在导入数据至模型之前,我们首先需要读取数据集的标注信息并将其转换为我们需要的格式。本篇文章将为大家介绍如何进行数据集标注信息的读取以及格式的转化。
首先我们来观察一下我们导入的数据集的结构:  每一张图片对应一个.jpeg图像文件以及一个.json文件,我们打开之前文章中经常处理的那张图片,即7.jpeg,就是这张:
每一张图片对应一个.jpeg图像文件以及一个.json文件,我们打开之前文章中经常处理的那张图片,即7.jpeg,就是这张:  对应的.json文件为7.json,部分信息如图:
对应的.json文件为7.json,部分信息如图:  我们从第二行开始分析:”labels”后面写着”9 items”,这个意思就是这张图片里面有9组标签,而图中正好有9个数字。因此这9组标签就分别对应了这9个目标数字的信息。从.json文件同样可以看出,每组标签有6个属性,分别是目标类别名称、标记的目标真实边界框的四个坐标值以及图像的尺寸(宽、高)。从这些信息我们可以直观得到第一个标签和第二个标签的类别分别是4和5,如图:
我们从第二行开始分析:”labels”后面写着”9 items”,这个意思就是这张图片里面有9组标签,而图中正好有9个数字。因此这9组标签就分别对应了这9个目标数字的信息。从.json文件同样可以看出,每组标签有6个属性,分别是目标类别名称、标记的目标真实边界框的四个坐标值以及图像的尺寸(宽、高)。从这些信息我们可以直观得到第一个标签和第二个标签的类别分别是4和5,如图: 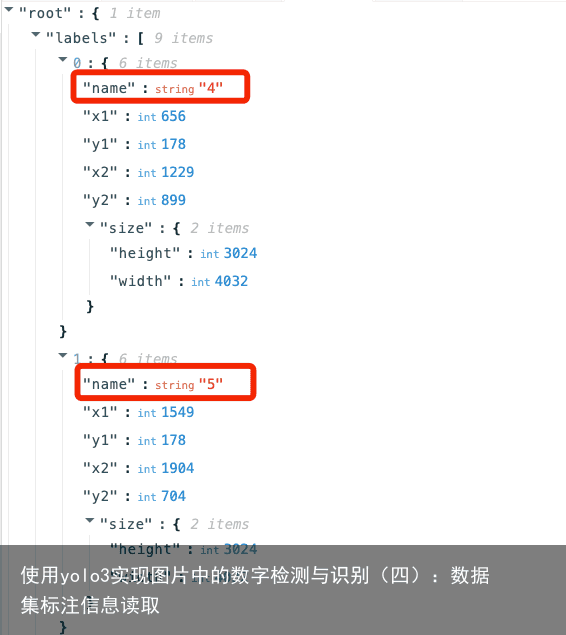 从图像中我们可以得到验证:
从图像中我们可以得到验证:  所以,基本上.json文件以及标注了关于数据集的所有信息。但是我们在进行训练时,这些数据不能直接写入我们的yolo模型,我们需要将其变换成相应的格式,才能输入至模型进行后续的操作。这就是这篇文章的主要任务。熟悉json文件的朋友们都清楚,json的数据格式和python的字典非常相似,因此我们可以将.json文件中的数据转换成python中的字典形式存储。
所以,基本上.json文件以及标注了关于数据集的所有信息。但是我们在进行训练时,这些数据不能直接写入我们的yolo模型,我们需要将其变换成相应的格式,才能输入至模型进行后续的操作。这就是这篇文章的主要任务。熟悉json文件的朋友们都清楚,json的数据格式和python的字典非常相似,因此我们可以将.json文件中的数据转换成python中的字典形式存储。
我们可以使用readline()函数进行逐行读取,我们打开7.json文件,先读取一行进行观察:
filename=/home/aistudio/work/DatasetId_158445_1619847762/7.json# json文件的路径 with open(filename) as f: line=f.readline() print(line) f.close()运行结果为:  对比我们手动打开的7.json文件,我们发现,所有信息都已被读取,因此我们只需要使用readline()函数进行第一行数据的读取即可。但是需要注意的是,使用readline()函数读取的数据格式为字符串格式,并不是我们需要的字典格式,因此我们还需要将其转换为字典。这里我们需要用到json库中的json.loads()函数,将数据转换成python字典格式,并读取第一个目标数据:
对比我们手动打开的7.json文件,我们发现,所有信息都已被读取,因此我们只需要使用readline()函数进行第一行数据的读取即可。但是需要注意的是,使用readline()函数读取的数据格式为字符串格式,并不是我们需要的字典格式,因此我们还需要将其转换为字典。这里我们需要用到json库中的json.loads()函数,将数据转换成python字典格式,并读取第一个目标数据:
运行结果为:  至此,我们已经实现了单个json的读取以及向字典形式的转化。
至此,我们已经实现了单个json的读取以及向字典形式的转化。
接下来,我们需要读取所有json文件,将所有数据的标注数据以数组的形式存储下来。该数组的每一个元素代表一张图像,数组中元素的个数即为数据集中图像的个数。每个元素均为字典形式,其中储存了每张图像中的每一个目标信息。为了方便后期读取,我们在一张图像中,将所有目标的相同属性以numpy矩阵的形式存储在一起,而不是像原始json文件那样每个目标的信息单独存储,其格式如下:  与图像相对应的字典分别具有以下元素:
与图像相对应的字典分别具有以下元素:
以下是具体的代码实现。
首先,读取目标路径下的所有文件。
dirname=/home/aistudio/work/DatasetId_158445_1619847762# json文件的路径 dirlist=os.listdir(dirname)# 列出路径下所有文件,包括jpeg图像 dirlist运行结果:  可以看到,所有jpeg文件和json文件存储在一起,因此我们需要将它们分开,单独读取json文件。
可以看到,所有jpeg文件和json文件存储在一起,因此我们需要将它们分开,单独读取json文件。
运行结果:  可以看出,我们已经将json文件单独提取出来了,下面就是对每个json文件的单独操作。我们按顺序读取每一个json文件,然后按照上述格式,转换成新的数组形式:
可以看出,我们已经将json文件单独提取出来了,下面就是对每个json文件的单独操作。我们按顺序读取每一个json文件,然后按照上述格式,转换成新的数组形式:
读取转换完成后,我们来查看一下效果,这是我们的第二组数据,也就是原来的7.jpeg图像的数据:
datas[2]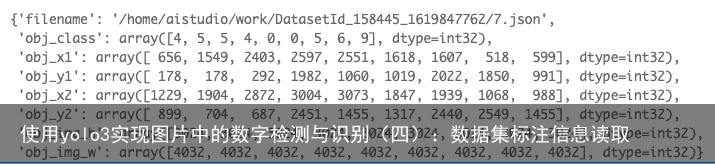 以及按照要求转换完毕。我们来查看一下该数组的大小:
以及按照要求转换完毕。我们来查看一下该数组的大小:
说明23张图像数据已经全部导入。 下面是完整代码:
import json import numpy as np import os dirname=/home/aistudio/work/DatasetId_158445_1619847762# json文件的路径 dirlist=os.listdir(dirname)# 列出路径下所有文件,包括jpeg图像 datas=[] for filename in dirlist: if os.path.splitext(filename)[1]==.json:# 筛选出json文件 filename_full=os.path.join(dirname,filename)# 字符串合并,将文件名与目录路径合并,转化为绝对路径 with open(filename_full) as f: line=f.readline()# 读取一行,读出来为字符串形式 d=json.loads(line)# 将数据由字符串格式转换为字典格式 nobjs=len(d[labels])# 读取一幅图像中目标个数 # 创建新的字典,将同一副图中的每个目标属性以np矩阵的形式储存 obj_class=np.zeros(nobjs,dtype=np.int32)# 每个目标归属类别 # bbox框坐标,以xyxy形式储存 obj_x1=np.zeros(nobjs,dtype=np.int32) obj_y1=np.zeros(nobjs,dtype=np.int32) obj_x2=np.zeros(nobjs,dtype=np.int32) obj_y2=np.zeros(nobjs,dtype=np.int32) # 图像尺寸 obj_img_h=np.zeros(nobjs,dtype=np.int32) obj_img_w=np.zeros(nobjs,dtype=np.int32) for idx in range(nobjs): obj_class[idx]=np.array(d[labels][idx][name]) obj_x1[idx]=np.array(d[labels][idx][x1]) obj_y1[idx]=np.array(d[labels][idx][y1]) obj_x2[idx]=np.array(d[labels][idx][x2]) obj_y2[idx]=np.array(d[labels][idx][y2]) obj_img_h[idx]=np.array(d[labels][idx][size][height]) obj_img_w[idx]=np.array(d[labels][idx][size][width]) objs={ filename:filename_full, obj_class:obj_class, obj_x1:obj_x1, obj_y1:obj_y1, obj_x2:obj_x2, obj_y2:obj_y2, obj_img_h:obj_img_h, obj_img_w:obj_img_w } datas.append(objs) f.close()至此,我们已经读取所有的标注信息并且转换成了我们需要的格式。后面的文章,我将继续为大家介绍如何进行数据读取以及数据的预处理。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:使用yolo3实现图片中的数字检测与识别(四):数据集标注信息读取 https://www.yhzz.com.cn/a/12482.html