目标检测算法已经渗透进我们生活的方方面面,人脸识别就是一个非常典型的目标检测算法的应用。现在很多地方都已经设置了人脸识别的门禁系统,大家在出入时只需将自己的脸放入门禁的检测框内,门禁系统就能快速得识别出人脸的位置以及它的主人,从而判断是否开门放行。yolo算法是目前比较成熟的目标检测算法之一,我们从本篇文章开始,将一起探索它的魅力,并使用yolo v3实现画面中数字的检测与识别。 在此之前,我们不妨分析一下数字检测与识别的实现过程。首先,我们直接想到的实现方法就是将该过程划分为两个步骤:数字的检测与数字的识别。第一步,我们可以使用穷举法检测图像中的每一个位置,判断图像中是否存在数字,从而检测到数字的位置。第二步,我们使用卷积神经网络等图像分类算法识别检测到的数字。最终实现画面中数字的检测与识别。著名的R-CNN算法的思路就和上述过程类似,所以这类算法又称为两阶段检测算法。而我们本篇文章的重头戏——yolo算法则将检测和识别两个步骤合成了一步,使用一个网络同时预测目标的位置与类别,所以又称为单阶段检测算法。 关于yolo算法的原理,我会在之后的文章中详细介绍。需要提前说明的是,本篇文章使用的深度学习框架为百度的PaddlePaddle,训练平台使用的是百度的线上深度学习平台AiStudio而不是本地机器。这样选择的好处一个是不用自己配置深度学习环境,大大提升学习开发效率,另一个就是这样可以完全免费地使用百度的GPU算力,对本机性能没有任何需求,大大降低学习成本。缺点就是我们只能用百度的深度学习框架,而不是大家熟悉的tensorflow或者pytorch。因此建议大家可以提前浏览关于PaddlePaddle和Aistudio的相关内容。在使用任何一个目标检测算法之前,我们都需要准备数据集。而很多情况下,都需要我们创建自己的数据集以供模型训练。所以,本篇文章将为大家介绍目标检测数据集的制作过程。 首先,我们需要收集大量包含手写数字的图像,例如:  接着,我们需要使用标注工具对我们的目标进行标注。我使用的是百度的在线标注平台——EasyData。这是因为该平台是线上工具,我们不用下载任何软件或者配置任何工具,直接将我们收集到的图片上传到该平台进行标注即可,下图是该平台的主页:
接着,我们需要使用标注工具对我们的目标进行标注。我使用的是百度的在线标注平台——EasyData。这是因为该平台是线上工具,我们不用下载任何软件或者配置任何工具,直接将我们收集到的图片上传到该平台进行标注即可,下图是该平台的主页: 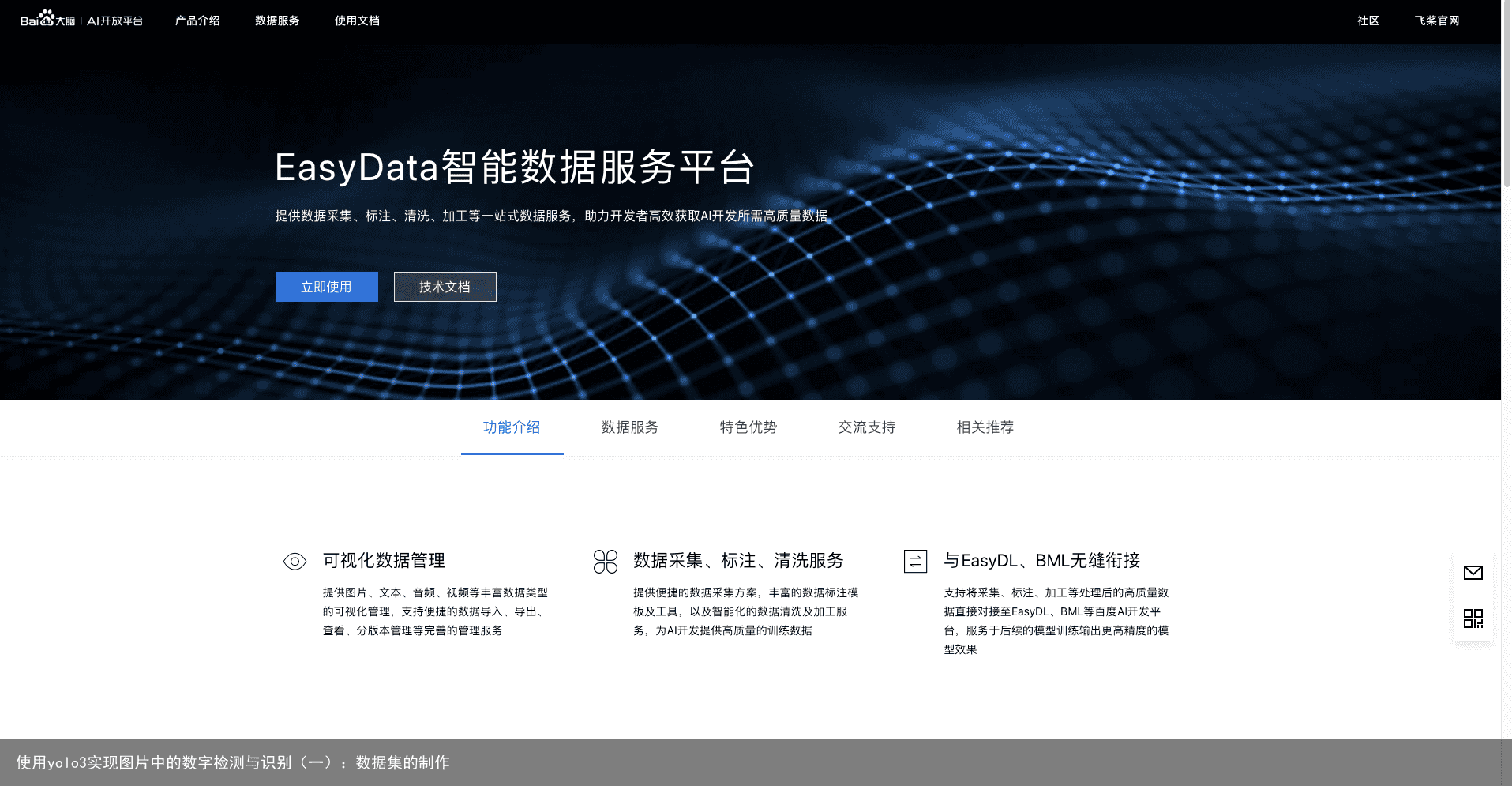 在登陆或者注册自己的百度账号之后,点击“立即使用”进入数据标注的管理界面:
在登陆或者注册自己的百度账号之后,点击“立即使用”进入数据标注的管理界面: 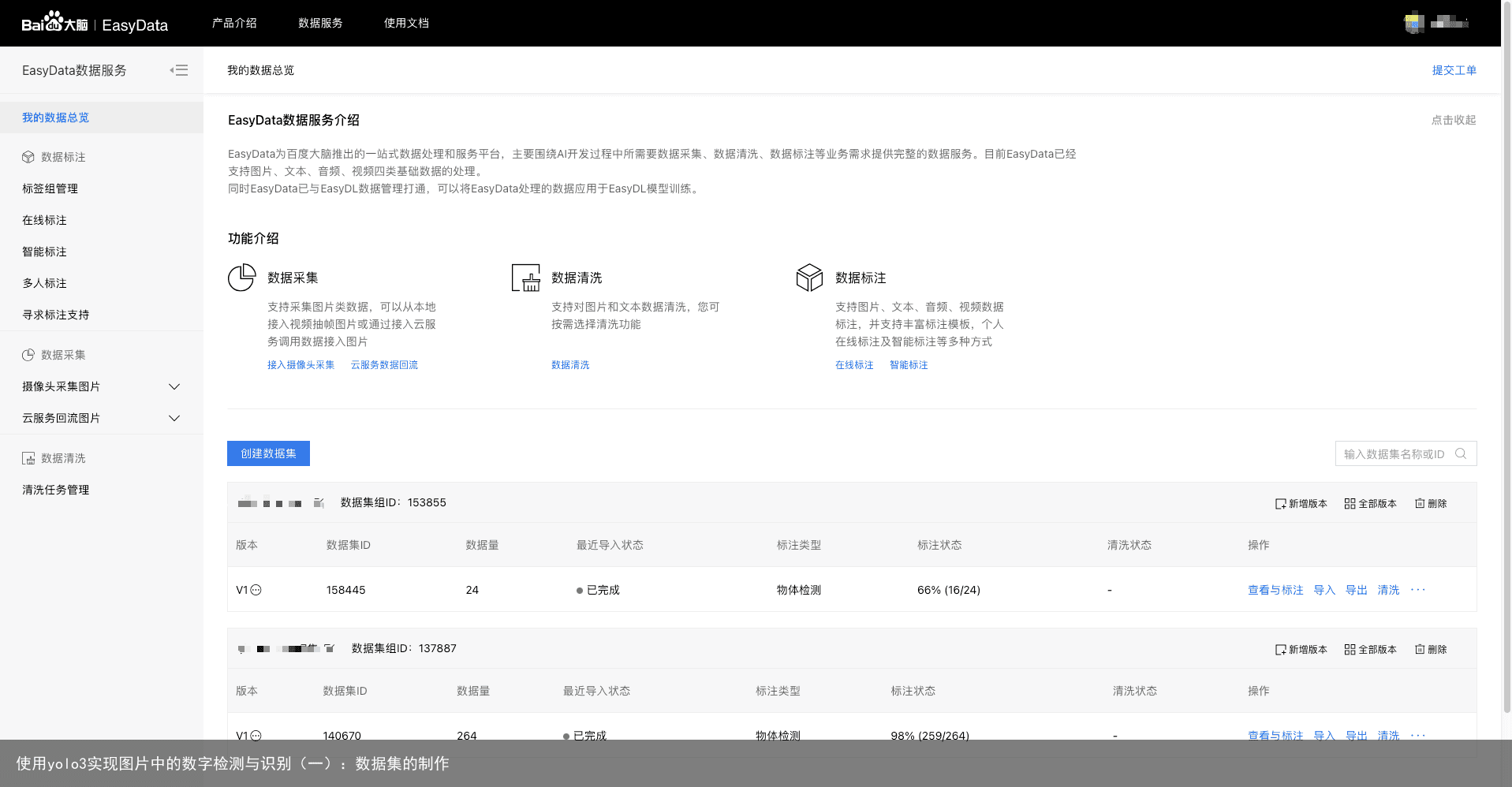 点击创建数据集,在弹出的对话框中选择物体检测,标注模版矩形框,然后输入数据集名称,点击完成即可:
点击创建数据集,在弹出的对话框中选择物体检测,标注模版矩形框,然后输入数据集名称,点击完成即可: 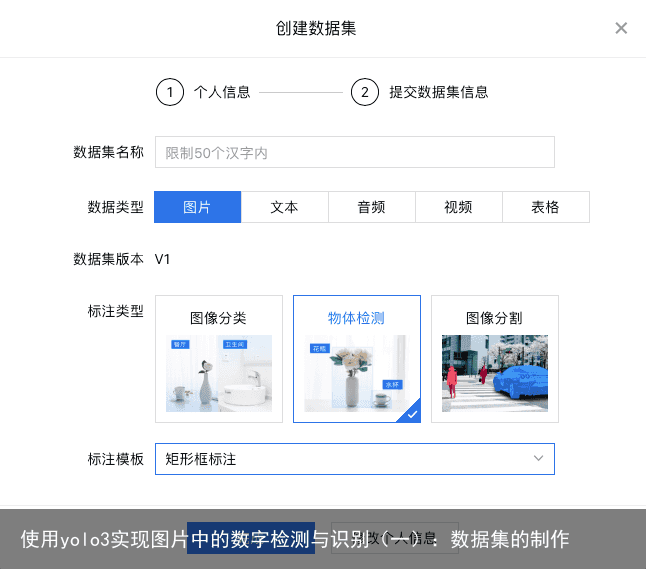 创建好数据集后,我们点击导入,这里平台给了很多种导入方式,我们可以选择摄像头采集数据来调用自己电脑的摄像头来进行数据的采集,也可以选择导入本地数据,将我们事先采集好的数据导入。我这里以导入本地数据为例。
创建好数据集后,我们点击导入,这里平台给了很多种导入方式,我们可以选择摄像头采集数据来调用自己电脑的摄像头来进行数据的采集,也可以选择导入本地数据,将我们事先采集好的数据导入。我这里以导入本地数据为例。 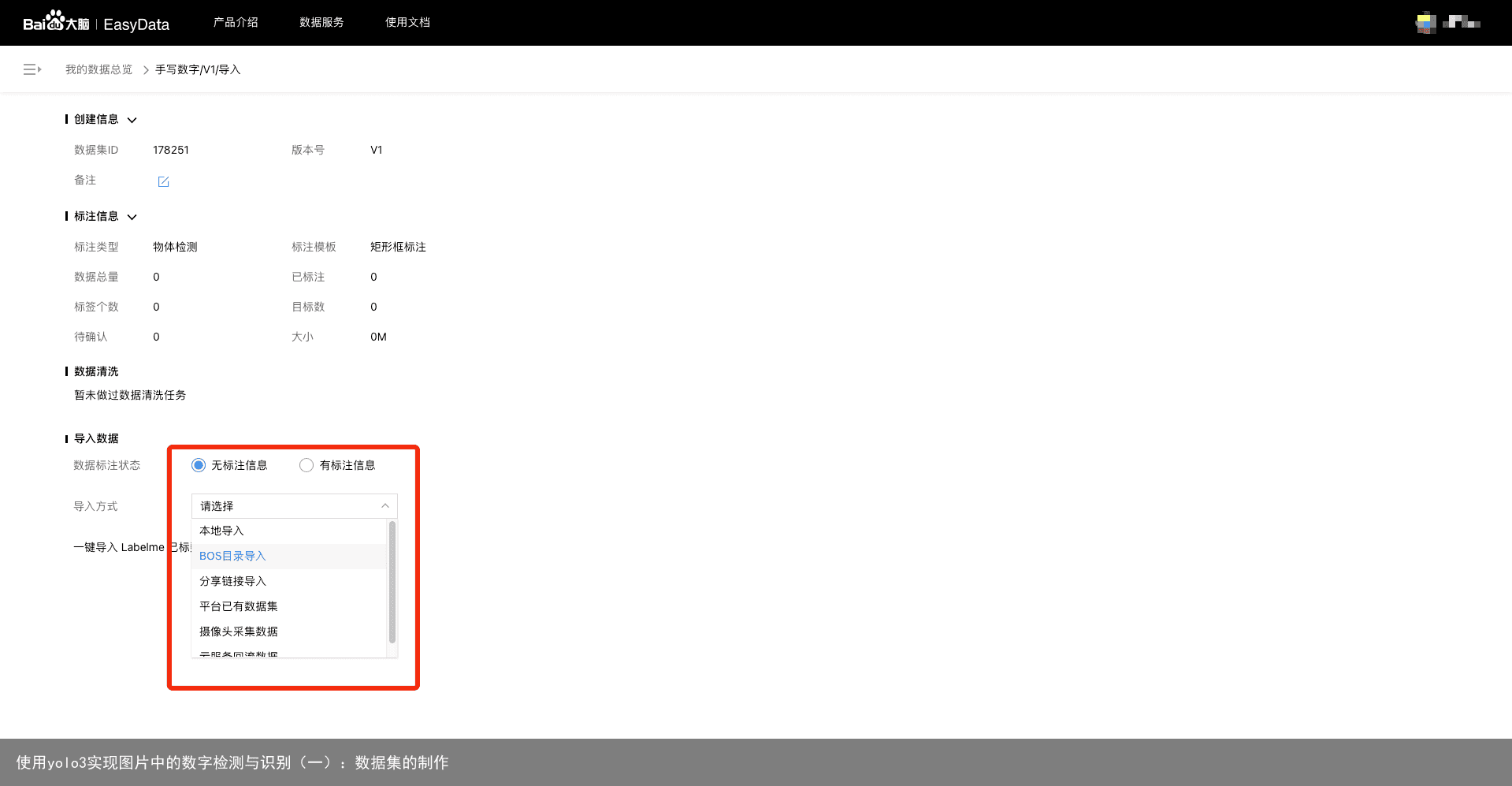 导入完数据之后,我们点击确认并返回到上一个页面。等图片上传完成以后点击查看与标注,进入标注页面:
导入完数据之后,我们点击确认并返回到上一个页面。等图片上传完成以后点击查看与标注,进入标注页面: 
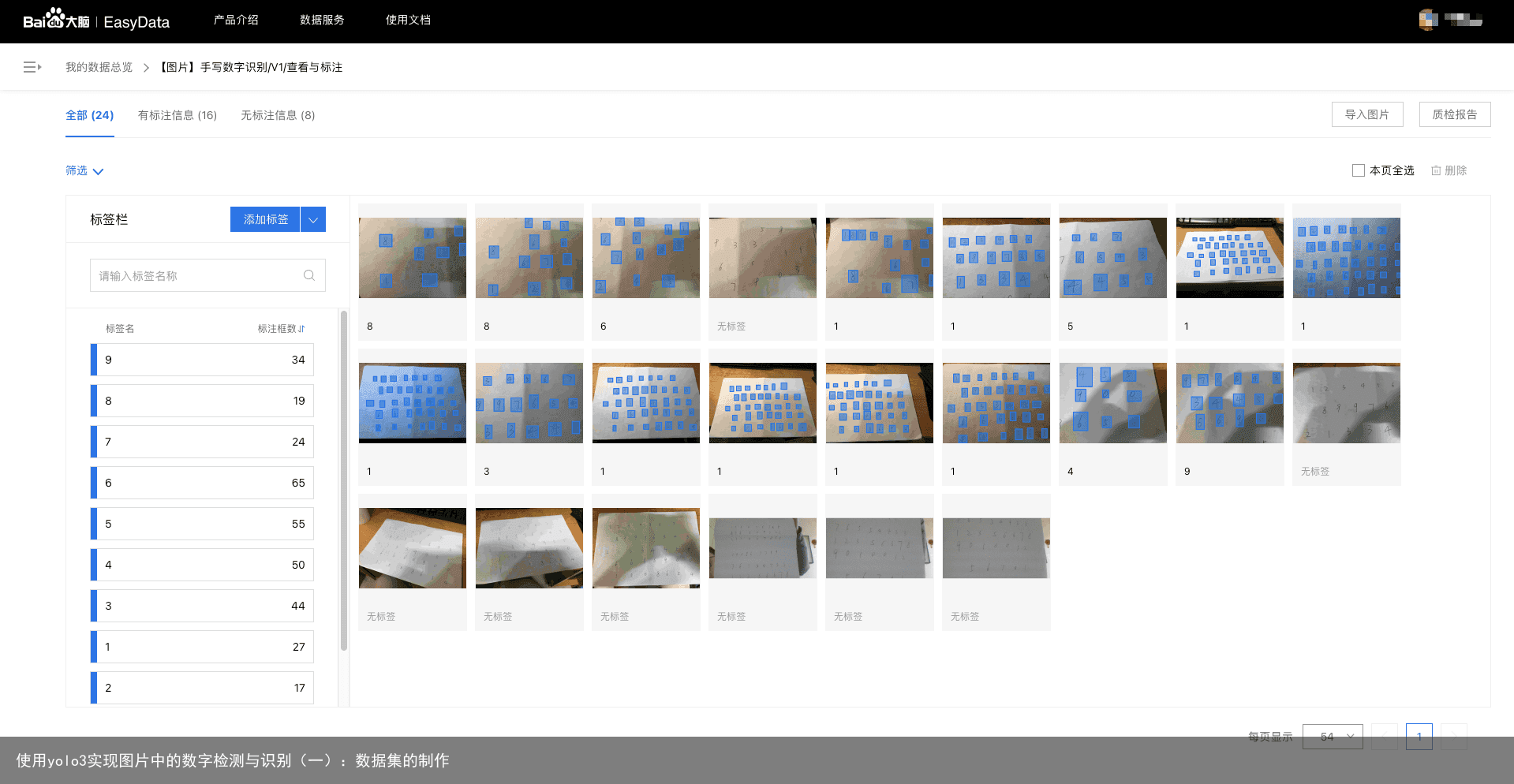 我们可以看到之前导入的所有本地数据,可以通过点击左上角的菜单栏查看我们的已标记数据和未标记数据。接着,我们点击“添加标签”,来添加我们标注的标签内容。这里,我们创建10个标签,分别对应数字0~9,可以看到,我已经添加完毕了并且已经标注了一些数据。在标注完一些数据后,我们可以很直观的看到每张图片的标签数以及每个标签的数据个数,十分方便。我们随便点开一张未标记的图片,进入单张图片标记模式:
我们可以看到之前导入的所有本地数据,可以通过点击左上角的菜单栏查看我们的已标记数据和未标记数据。接着,我们点击“添加标签”,来添加我们标注的标签内容。这里,我们创建10个标签,分别对应数字0~9,可以看到,我已经添加完毕了并且已经标注了一些数据。在标注完一些数据后,我们可以很直观的看到每张图片的标签数以及每个标签的数据个数,十分方便。我们随便点开一张未标记的图片,进入单张图片标记模式: 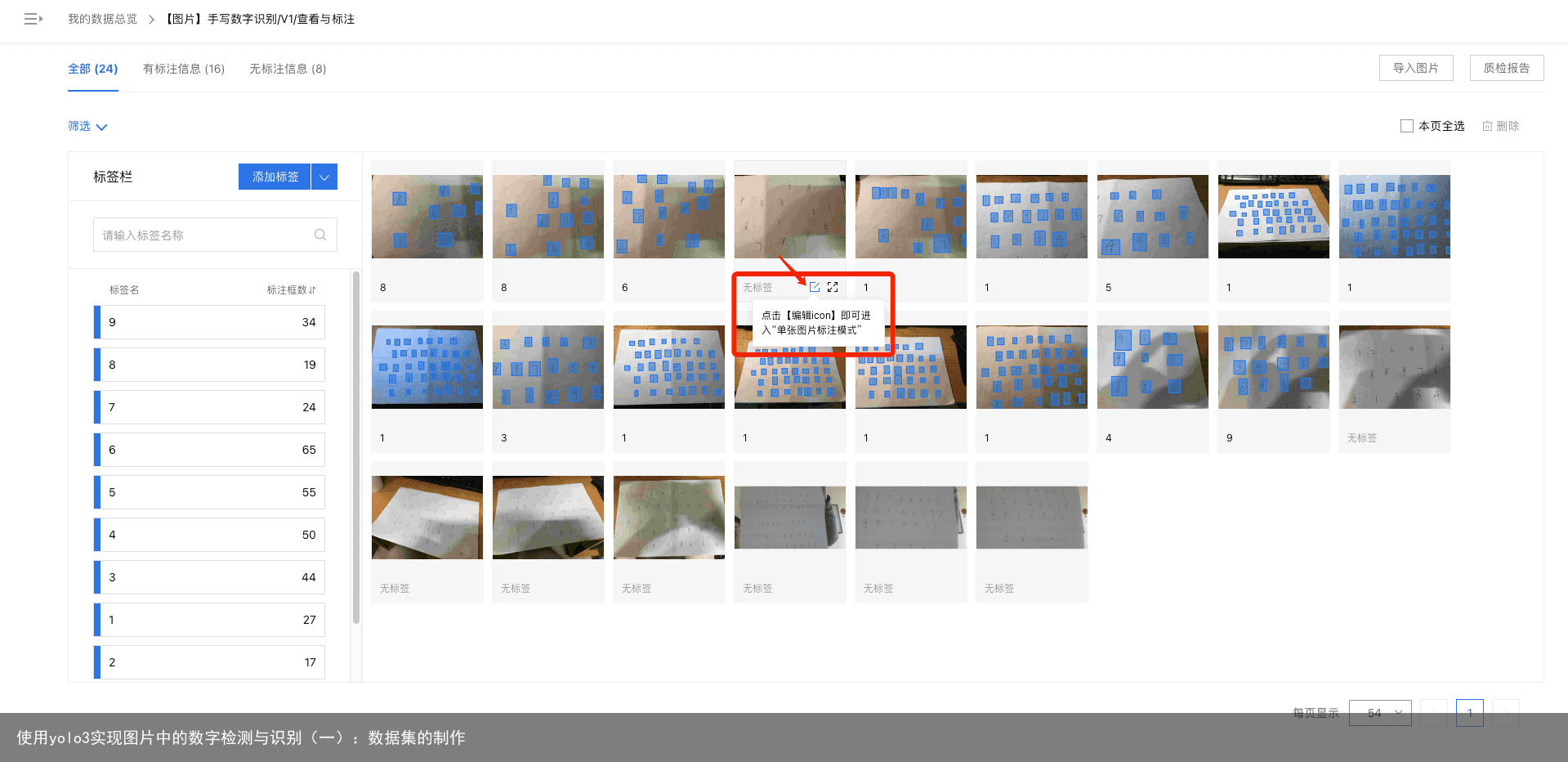
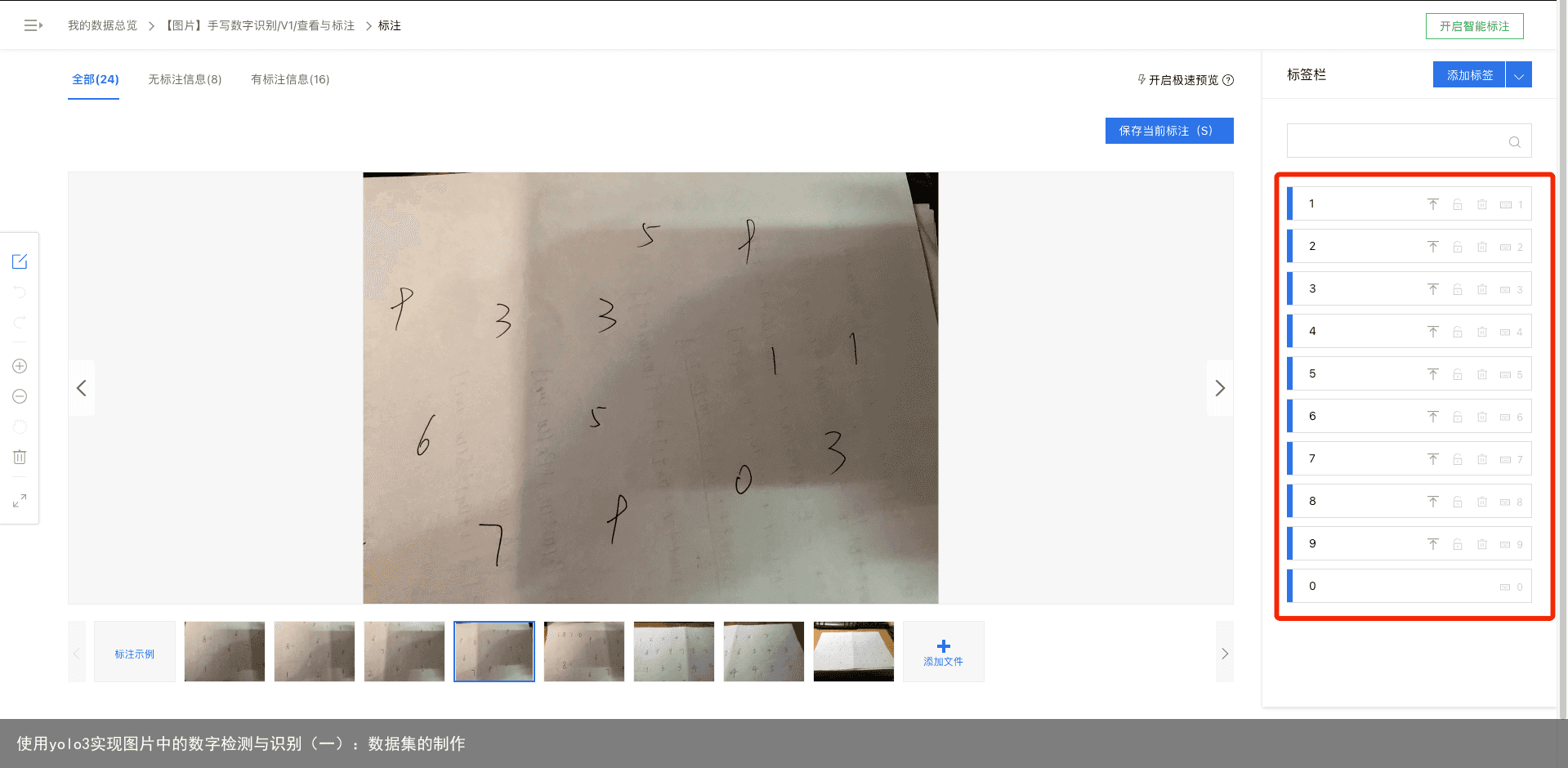 可以看到我们的所有标签都在页面右端显示,具体的标注流程为:在图像中用鼠标框住目标数字,然后在右边选择相应标签。如下图:我框住了数字5,然后点击右边相应数字5的标签。当然,我们也可以为标签设置快捷键,使用键盘上的数字0~9分别对应标签0~9,然后在框住目标数字后直接可以按下键盘上相应的快捷键进行标签的选择。 标记完成后,点击保存,页面会自动保存我们所标注的内容并切换到下一张图片。
可以看到我们的所有标签都在页面右端显示,具体的标注流程为:在图像中用鼠标框住目标数字,然后在右边选择相应标签。如下图:我框住了数字5,然后点击右边相应数字5的标签。当然,我们也可以为标签设置快捷键,使用键盘上的数字0~9分别对应标签0~9,然后在框住目标数字后直接可以按下键盘上相应的快捷键进行标签的选择。 标记完成后,点击保存,页面会自动保存我们所标注的内容并切换到下一张图片。 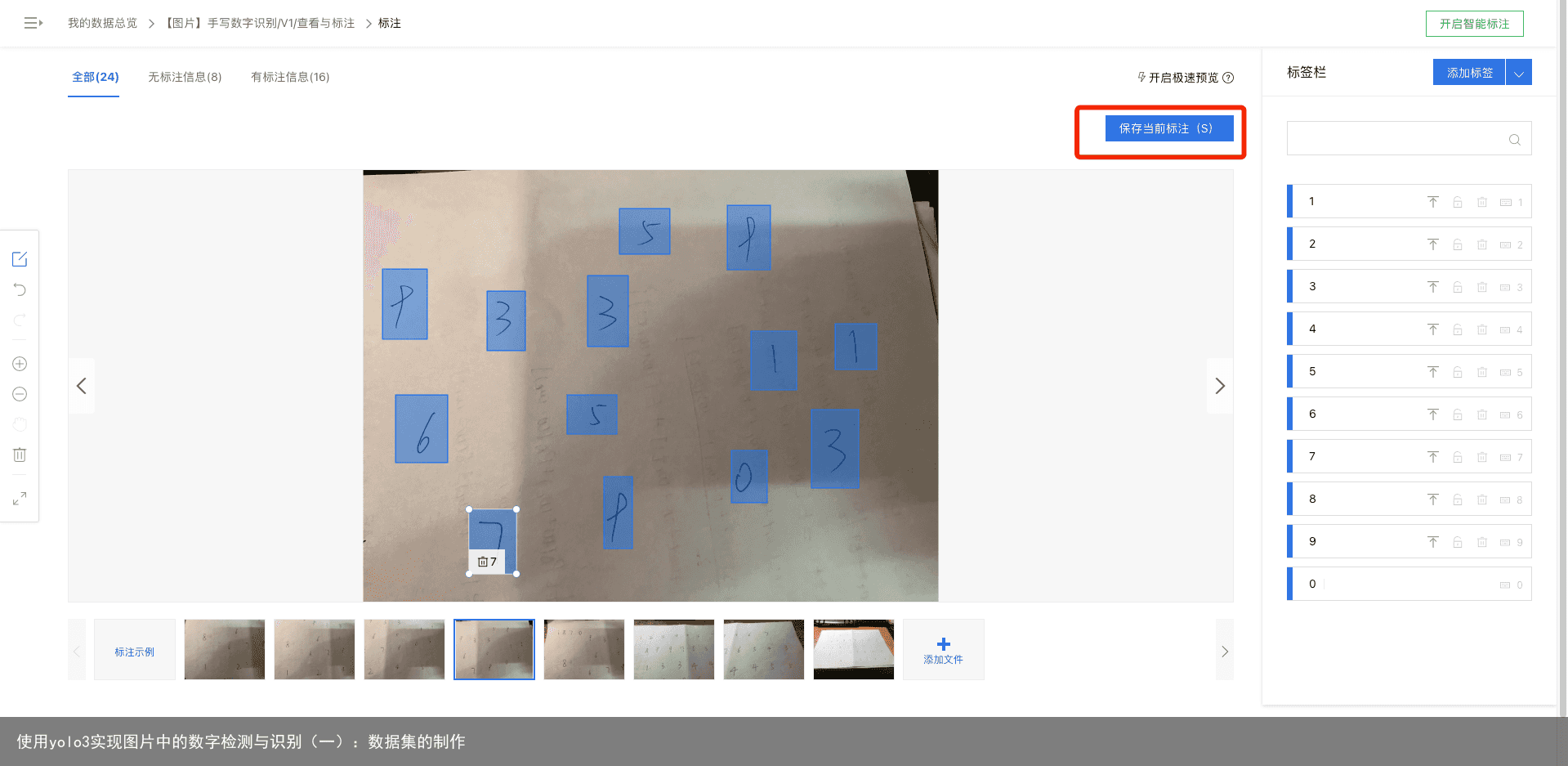 在手动标注一定量的数据后,我们就可以使用百度的智能标注功能了,如图:
在手动标注一定量的数据后,我们就可以使用百度的智能标注功能了,如图: 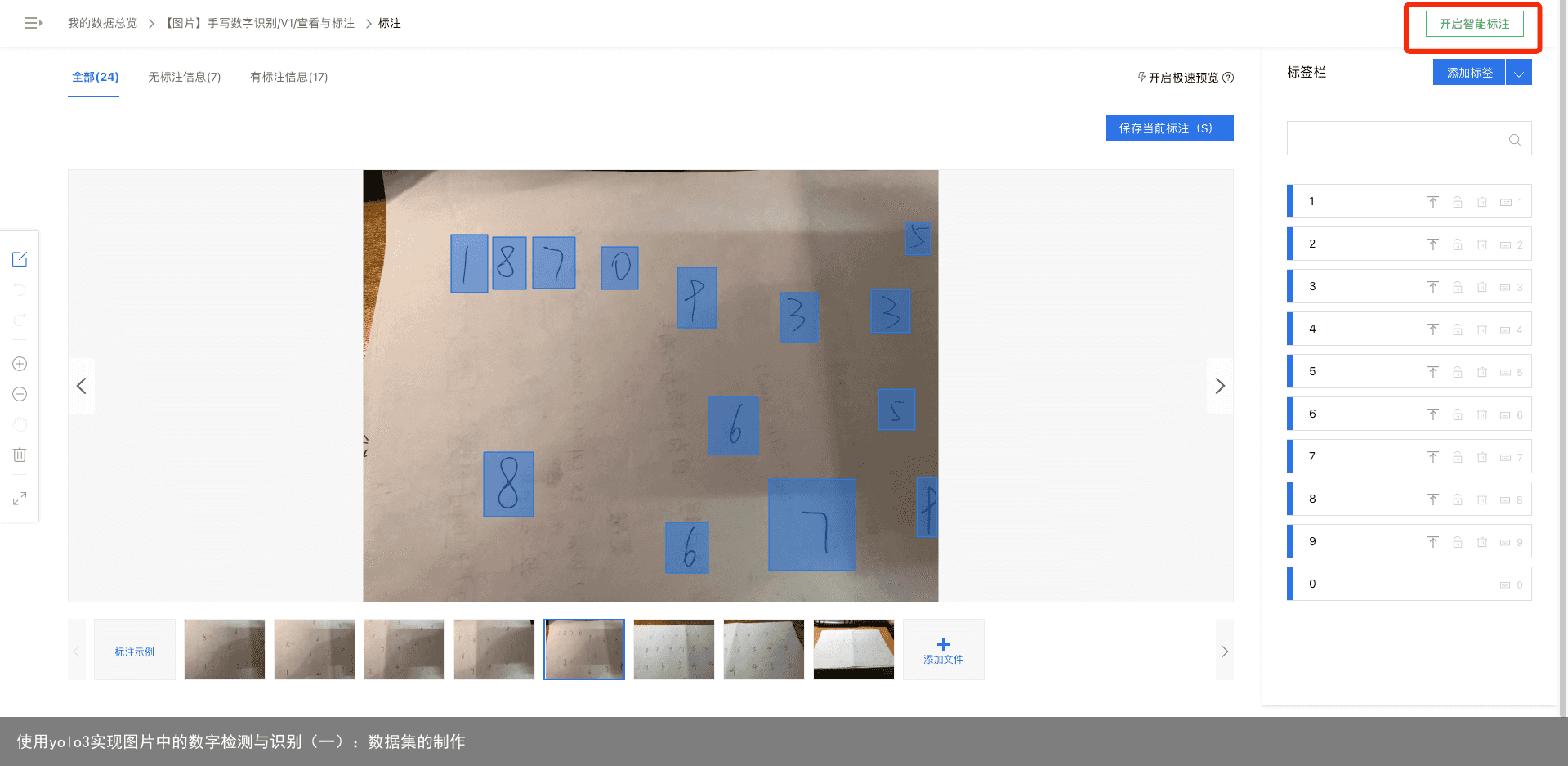
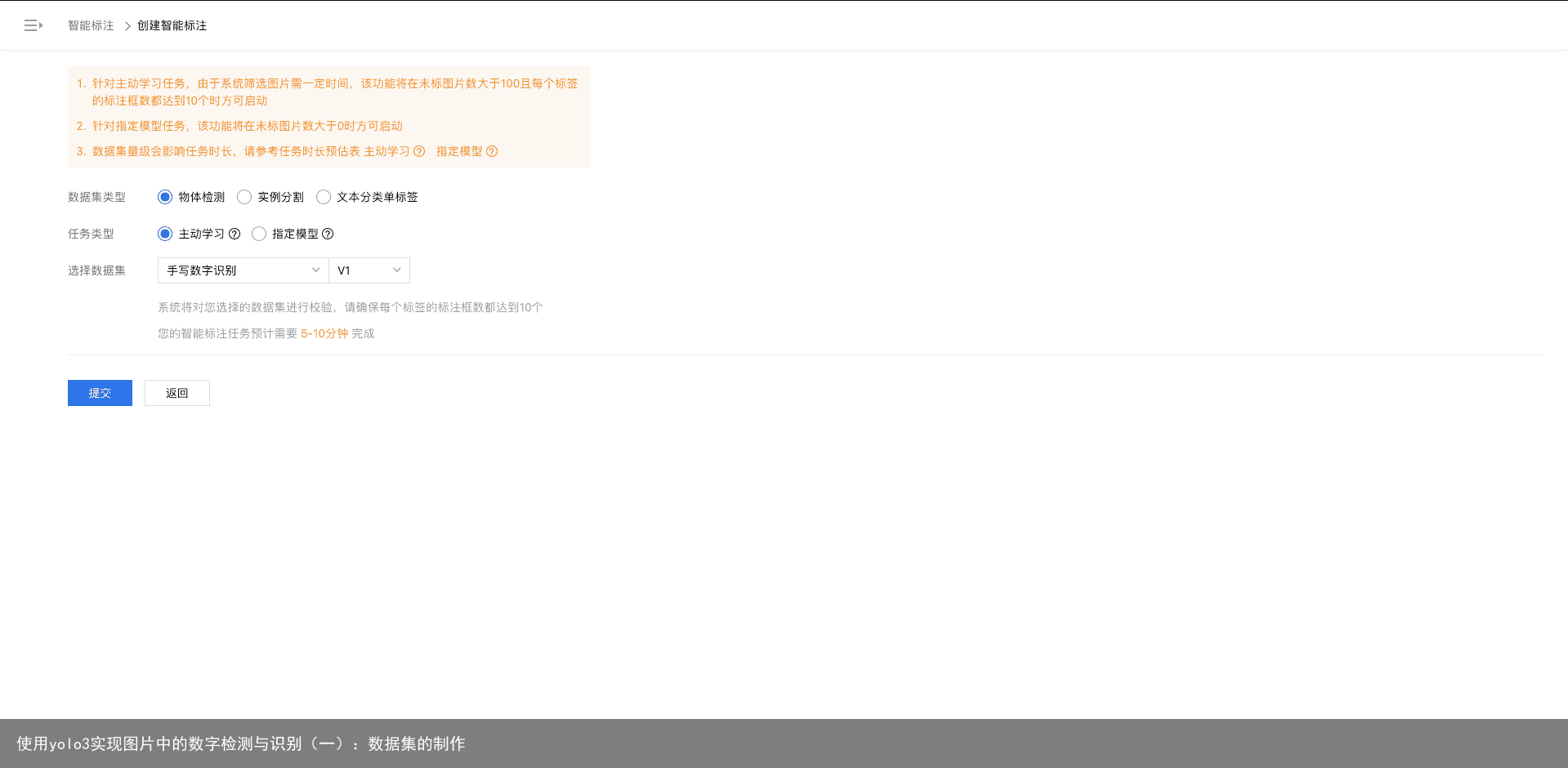 点击提交,系统便开始智能标注。智能标注的图像我们最好仔细检查一遍是否有标注错误的情况。 标注完成以后,返回到主页面(记得要保存哦)。我们也可以对数据进行清洗,比如去模糊、去除人体部分等,这里不再赘述。
点击提交,系统便开始智能标注。智能标注的图像我们最好仔细检查一遍是否有标注错误的情况。 标注完成以后,返回到主页面(记得要保存哦)。我们也可以对数据进行清洗,比如去模糊、去除人体部分等,这里不再赘述。  到这里需要注意的是,我们不能点“导出”,因为这样会导出到百度智能云,而不是导出到本地。而且从百度智能云下载数据好像还要收费(有点坑啊)。 我们直接将数据导入Aistudio即可。首先我们点击右边的省略号,接着点击“去训练”
到这里需要注意的是,我们不能点“导出”,因为这样会导出到百度智能云,而不是导出到本地。而且从百度智能云下载数据好像还要收费(有点坑啊)。 我们直接将数据导入Aistudio即可。首先我们点击右边的省略号,接着点击“去训练”  选择“Aistudio”,然后进入操作台
选择“Aistudio”,然后进入操作台 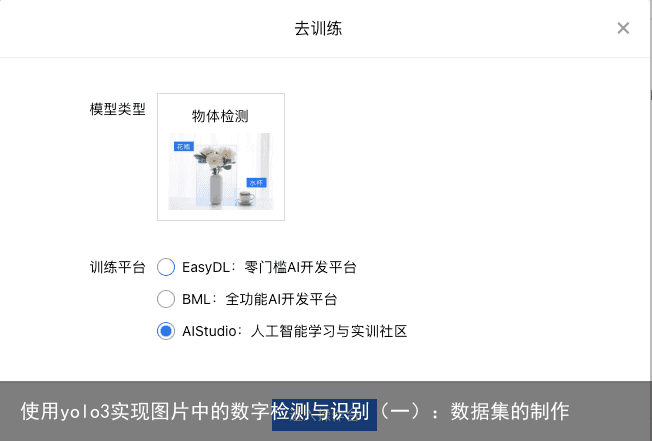 之后等待数据导入完成后点击“去训练”:
之后等待数据导入完成后点击“去训练”: 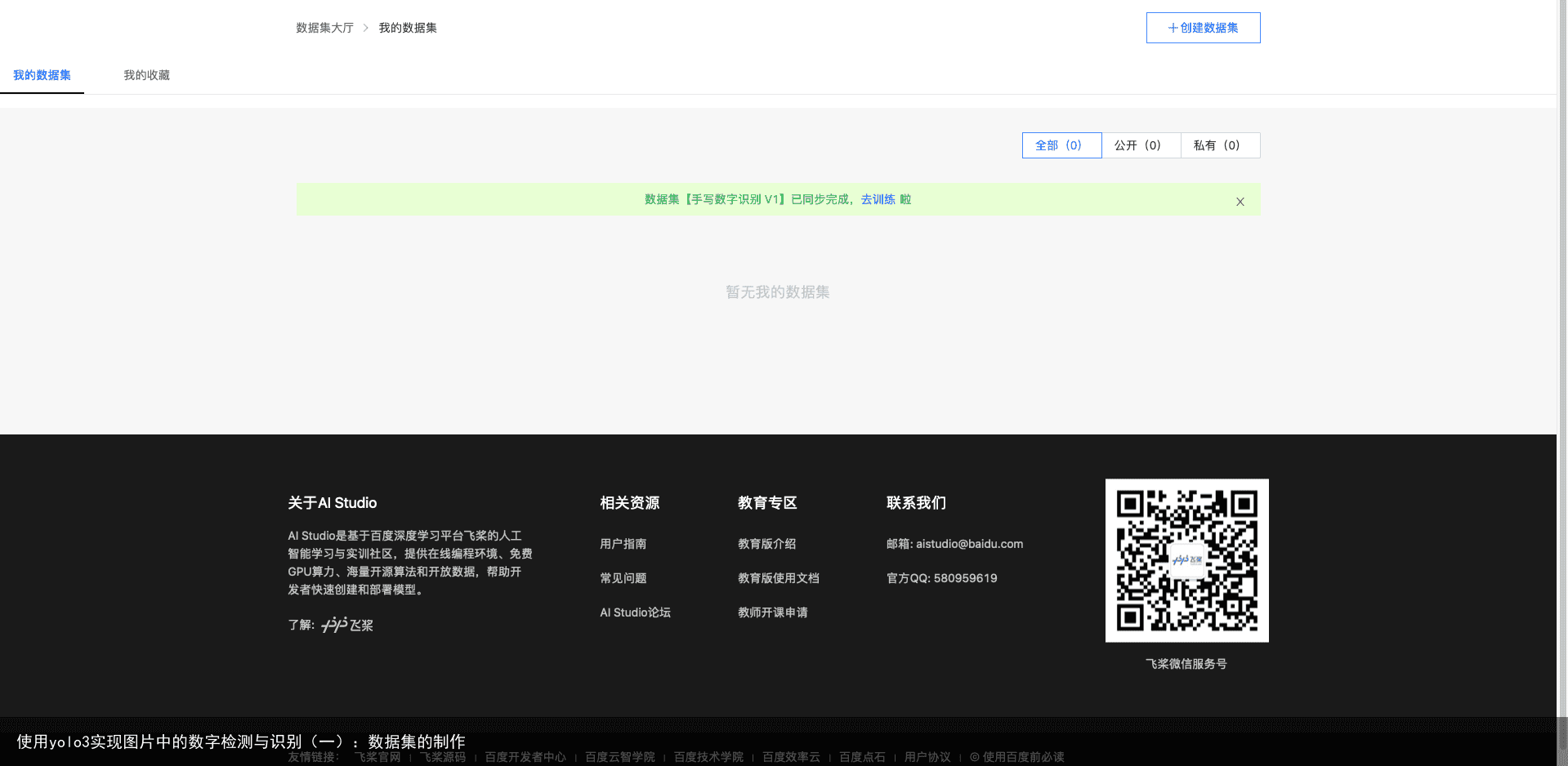 创建“notebook脚本应用”:
创建“notebook脚本应用”: 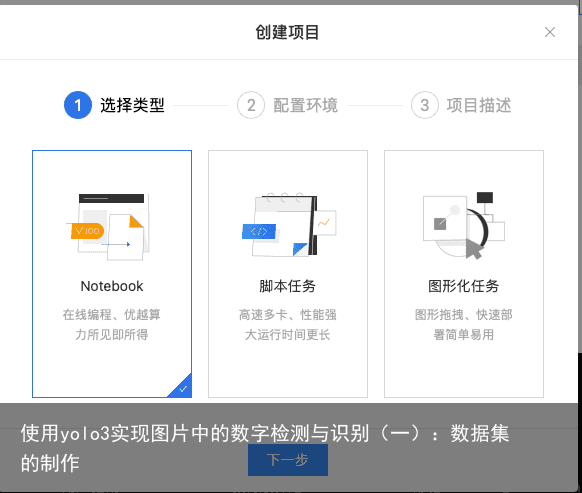 一路下一步,填写项目名称等必填内容,完成项目创建。这时我们可以进入环境查看我们的数据集,选cpu环境即可:
一路下一步,填写项目名称等必填内容,完成项目创建。这时我们可以进入环境查看我们的数据集,选cpu环境即可: 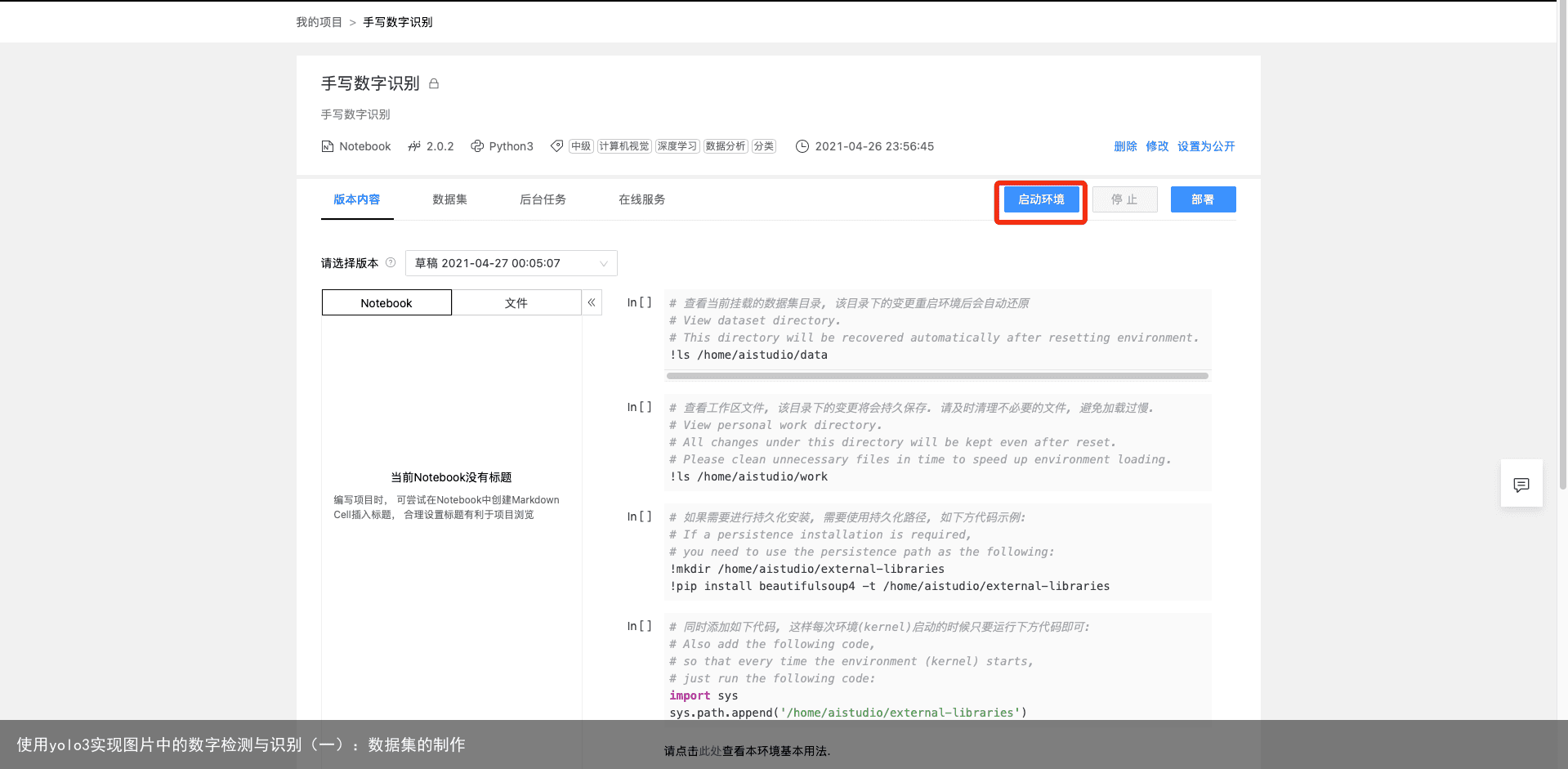
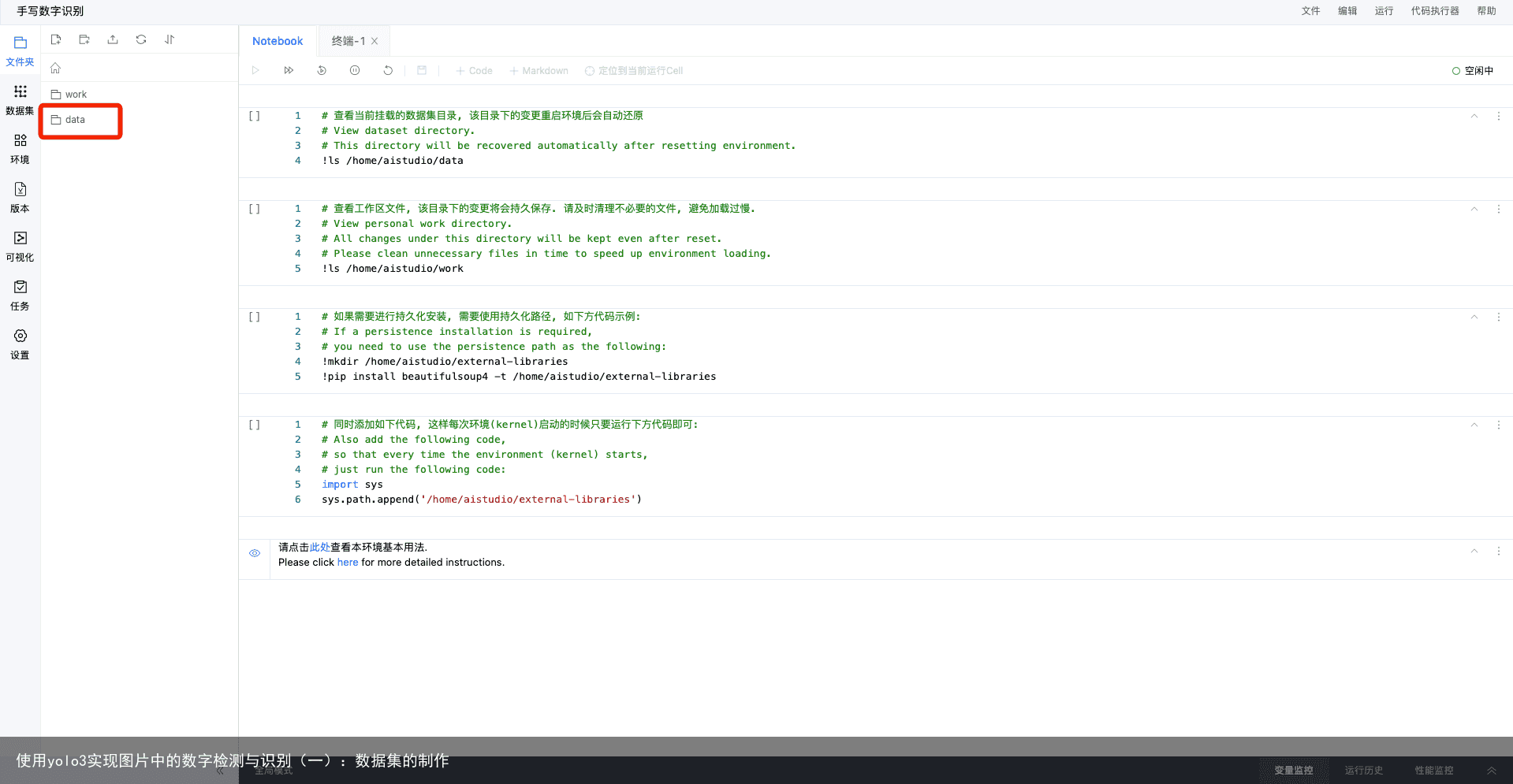 进入notebook运行环境以后,我们可以在右边编写代码,这个在后续文章中会详细说明,下面我们点击左边文件栏里的“data”:
进入notebook运行环境以后,我们可以在右边编写代码,这个在后续文章中会详细说明,下面我们点击左边文件栏里的“data”: 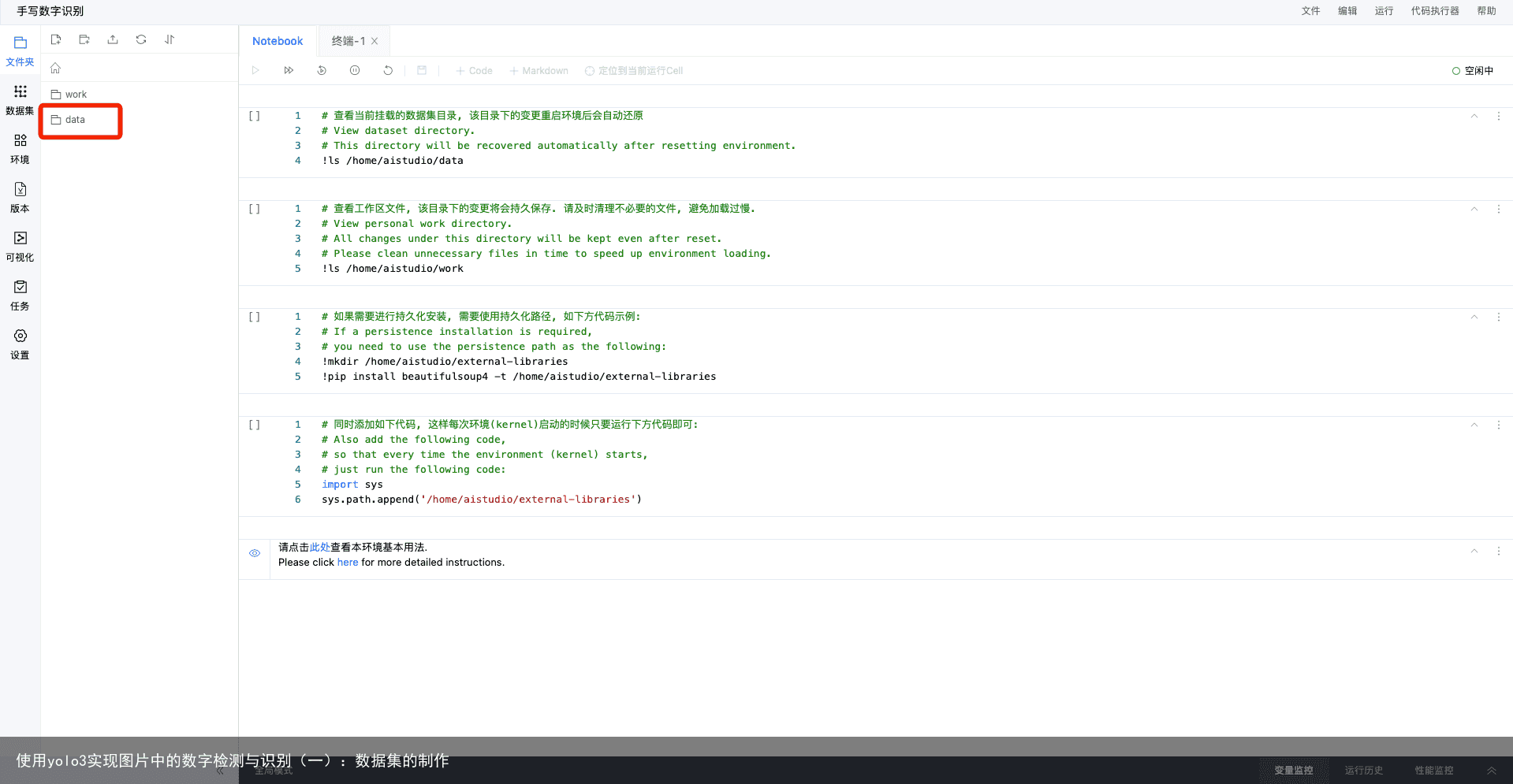
 进入文件夹最里层,便可以看到我们标注好的数据集。我们可以在这里免费下载数据集进行查看,也可以直接在Aistudio中解压数据集进行操作。需要注意的是,数据集的格式为通用格式,每一张图片对应一个.json文件,该文件记录了图片的尺寸、目标的位置以及类别等数据。若想制作VOC或者COCO的数据集,我们可以将数据集下载到本地,然后进行修改即可(相关格式的制作教程网上有很多,这里就不再赘述了)。下载数据集的方式如图: 将鼠标放在数据集文件上,会出现下载按钮,点击下载按钮即可。 数据集制作好以后,我们就可以开始编写代码了。
进入文件夹最里层,便可以看到我们标注好的数据集。我们可以在这里免费下载数据集进行查看,也可以直接在Aistudio中解压数据集进行操作。需要注意的是,数据集的格式为通用格式,每一张图片对应一个.json文件,该文件记录了图片的尺寸、目标的位置以及类别等数据。若想制作VOC或者COCO的数据集,我们可以将数据集下载到本地,然后进行修改即可(相关格式的制作教程网上有很多,这里就不再赘述了)。下载数据集的方式如图: 将鼠标放在数据集文件上,会出现下载按钮,点击下载按钮即可。 数据集制作好以后,我们就可以开始编写代码了。
好了,本篇文章到此为止,之后的文章中,我们将为大家介绍数据集的导入以及yolo v3算法的实现。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:使用yolo3实现图片中的数字检测与识别(一):数据集的制作 https://www.yhzz.com.cn/a/12524.html