample_fmt,0);
size_t read_size = 0;
// 这里必须传递srcFrame->data[0]这个地址,而不能传递srcFrame->data
while ((read_size = fread(srcFrame->data[0],1,require_size,srcFile)) > 0) {
/** 当转换后的采样率大于转换前的转换率时,内部会有缓冲,所以预计转换后的目标采样数会一直变化 所以这里目标音频内存大小也要跟着动态调整;当然也可以不做调整
*/
dst_nb_samples = av_rescale_rnd(swr_get_delay(swr_ctx,src_sample_rate)+src_nb_samples,dst_sample_rate,src_sample_rate,AV_ROUND_UP);
if (dst_nb_samples > max_dst_nb_samples) {
max_dst_nb_samples = dst_nb_samples;
av_frame_unref(dstFrame);
LOGD(“重新调整转换后存储音频数据内存大小 %d”,max_dst_nb_samples);
AVFrame *tmp = av_frame_alloc();
tmp->format = dst_sample_fmt;
tmp->nb_samples = (int)dst_nb_samples;
tmp->channel_layout = dst_channel_layout;
tmp->channels = dst_nb_channels;
tmp->sample_rate = (int)dst_sample_rate;
ret = av_frame_get_buffer(tmp,0);
if (ret < 0) {
LOGD(“av_frame_get_buffer fail %d”,ret);
break;
}
ret = av_frame_make_writable(tmp);
if (ret < 0) {
LOGD(“av_frame_make_writable()11 fail %d”,ret);
break;
}
av_frame_move_ref(dstFrame, tmp);
}
// 4、音频格式转换 返回实际转换的采样数 <= dst_nb_samples
// 对于音频 AVFrame中extended_data和data属性指向同一块内存
int real_convert_nb_samples;
#define UseAVFrame
#ifndef UseAVFrame
const uint8_t **srcdata = (const uint8_t **)srcFrame->extended_data;
uint8_t **outdata = dstFrame->extended_data;
real_convert_nb_samples = swr_convert(swr_ctx,outdata,(int)dst_nb_samples,srcdata,(int)src_nb_samples);
LOGD(“swr_convert nb_samples %d”,real_convert_nb_samples);
#else
ret = swr_convert_frame(swr_ctx,dstFrame,srcFrame);
if (ret < 0) {
LOGD(“swr_convert_frame fail %d”,ret);
continue;
}
real_convert_nb_samples = dstFrame->nb_samples;
LOGD(“swr_convert_frame nb_samples %d”,real_convert_nb_samples);
#endif
// 5、存储;由于文件是planner格式,所以对于planner格式的存储要注意下
if (av_sample_fmt_is_planar(dst_sample_fmt)) {
int size = av_get_bytes_per_sample(dst_sample_fmt);
for (int i =0; i< real_convert_nb_samples;i++) {
for (int j=0;j<dst_nb_channels;j++) {
fwrite(dstFrame->data[j]+i*size,1,size,dstFile);
}
}
} else {
int size = av_samples_get_buffer_size(NULL,dst_nb_channels,real_convert_nb_samples,dst_sample_fmt,1);
fwrite(dstFrame->data[0],1,size,dstFile);
}
}
/** 当转换后的采样率大于转换前的转换率时,内部会有缓冲
*/
#ifdef UseAVFrame
// 会有内部缓冲,这里传递NULL,将剩余的数据全部读取出来
while (swr_convert_frame(swr_ctx,dstFrame,NULL) >= 0) {
if (dstFrame->nb_samples <= 0) {
break;
}
LOGD(“还有余量 %d”,dstFrame->nb_samples);
#else
uint8_t **outdata = dstFrame->extended_data;
int real_convert_nb_samples = 1;
while (real_convert_nb_samples > 0) {
// 会有内部缓冲,这里第三个传递NULL,第四个传递0即可。将剩余的数据全部读取出来
real_convert_nb_samples = swr_convert(swr_ctx,outdata,(int)dst_nb_samples,NULL,0);
LOGD(“还有余量 %d”,real_convert_nb_samples);
#endif
if (av_sample_fmt_is_planar(dst_sample_fmt)) {
int size = av_get_bytes_per_sample((dst_sample_fmt));
for (int i=0; i<dstFrame->nb_samples; i++) {
for (int j=0; j<dstFrame->channels; j++) {
fwrite(dstFrame->data[j]+i*size,1,size,dstFile);
}
}
} else {
int size = av_samples_get_buffer_size(NULL,dstFrame->channels,dstFrame->nb_samples,(enum AVSampleFormat)dstFrame->format,1);
fwrite(dstFrame->data[0],1,size,dstFile);
}
}
swr_free(&swr_ctx);
av_frame_unref(srcFrame);
av_frame_unref(dstFrame);
fclose(srcFile);
fclose(dstFile);
}<
遇到问题
1、转换后声音不对 原因分析: swr_convert()函数返回的result是实际转换的采样个数,该值肯定小于等于预计采样数dst_nb_samples,所以写入文件的时候不能用dst_nb_samples的值,而应该用result值
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:ffmpeg(五)音频重采样 https://www.yhzz.com.cn/a/12543.html