【深度学习】利用深度可分离卷积减小计算量及提升网络性能
文章目录 1 深度可分离卷积 2 一个深度可分离卷积层的代码示例(keras) 3 优势与创新 3.1 Depthwise 过程 3.2 Pointwise 过程 4 Mobilenet v1 5 Xception 1 深度可分离卷积深度可分离卷积提出了一种新的思路:对于不同的输入channel采取不同的卷积核进行卷积,它将普通的卷积操作分解为两个过程。
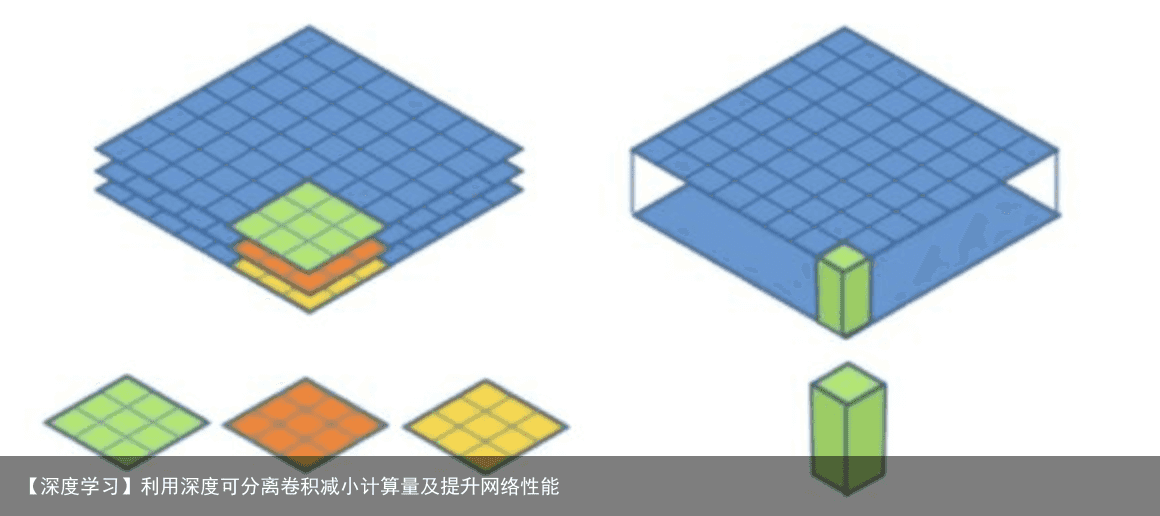


深度可分离卷积层对每个channel分别执行卷积,然后通过逐点卷积将这些输出混合。这相当于将空间特征和channel特征的学习分开。如果你的输入在空间位置高度相关,但不同的通道之间相对独立,那么这种做法可以减少参数数量,降低计算量。 因此,深度可分离卷积可以更加的轻量、速度更快,有时还能让任务的性能提升。
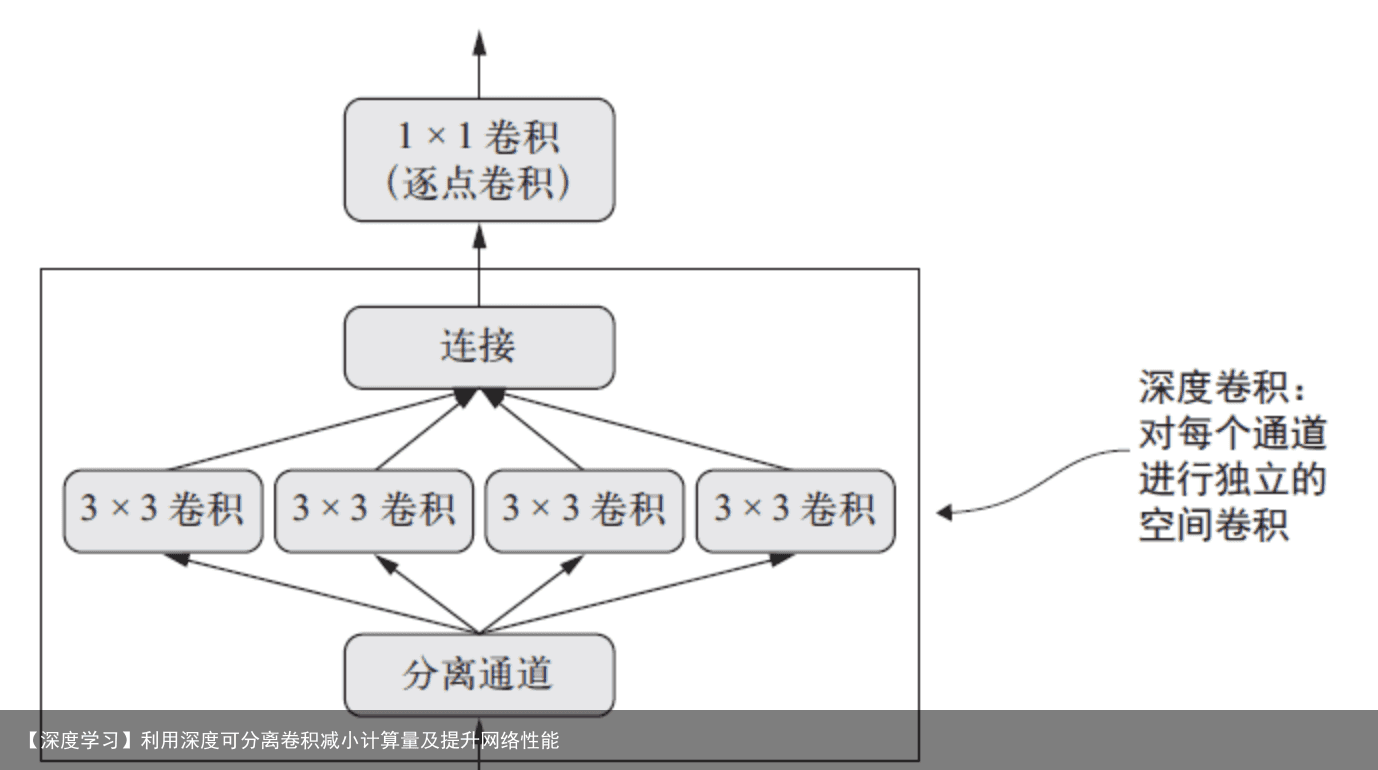
Depthwise+Pointwise可以近似看作一个卷积层:
普通卷积:3×3 Conv+BN+ReLU Mobilenet卷积:3×3 Depthwise Conv+BN+ReLU 和 1×1 Pointwise Conv+BN+ReLU
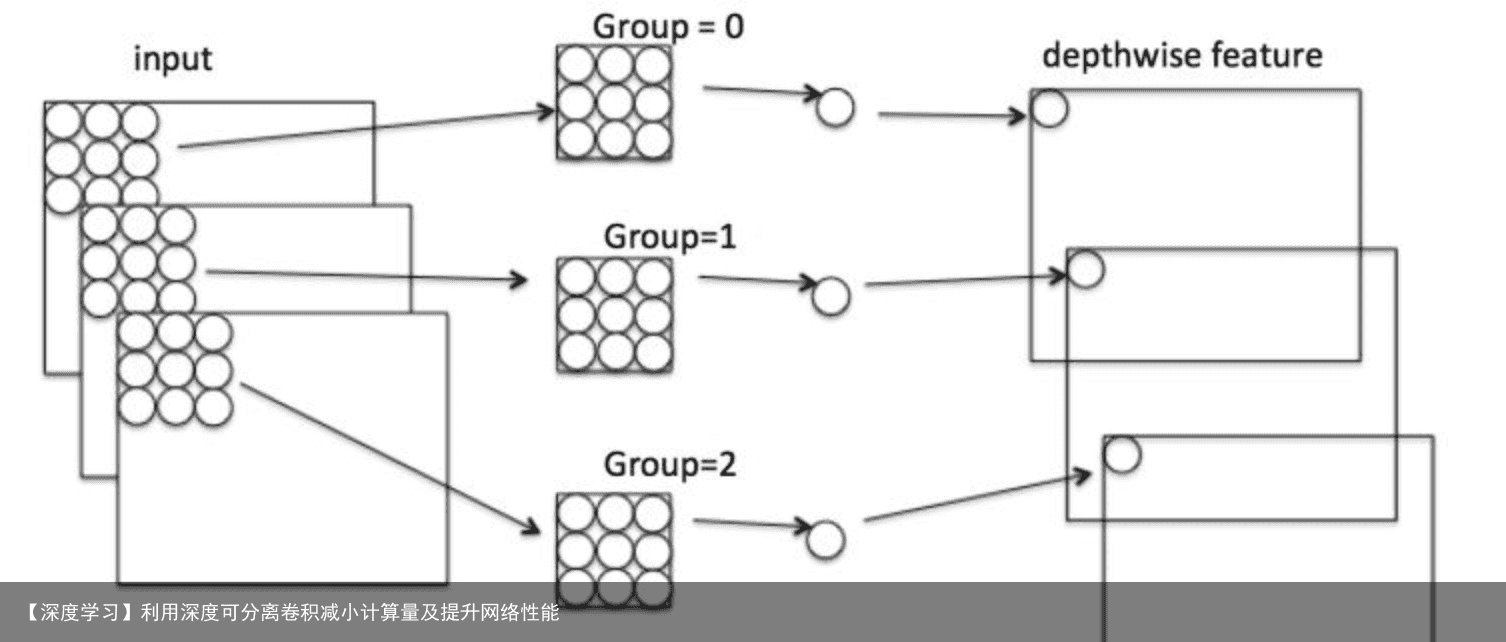
3. 1 Depthwise 过程
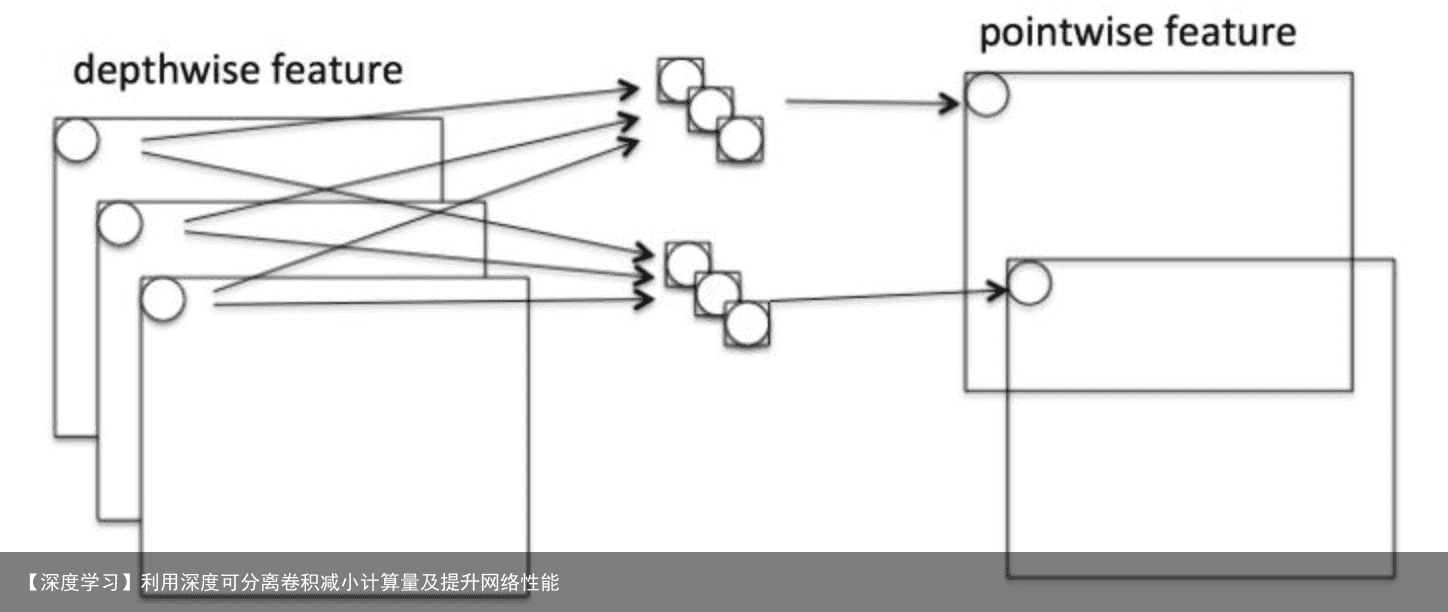
3. 2 Pointwise 过程
Mobilenet v1利用深度可分离卷积进行加速,MobileNets结构建立在深度可分解卷积中(只有第一层是标准卷积)。该网络允许算法探索网络拓扑,找到一个适合的良好网络。其具体架构在表1说明。除了最后的全连接层,所有层后面跟了batchnorm和ReLU,最终输入到softmax进行分类。图3对比了标准卷积和分解卷积的结构,二者都附带了BN和ReLU层。按照原文的计算方法,MobileNets总共28层(1 + 2 × 13 + 1 = 28), 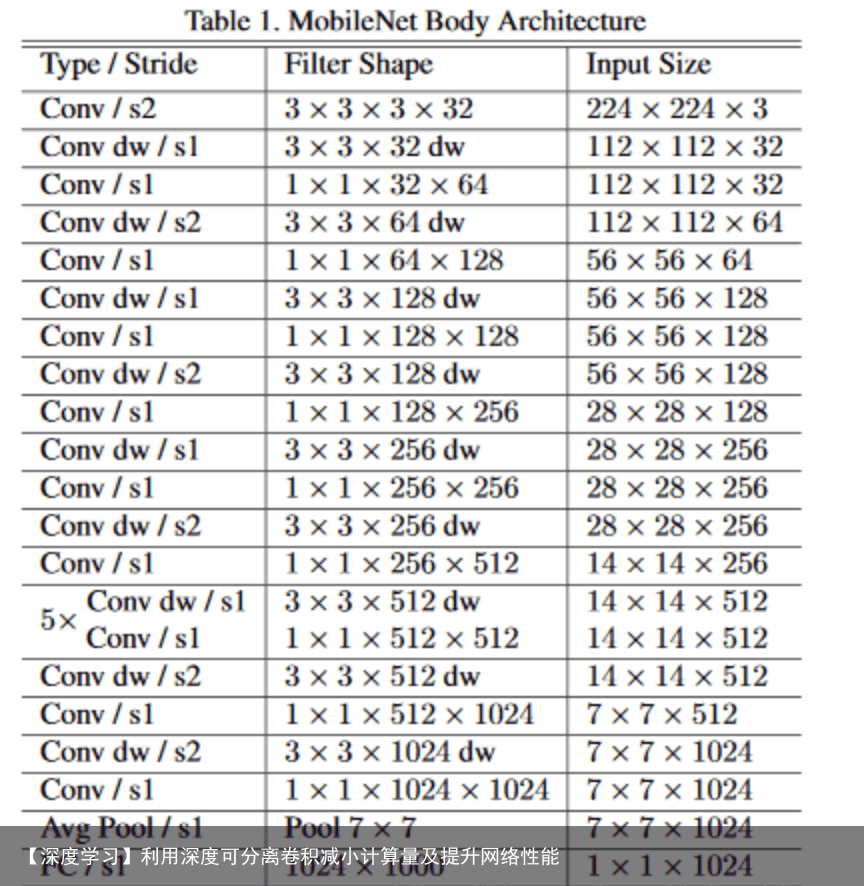 MobileNet将95%的计算时间用于有75%的参数的1×1卷积,其他额外的参数几乎都集中于全连接层,在论文中,采用tensorflow框架进行训练。
MobileNet将95%的计算时间用于有75%的参数的1×1卷积,其他额外的参数几乎都集中于全连接层,在论文中,采用tensorflow框架进行训练。  目标检测结果
目标检测结果
网络的整个流程如下图所示,Xception架构有36个卷积层作为网络特征提取的基础,这36个卷积层被分为14个模块,除了第一个和最后一个,其他每一个模块都使用了残差连接。 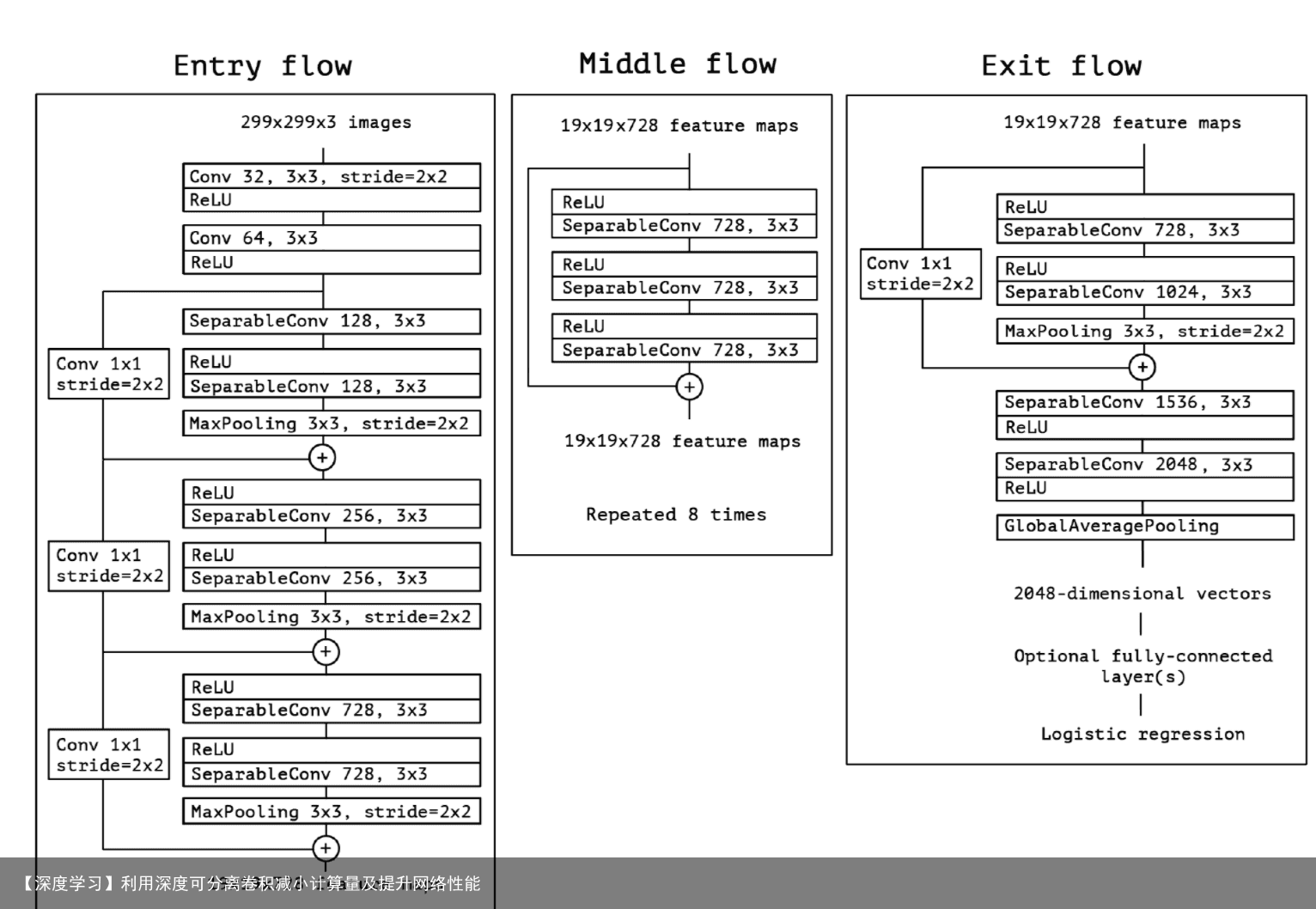
简而言之,Xception架构是一个深度可分离卷积层的线性叠加,这个架构易于修改,仅使用30-40行代码就可以完成。 细节:
验证 实验在两个大型的图片分类数据集上进行,将Xception和Inception V3进行比较(二者拥有几乎相同的参数数量)。 JFT dataset JFT是一个大规模图片分类数据集,包括3.5亿张高清图像,和17000个类别。实验使用FastEval14k这个数据集即从中选取包含6000个类别的14000张图像 。 优化参数设置 在ImageNet上: 优化器:SGD 动量:0.9 初始学习率:0.045 学习率衰减:每个epoch衰减率0.94 在JFT上: Optimizer:RMSprop 动量:0.9 初始学习率:0.001 学习率衰减:每3000000个样例后衰减率0.9 正规化设置 权重衰减:Inception V3权重衰减率4e-5,xception为1e-5 Dropout:dropout rate=0.5;JFT因为数据集够大,过拟合发生的可能性较低 辅助损失函数:实验中不适用Inception V3架构中包含的辅助损失分路残差连接的影响 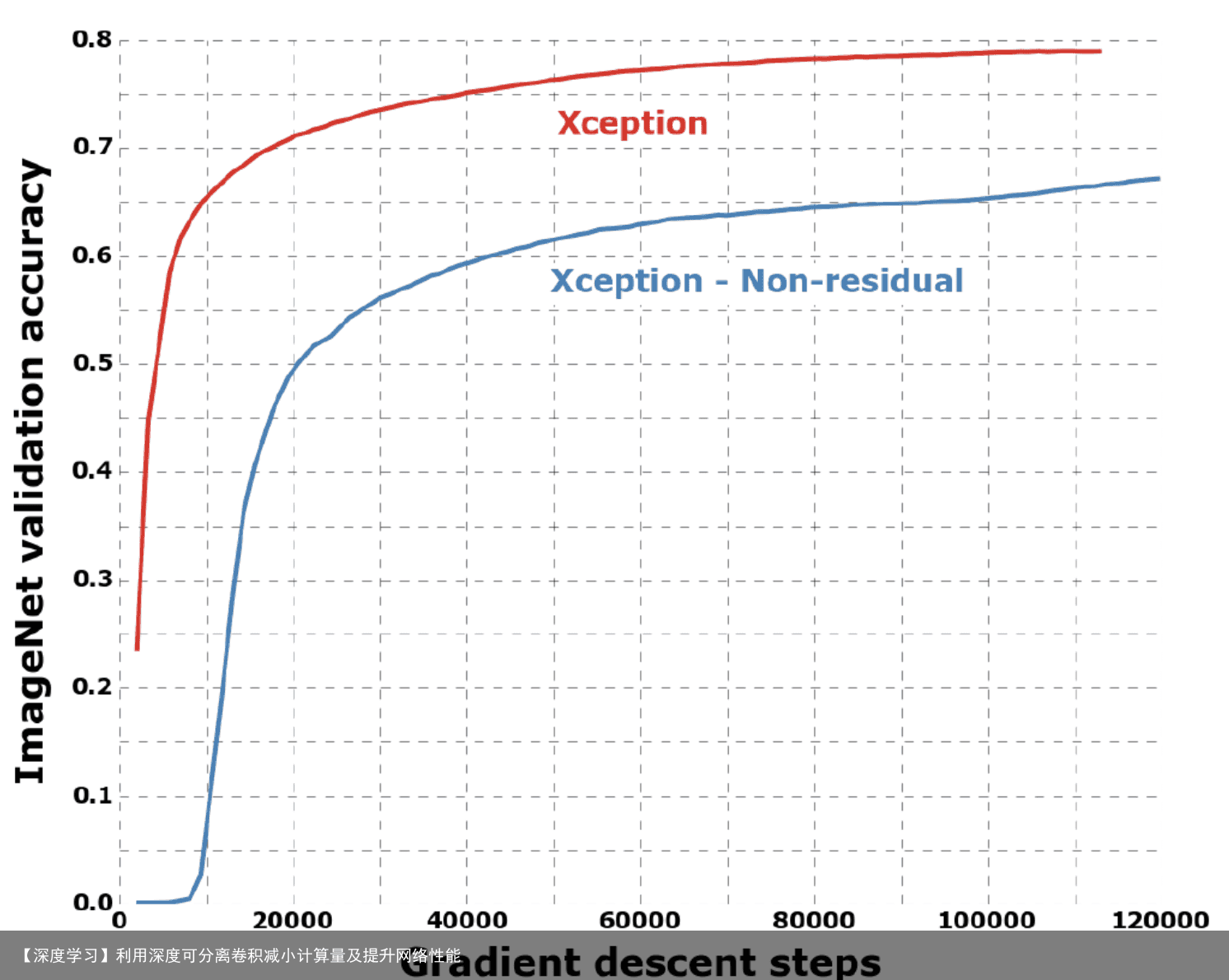 点卷积后跟激活函数的影响
点卷积后跟激活函数的影响 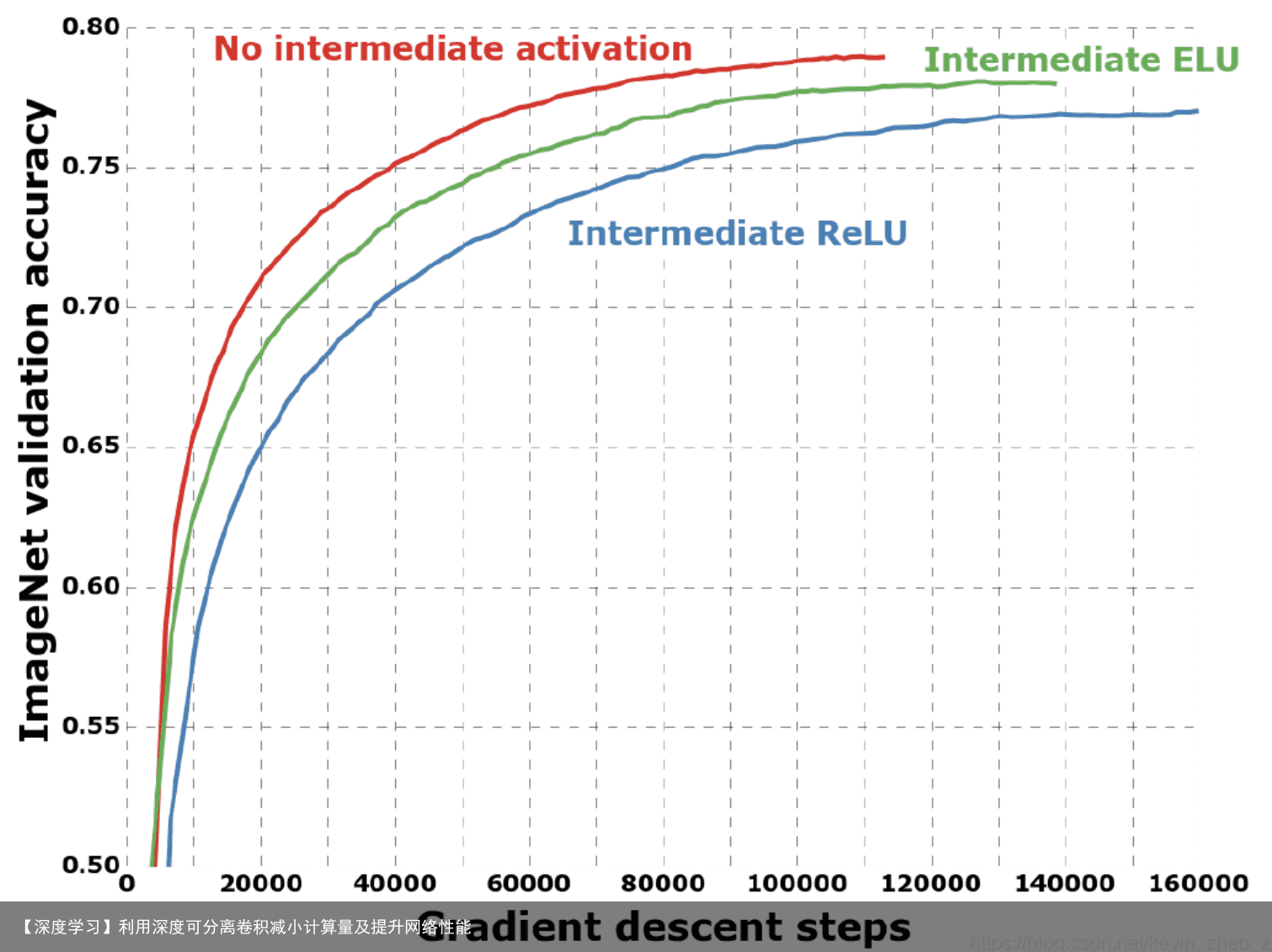
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】利用深度可分离卷积减小计算量及提升网络性能 https://www.yhzz.com.cn/a/12467.html