【深度学习】生动分析半监督学习与负相关学习算法
文章目录 1 半监督学习 1.1 定义 1.2 半监督深度学习 1.3 GAN 1.4 应用 2 深度负相关学习算法 2.1 负相关 2.2 通俗解释 1 半监督学习1.1 定义
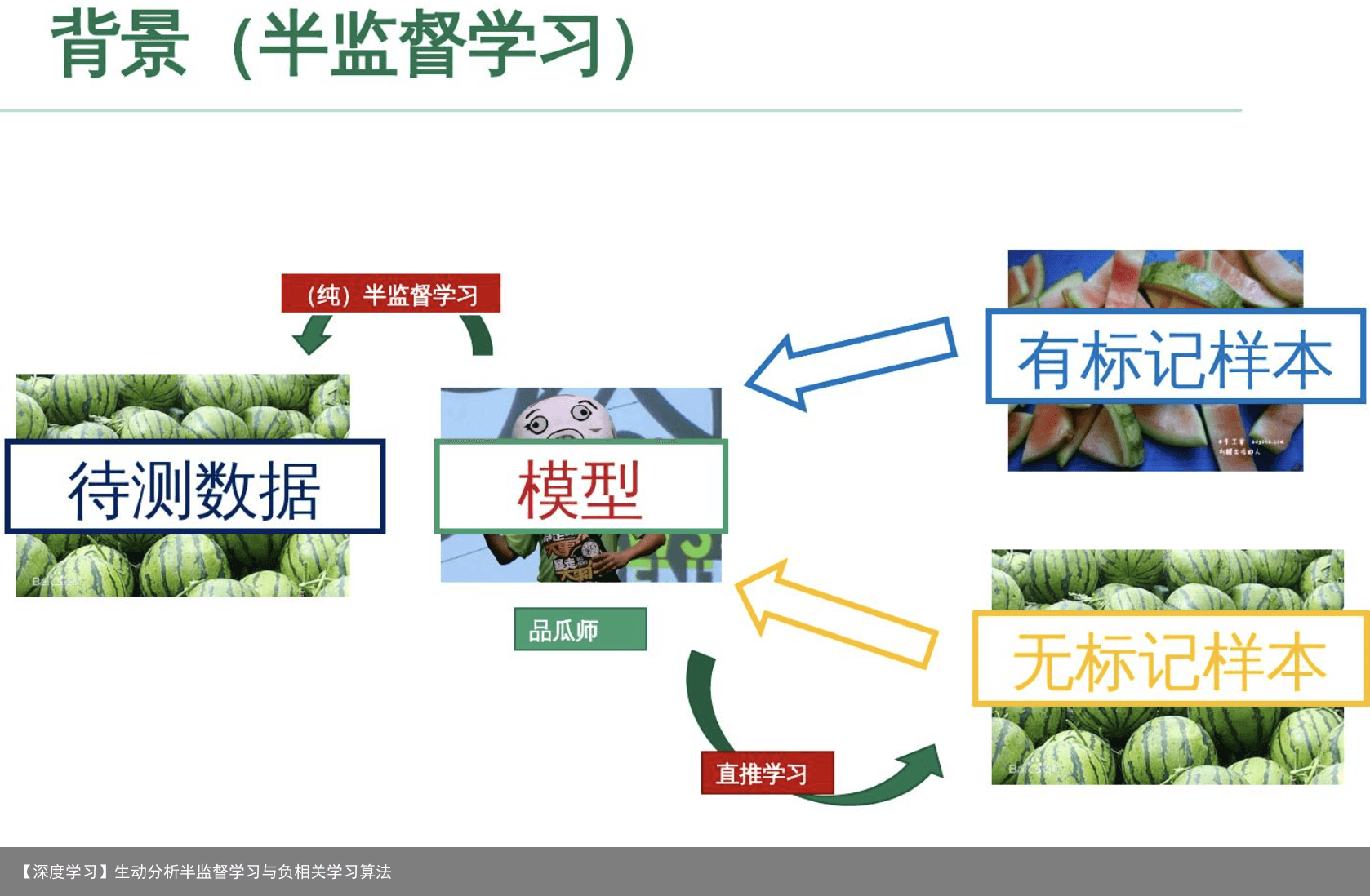
目前知道最科学的定义是来自《Introduction to Semi-supervised Learning》,这里只给出一个自我感觉良好的说法,大概就是,在有标签数据+无标签数据混合成的训练数据中使用的机器学习算法吧。一般假设,无标签数据比有标签数据多,甚至多得多。
虽然训练数据中含有大量无标签数据,但其实在很多半监督学习算法中用的训练数据还有挺多要求的,一般默认的有:无标签数据一般是有标签数据中的某一个类别的(不要不属于的,也不要属于多个类别的);有标签数据的标签应该都是对的;无标签数据一般是类别平衡的(即每一类的样本数差不多);无标签数据的分布应该和有标签的相同或类似 等等。
事实上,某些要求在实际应用中挺强人所难的,所以明明感觉半监督好像很厉害,但应用就是不多啊。但在学术上,这些要求还是可以有滴。
一般,半监督学习算法可分为:self-training(自训练算法)、Graph-based Semi-supervised Learning(基于图的半监督算法)、Semi-supervised supported vector machine(半监督支持向量机,S3VM)。简单介绍如下:
1.简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
2.协同训练(co-training):其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
3.半监督字典学习:其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
4.标签传播算法(Label Propagation Algorithm):是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法…,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
5.半监督支持向量机:监督支持向量机是利用了结构风险最小化来分类的,半监督支持向量机还用上了无标签数据的空间分布信息,即决策超平面应该与无标签数据的分布一致(应该经过无标签数据密度低的地方)(这其实是一种假设,不满足的话这种无标签数据的空间分布信息会误导决策超平面,导致性能比只用有标签数据时还差)
其实,半监督学习的方法大都建立在对数据的某种假设上,只有满足这些假设,半监督算法才能有性能的保证,这也是限制了半监督学习应用的一大障碍。 1、半监督分类: 在分类任务的训练集中同时包含有标签数据和无标签数据,通常无标签数据远远多于有标签数据,半监督分类的任务就是训练一个分类器f,这个分类器的表现比只用有标签数据训练得到的分类器好;
2、半监督聚类(有约束聚类): 是无监督聚类的一种扩展,与传统的无标签训练集不同的是,约束聚类的数据集还包含一些关于聚类的“监督信息”。最常见的约束如must-link约束和cannot-link约束,分别表示两个样本点一定在一个类中或一定在不同的类中,约束聚类的目标就是提升原本无监督聚类的表现;
半监督学习的任务还有很多,比如,半监督回归,维度规约等,在之后的专栏中会又详细的介绍和相关论文导读。
1.2 半监督深度学习
1.无标签数据预训练,有标签数据微调
对于神经网络来说,一个好的初始化可以使得结果更稳定,迭代次数更少。因此如何利用无标签数据让网络有一个好的初始化就成为一个研究点了。
目前我见过的初始化方式有两种:无监督预训练,和伪有监督预训练
无监督预训练:一是用所有数据逐层重构预训练,对网络的每一层,都做重构自编码,得到参数后用有标签数据微调;二是用所有数据训练重构自编码网络,然后把自编码网络的参数,作为初始参数,用有标签数据微调。
伪有监督预训练:通过某种方式/算法(如半监督算法,聚类算法等),给无标签数据附上伪标签信息,先用这些伪标签信息来预训练网络,然后在用有标签数据来微调。
2.利用从网络得到的深度特征来做半监督算法
神经网络不是需要有标签数据吗?我给你造一些有标签数据出来!这就是第二类的思想了,相当于一种间接的 self-training 吧。一般流程是:
先用有标签数据训练网络(此时网络一般过拟合…),从该网络中提取所有数据的特征,以这些特征来用某种分类算法对无标签数据进行分类,挑选你认为分类正确的无标签数据加入到训练集,再训练网络;如此循环。
由于网络得到新的数据(挑选出来分类后的无标签数据)会更新提升,使得后续提出来的特征更好,后面对无标签数据分类就更精确,挑选后加入到训练集中又继续提升网络,感觉想法很好,但总有哪里不对…orz
个人猜测这个想法不能很好地 work 的原因可能是噪声,你挑选加入到训练无标签数据一般都带有标签噪声(就是某些无标签数据被分类错误),这种噪声会误导网络且被网络学习记忆。
1.3 GAN
 这样的有标签的数据集通常用于训练监督模型。监督学习一直是深度学习中大多数研究的中心,但是其训练过程需要大量的含有标签的数据。而现实生活中,给数据打标签是一个非常昂贵而且容易出错的工作。
这样的有标签的数据集通常用于训练监督模型。监督学习一直是深度学习中大多数研究的中心,但是其训练过程需要大量的含有标签的数据。而现实生活中,给数据打标签是一个非常昂贵而且容易出错的工作。
考虑到这一点,为了利用打好标签的一部分数据以及未曾拥有标签的大部分数据,研究人员提出了半监督学习。半监督学习解决了有标签数据较少时,模型训练效果较差的问题。 它通过从没有标签的数据中提取有用的信息来弥补标签损失带来的不足,进一步提高了模型的整体性能。
半监督的分类器需要一小部分标记数据和大量未标记数据(来自同一域)。其目标是结合这些数据源来训练模型,比如深度卷积神经网络(DCNN),以学习这些数据中的类别信息。
在此领域中,我们学者提出一个GAN模型,该模型使用一个非常小的标签训练集对街景门牌号进行分类。实际上,该模型使用了大约1.3%的原始SVHN培训标签,即1000个(一千个)标签示例。我们使用了OpenAI的《改进GAN训练技术》一书中描述的一些技术。
如果您不熟悉图像生成GAN,请参阅《生成对抗网络简介》。本文引用了该文章中描述的一些内容。 在构建用于生成图像的GAN时,我们同时训练了生成器和决策器。在训练之后,我们可以放弃决策器,因为我们只用它来训练生成器。
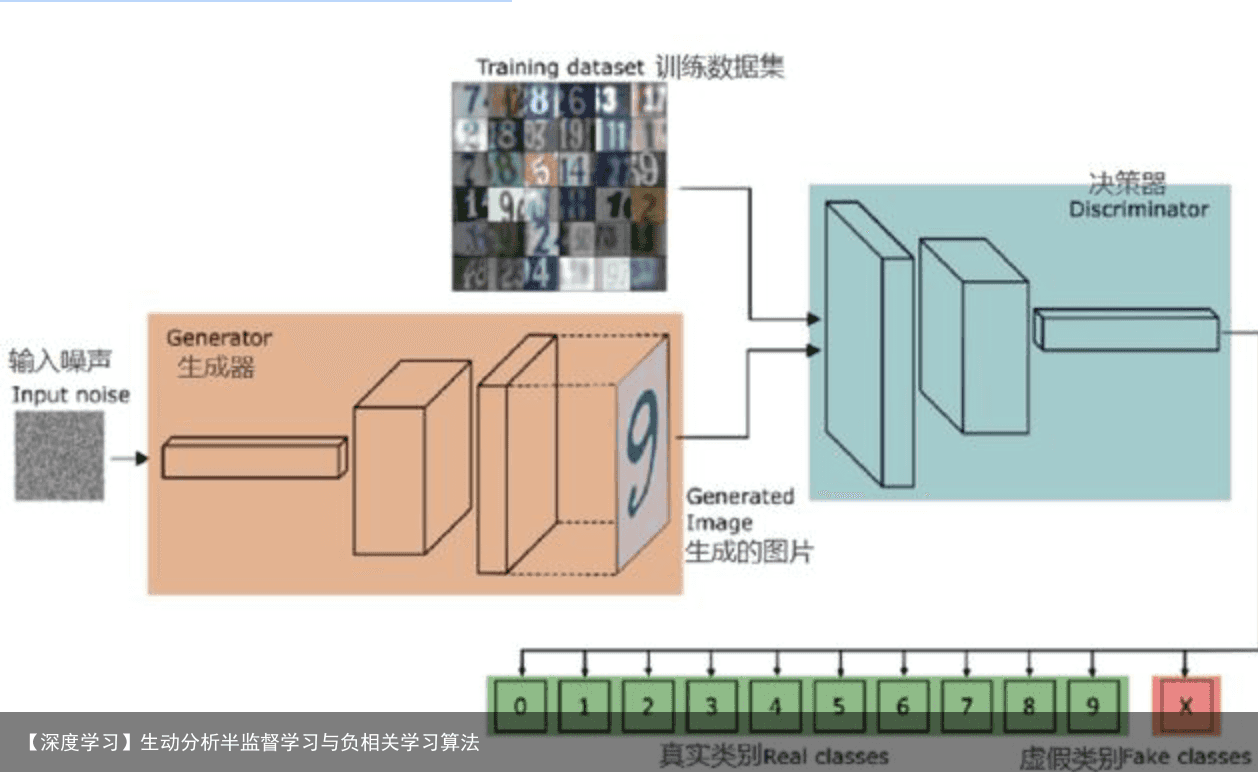
核心理念 在半监督学习中运用GAN的逻辑如下。
无标记样本没有类别信息,无法训练分类器; 引入GAN后,其中生成器(Generator)可以从随机信号生成伪样本; 相比之下,原有的无标记样本拥有了人造类别:真。可以和伪样本一起训练分类器。
举个通俗的例子:就算没人教认字,多练练分辨“是不是字”也对认字有好处。有粗糙的反馈,也比没有反馈强。
训练集中包含有标签样本和无标签样本。 生成器从随机噪声生成伪样本。 分类器接受样本,对于类分类问题,输出维估计,再经过softmax函数得到概率:其前维对应原有个类,最后一维对应“伪样本”类。 的最大值位置对应为估计标签。
MNIST 10分类问题,图像为28*28灰度。
生成器是一个3层线性网络:
 分类器是一个6层线性网络:
分类器是一个6层线性网络: 
1.4 应用
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是: G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。 D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。 在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。 最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。 这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
2 深度负相关学习算法2.1 负相关
在回归与相关分析中,因变量值随自变量值的增大(减小)而减小(增大),在这种情况下,因变量和自变量的相关系数为负值,即负相关。 1)如何训练一组有足够多样性(Diversity)的深度回归器。好的集成学习系统往往有着很强的多样性。2)如何有效地训练深度集成学习系统。传统的集成学习一般会独立的训练多个分类或回归器。除了低效率的缺陷以外,由于不同的回归器彼此之间没有限制,产生的回归器之间会有很强的相关性,进而降低了模型整体的多样性,从而导致模型抑制过拟合的能力受限。 深度负相关学习我们首次提出将负相关学习的思想应用在深度学习模型中。由于深度学习模型的参数众多, 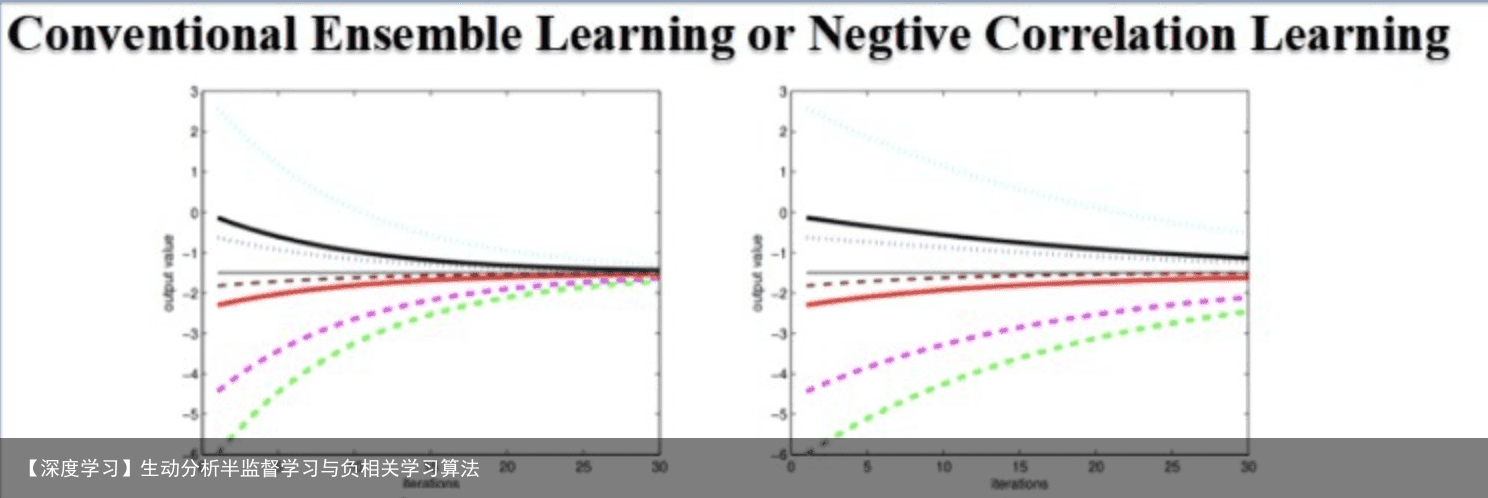 同时训练多个深度学习模型往往需要很多工程技巧并且效率低下。因此,我们要解决的关键问题是如何在不增加模型参数规模的情况下得到深度负相关学习模型。我们想要达到两个目的:1)训练单个网络得到多个有足够多样性的输出。2)不增加网络的参数规模。我们提出的方案是对深度卷积模型最后一层的特征图进行分组,然后不同的输出连接不同的分组,这相当于同时训练了多个弱回归器,最终得到一个强的回归器。我们通过使用已有的组卷积(Group Convolution)实现提出的方案。提出的网络模型如图4所示。同时训练多个回归器并加入约束来减弱回归器之间的相关性。我们的方法有效的增强了模型整体的多样性,从而提高了模型抑制过拟合的能力。
同时训练多个深度学习模型往往需要很多工程技巧并且效率低下。因此,我们要解决的关键问题是如何在不增加模型参数规模的情况下得到深度负相关学习模型。我们想要达到两个目的:1)训练单个网络得到多个有足够多样性的输出。2)不增加网络的参数规模。我们提出的方案是对深度卷积模型最后一层的特征图进行分组,然后不同的输出连接不同的分组,这相当于同时训练了多个弱回归器,最终得到一个强的回归器。我们通过使用已有的组卷积(Group Convolution)实现提出的方案。提出的网络模型如图4所示。同时训练多个回归器并加入约束来减弱回归器之间的相关性。我们的方法有效的增强了模型整体的多样性,从而提高了模型抑制过拟合的能力。
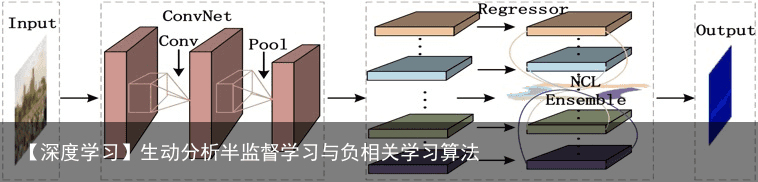
2.2 通俗解释
在机器学习领域,我们把具备从经验知识中学习能力的系统或者模型叫做学习器。一般来说训练出一个学习能力较弱的模型比训练出一个学习能力较强的模型所要耗费的代价小得多。集成学习是一类特殊的机器学习方法,其思想是不直接训练一个强学习器,而是通过组合一批弱学习器来得到一个学习能力强的集成学习器。集成学习算法性能好坏主要取决于两个因素:基学习器自身的性能好坏以及基学习器之间的差异性。目前常用的集成学习算法包括Bagging、Boosting等,在提升每个基学习器性能的同时,其实也是在以一种隐性的方式维持了基学习器之间的差异性,从而使得最终的集成学习器的性能达到最佳。负相关学习(Negative correlation learning,NCL)是一种常用于神经网络集成的集成学习算法,它是把基学习器之间的差异性作为一个显性的度量标准引入到神经网络的损失函数中去,进而影响神经网络的训练。通过调整影响因子可以权衡基神经网络之间的性能与多样性,以谋求获得一个性能最优的集成神经网络模型。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】生动分析半监督学习与负相关学习算法 https://www.yhzz.com.cn/a/12465.html