【深度学习】像素级分割网络新思路之DeepLabv3+
1 版本情况 2 引言&相关工作 3 空洞卷积(Dilated/Atrous Convolution) 4 DeepLabv3+ 5 深度可分离卷积(Depthwise separable convolution) 5.1 逐通道卷积(Depthwise Convolution) 5.2 逐点卷积(Pointwise Convolution) 6 实验(Miou) 1 版本情况这是在DeepLabV1、2基础上的再扩展; V1 主要是将VGG最后两个的池化改成了stride=1,然后采用了空洞卷积来扩大感受野,上采样使用了双线性插值;
V2主要是在模型最后进行像素分类之前增加一个类似 Inception 的结构,即ASPP模块,通过不同rate得到不同尺度的特征图,再进行预测;
V3 主要是对之前模块的升级,从而提升性能。
2 引言&相关工作一般的分割存在两个挑战,一个是分辨率的下降(由下采样导致),常常采用空洞卷积来代替池化解决,效果不错;
另一个是存在多个尺度的物体,需要多尺度特征图融合,主要有以下四种模型: 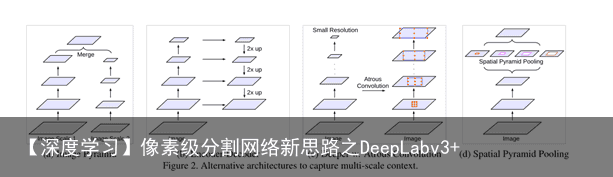
空洞卷积(Dilated/Atrous Convolution),广泛应用于语义分割与目标检测等任务中,语义分割中经典的deeplab系列与DUC对空洞卷积进行了深入的思考。目标检测中SSD与RFBNet,同样使用了空洞卷积。
空洞卷积的作用 空洞卷积有什么作用呢?
扩大感受野:在deep net中为了增加感受野且降低计算量,总要进行降采样(pooling或s2/conv),这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测,分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。 捕获多尺度上下文信息:空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。多尺度信息在视觉任务中相当重要啊。 从这里可以看出,空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。
ps: 空洞卷积虽然有这么多优点,但在实际中不好优化,速度会大大折扣。
标准卷积:以3*3为例,以下分辨率不变与分辨率降低的两个实例;

 空洞卷积:在3*3卷积核中间填充0,有两种实现方式,第一,卷积核填充0,第二,输入等间隔采样。
空洞卷积:在3*3卷积核中间填充0,有两种实现方式,第一,卷积核填充0,第二,输入等间隔采样。
 标准卷积与空洞卷积在实现上基本相同,标准卷积可以看做空洞卷积的特殊形式。看到这,空洞卷积应该不那么陌生了。。
标准卷积与空洞卷积在实现上基本相同,标准卷积可以看做空洞卷积的特殊形式。看到这,空洞卷积应该不那么陌生了。。
空洞卷积(dilated convolution)是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv。
利用添加空洞扩大感受野,让原本3 x3的卷积核,在相同参数量和计算量下拥有5×5(dilated rate =2)或者更大的感受野,从而无需下采样。扩张卷积(dilated convolutions)又名空洞卷积(atrous convolutions),向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。换句话说,相比原来的标准卷积,扩张卷积(dilated convolution) 多了一个hyper-parameter(超参数)称之为dilation rate(扩张率),指的是kernel各点之前的间隔数量,正常的convolution 的 dilatation rate为 1。
4 DeepLabv3+Spatial pyramid pooling: DeepLab在不同的网格尺度上(包括image-level pooling)进行空间金字塔池化,或者说对不同层并行施加不同rate的atrous卷积(这就叫做Atrous Spatial Pyramid Pooling, ASSP)。这种处理方法特别适用于获取多尺度信息。
Encoder-decoder: 一般来说,编码-解码器网络包含了(1)一个编码器模块,用于逐步减小特征图,同时捕获更高级的语义信息;(2)一个解码器模块,用于逐步恢复空间信息。基于此,如图2所示,本文中作者将DeepLab V3作为编码器模块,在不同尺度应用不同rate的atrous卷积,来编码多尺度的上下文信息;同时在其后加入一个解码器模块,沿着物体边界进行优化,从而获取更锐利的分割结果。 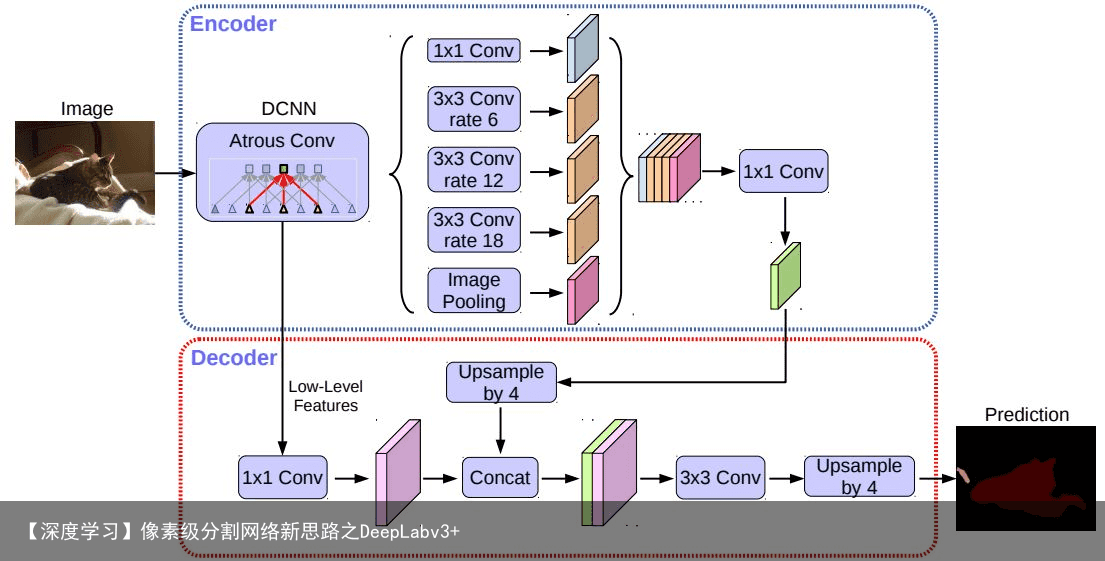
Depthwise separable convolution: 深度可分离卷积将标准卷积分解为逐通道卷积,然后再进行逐点卷积(即1×1卷积),从而大大降低了计算复杂度。 具体来说,针对每个输入通道,逐通道卷积独立执行空间卷积,而逐点卷积用于组合逐通道卷积的输出。 在TensorFlow 的深度可分离卷积实现中,逐通道卷积(比如说空间卷积)已经支持atrous卷积了,如图3所示。作者将文中所采用的卷积称为atrous可分离卷积, 并发现该卷积显著降低了所提出模型的计算复杂度,同时保持了相似(或更好)的性能。
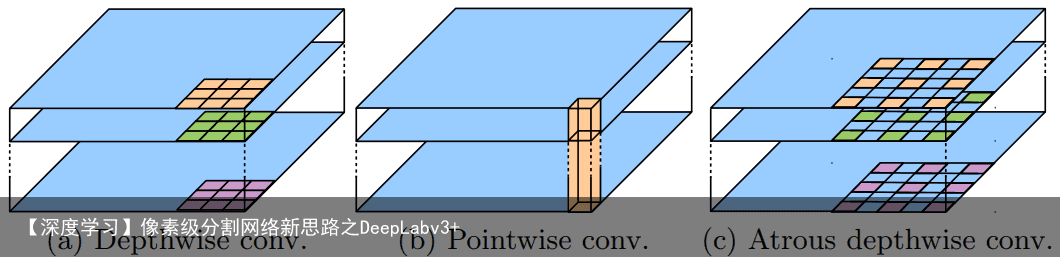
一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map。相比常规的卷积操作,其参数数量和运算成本比较低。
常规卷积操作
对于5x5x3的输入,如果想要得到3x3x4的feature map,那么卷积核的shape为3x3x3x4(即:);如果padding=1,那么输出的feature map为5x5x4。
 度可分离卷积
度可分离卷积
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
5.1 逐通道卷积(Depthwise Convolution)
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样。
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5).
5.2 逐点卷积(Pointwise Convolution)
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。(卷积核的shape即为:1 x 1 x 输入通道数 x 输出通道数)
6 实验(Miou)decoder结构上的探索 训练时上采样输出结果比下采样真值提升1.2% 低层次信息通道数多少个比较合适(1×1卷积的通道数)
 哪个底层的细节信息较好&3×3的卷积如何构成
哪个底层的细节信息较好&3×3的卷积如何构成 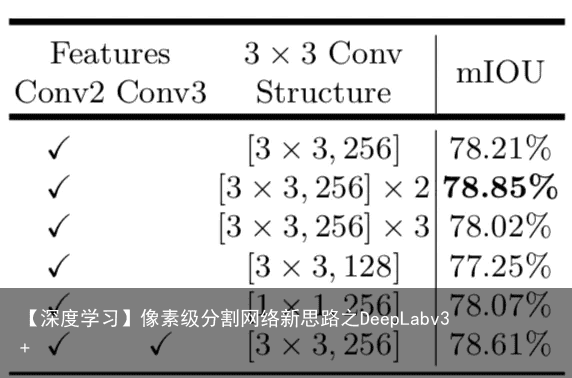 作者验证了U-Net和SegNet类似的解码结构在此网络上并没有多少提升 在Cityscapes数据集上
作者验证了U-Net和SegNet类似的解码结构在此网络上并没有多少提升 在Cityscapes数据集上 
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】像素级分割网络新思路之DeepLabv3+ https://www.yhzz.com.cn/a/12471.html