【深度学习】谷歌大脑EfficientNet的工作原理解析
文章目录 1 知识点准备 1.1 卷积后通道数目是怎么变多的 1.2 EfficientNet 2 结构 2.1 方式 2.2 MBConv卷积块 2.3 模型的规模和训练方式 3 对比 4 MBConv结构 1 知识点准备1.1 卷积后通道数目是怎么变多的
为什么out_channel会大于in_channel 相信初学深度学习的小伙伴会遇到和我一样的问题,在卷积时,我们明明输入通道为 3 的图片(RGB),为什么输出通道会达到6甚至跟多呢? 下面就解释一下
首先我们假设拥有一张 3x3x3(C,H,W)的图片(方便我们处理),卷积核为2×2.如下图所示:
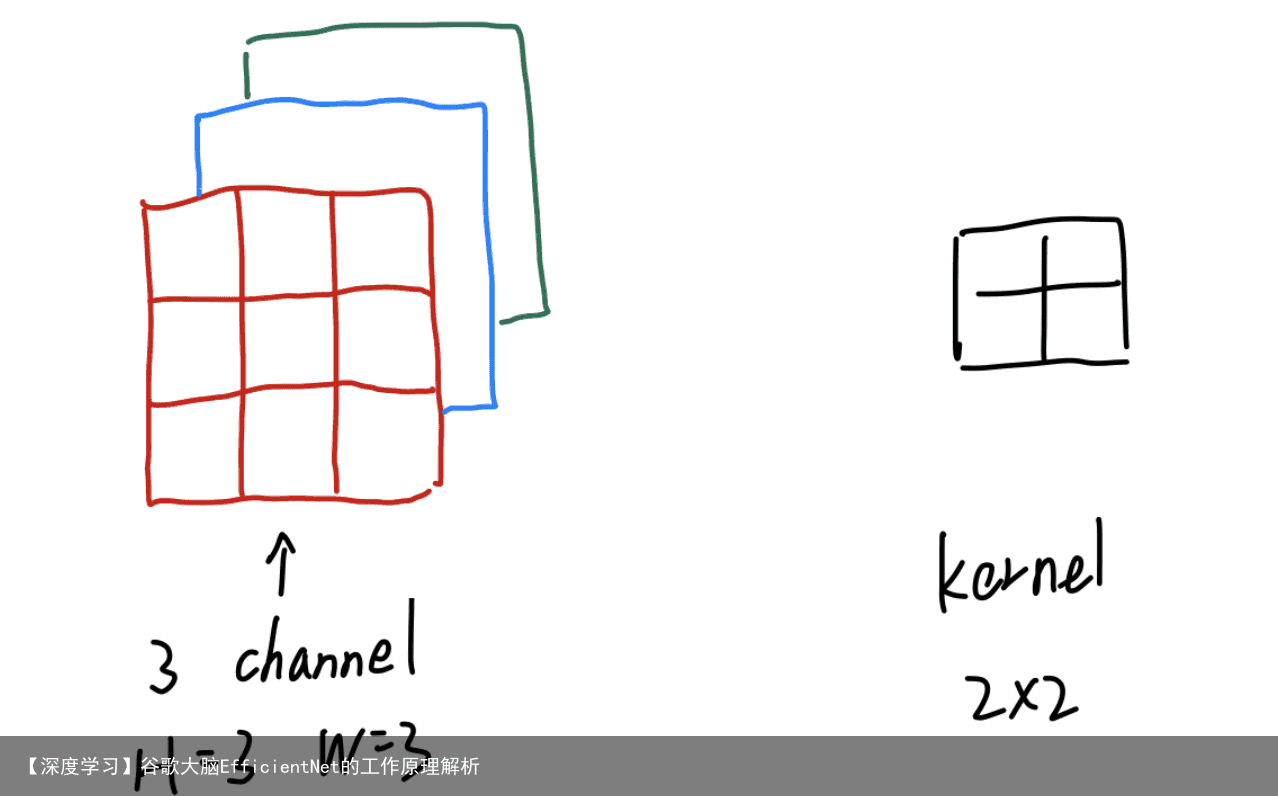
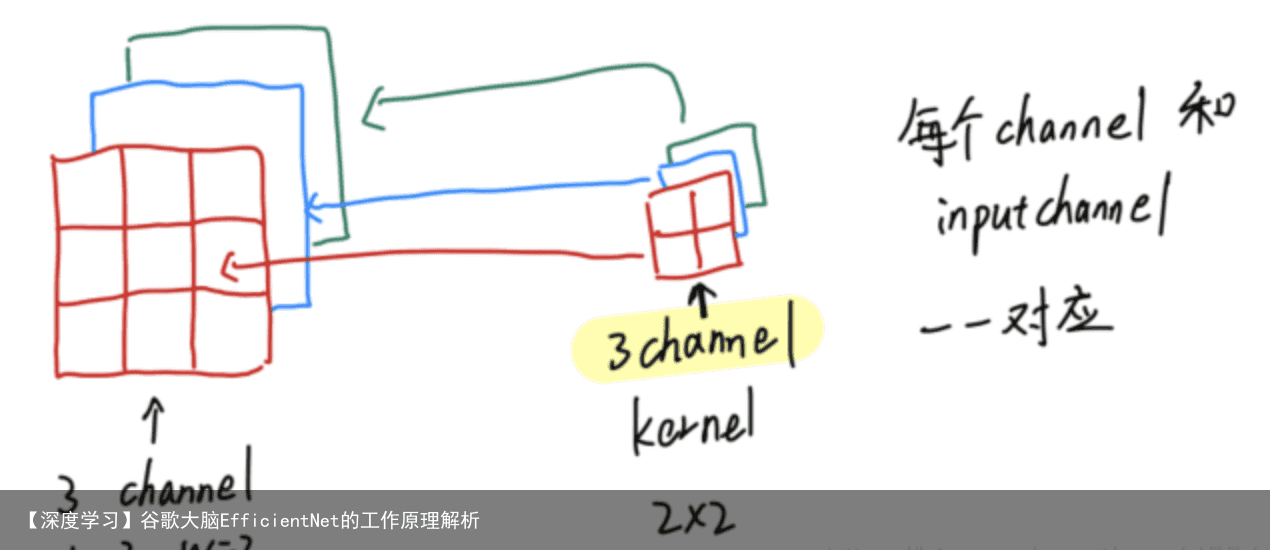
但是,一般我们设的kernel size只有长和宽,有一点容易被忽略,就是它也有channle(意想不到~) 所以,真实的kernel应该是下图的样子 每个2×2的卷积来扫描对应的通道,3个2×2组成一个kernel,及kernel_size可以理解为3x2x2
因此卷积后就如图所示: 注意行数及对应的out_channels的数目,列数对应in_channels的数目 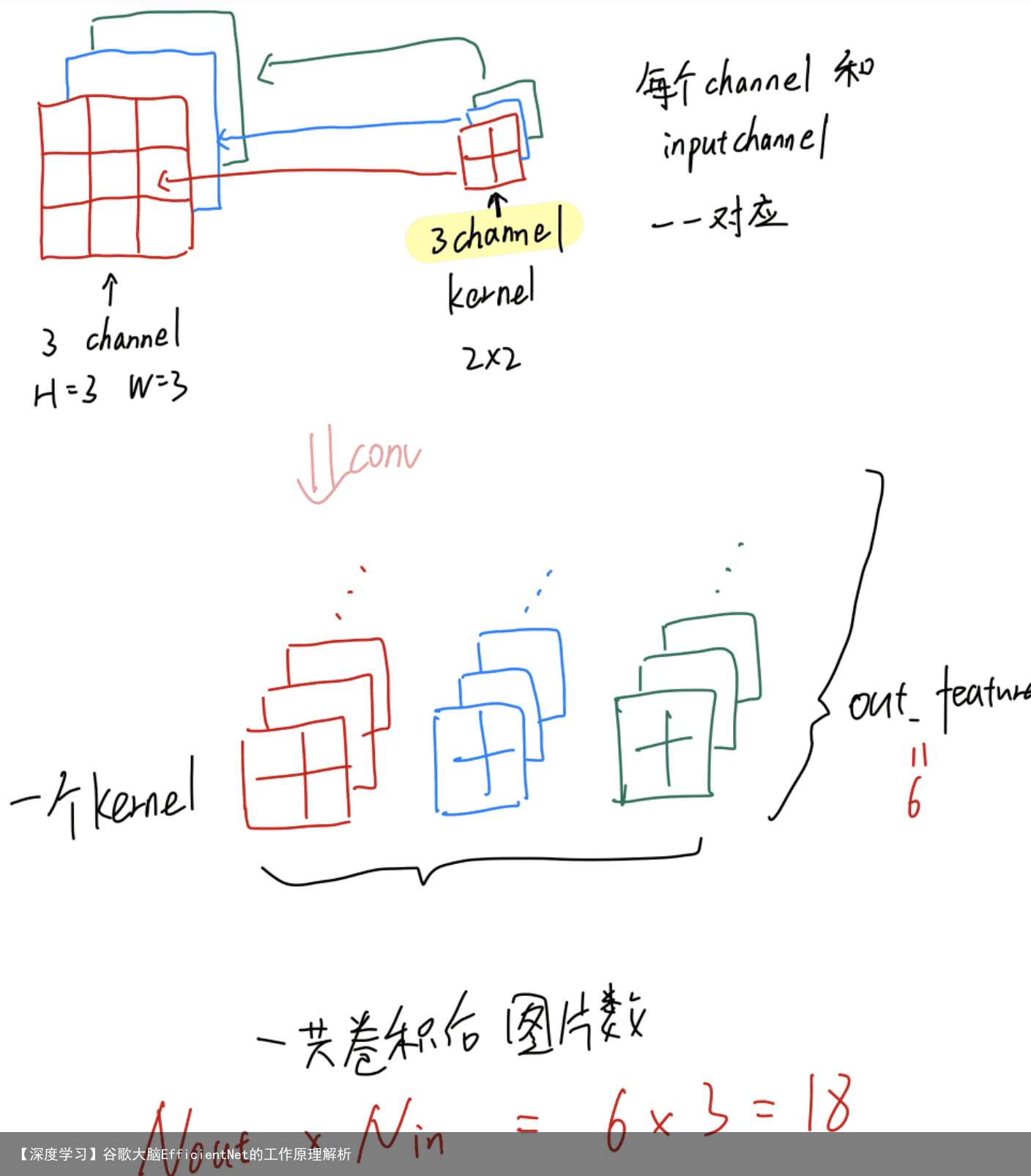
所以我们的Out_channels要能反映图片的多种特征,所以out_channel 大于 in_channel了。但其实可以了解到 Out_channel 和 In_channel 概念不是很相同
1.2 EfficientNet
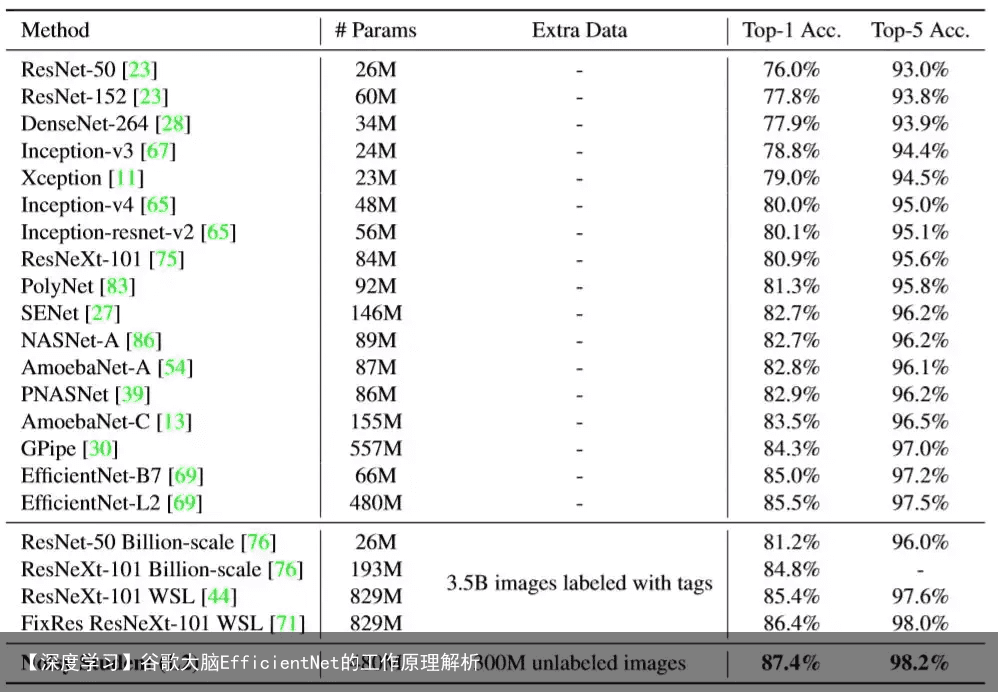
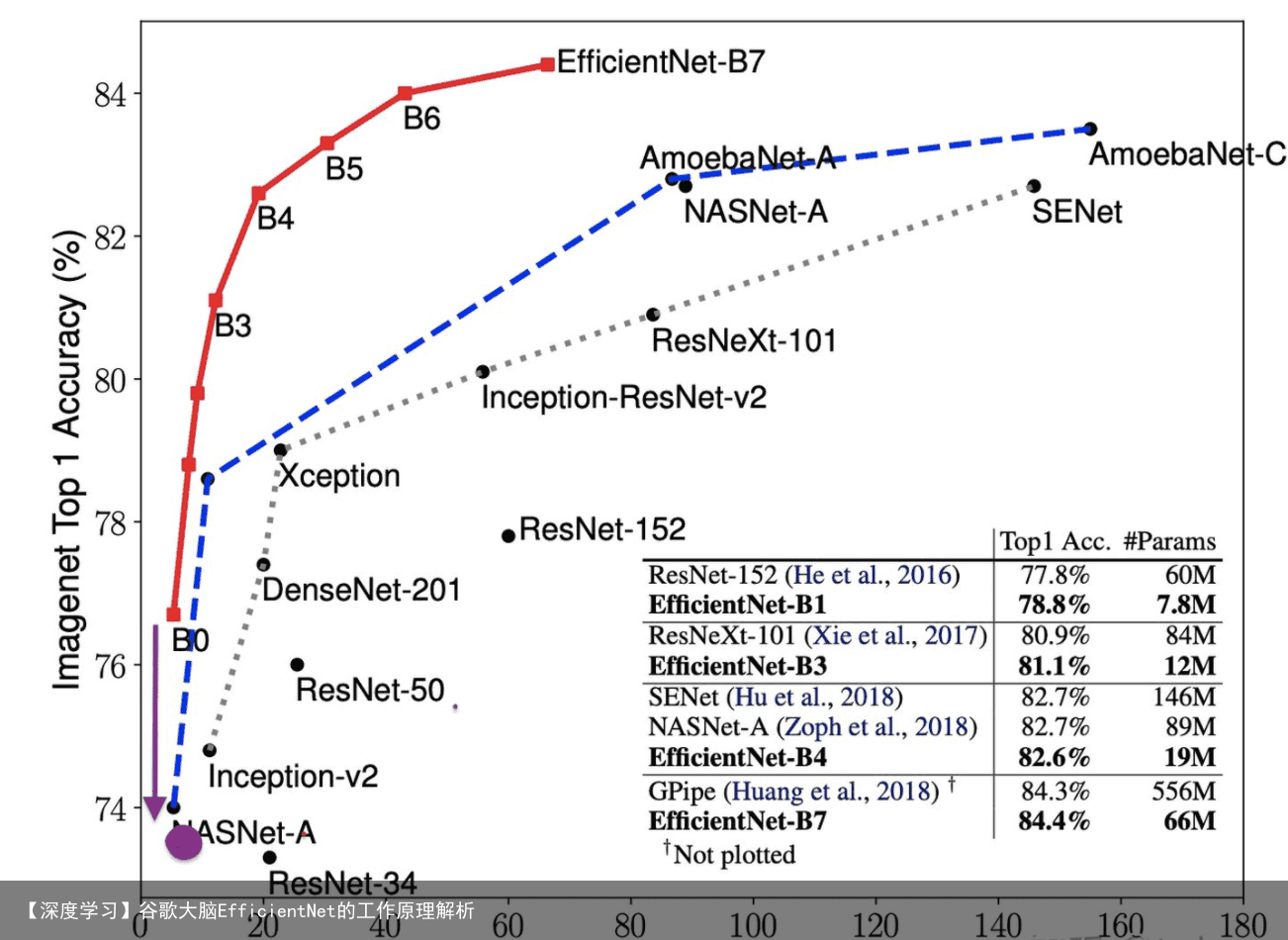
EfficientNet模型是Google公司通过机器搜索得来的模型。该模型是一个快速高精度模型。它使用了深度(depth)、宽度(width)、输入图片分辨率(resolution)共同调节技术。 谷歌使用这种技术开发了一系列版本。目前已经从EfficientNet-B0到EfficientNet-B8再加上EfficientNet-L2和Noisy Student共11个系列的版本。其中性能最好的是Noisy Student版本。以下是图片分类模型在ImageNet数据集上的精度对比结果。
2.1 方式
EfficientNet系列模型的主要结构要从该模型的构建方法说起。该模型的构建方法主要包括以下2个步骤: (1)使用强化学习算法实现的MnasNet模型生成基线模型EfficientNet-B0。 (2)采用复合缩放的方法,在预先设定的内存和计算量大小的限制条件下,对EfficientNet-B0模型的深度、宽度(特征图的通道数)、图片大小这三个维度都同时进行缩放,这三个维度的缩放比例由网格搜索得到。最终输出了EfficientNet模型。
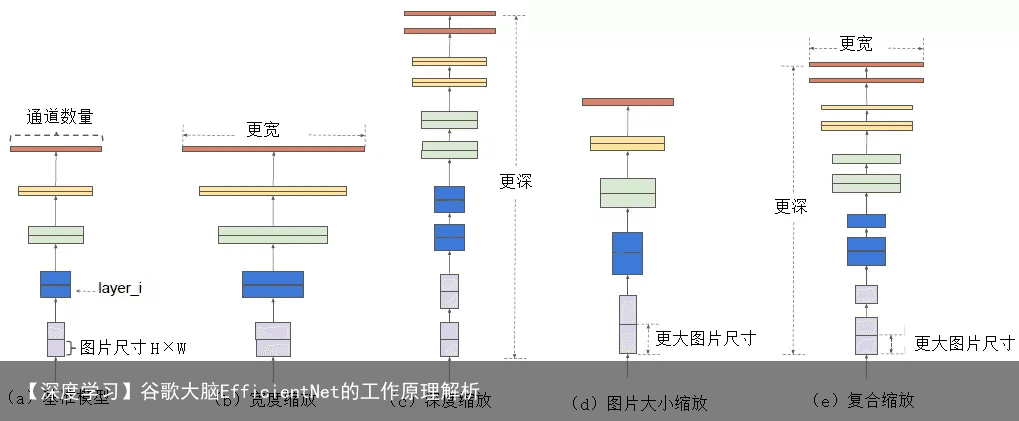

2.2 MBConv卷积块
EfficientNet模型的内部是通过多个MBConv卷积块实现的,每个MBConv卷积块的具体结构如下:
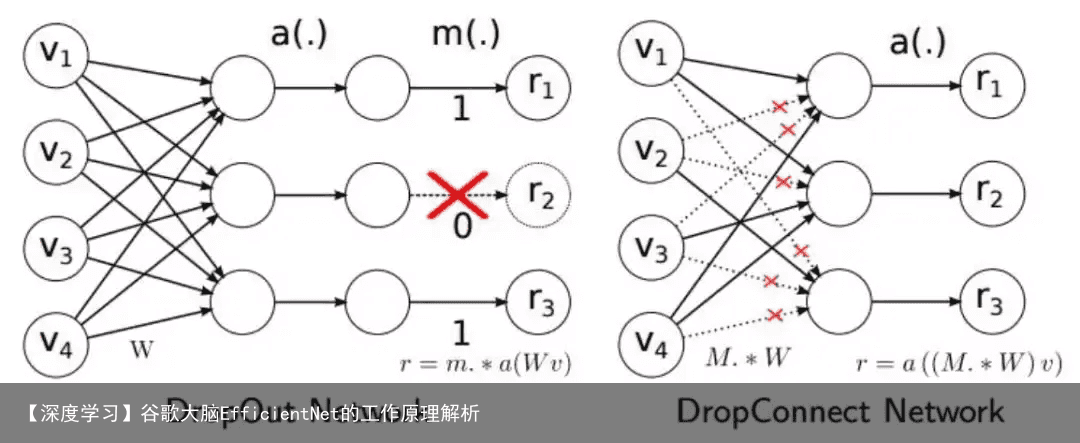
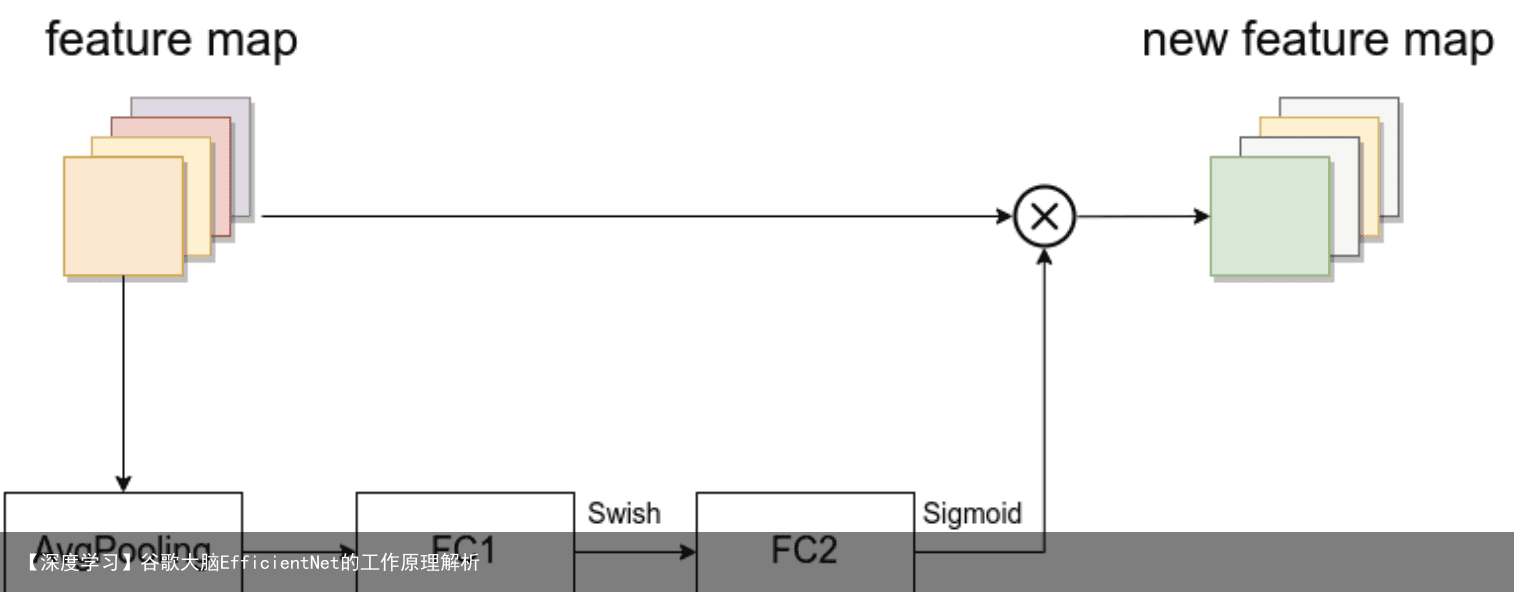
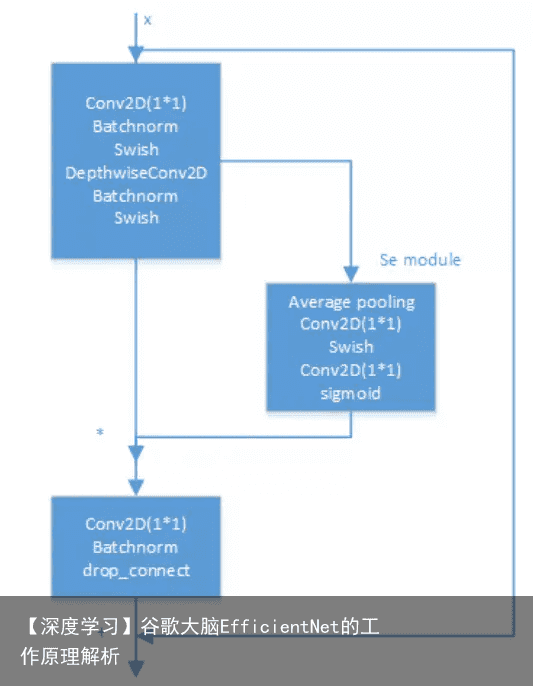 其中将ReLU激活函数缓存了Swish激活函数。MBConv卷积块也使用了类似残差链接的结构,不同的是在短连接部分使用了SE层。另外使用了drop_connect方法来代替传统的drop方法。注意:在SE层中没有使用BN操作,而且其中的sigmoid激活函数也没有被Swish替换。在其它层中,BN是放在激活函数与卷积层之间的. DropConnect与Dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机的丢弃,而是对隐层节点的输入进行随机的丢弃。如下图所示:
其中将ReLU激活函数缓存了Swish激活函数。MBConv卷积块也使用了类似残差链接的结构,不同的是在短连接部分使用了SE层。另外使用了drop_connect方法来代替传统的drop方法。注意:在SE层中没有使用BN操作,而且其中的sigmoid激活函数也没有被Swish替换。在其它层中,BN是放在激活函数与卷积层之间的. DropConnect与Dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机的丢弃,而是对隐层节点的输入进行随机的丢弃。如下图所示:
2.3 模型的规模和训练方式

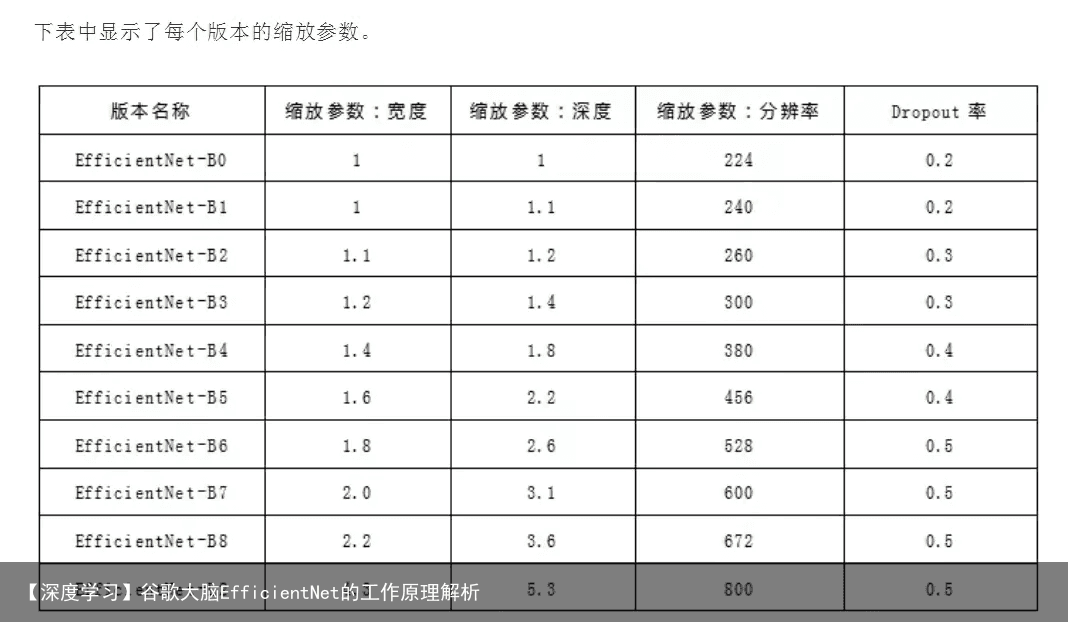

 这篇文章最大的 novelty,在我看来不在于小模型上的 efficiency,而是告诉大家 MBConv 是可以被 scale 到 non-mobile settings 的。MBConv 自被提出以来就一直局限在 light-weight model,而在拼点的 task 上,大家都还停留在之前的 ResBlock + SE 那一套。 EfficientNet 通过实验告诉了大家 MBConv 也可以做 large setting(印象中应该是第一个?),并且还十分有效。
这篇文章最大的 novelty,在我看来不在于小模型上的 efficiency,而是告诉大家 MBConv 是可以被 scale 到 non-mobile settings 的。MBConv 自被提出以来就一直局限在 light-weight model,而在拼点的 task 上,大家都还停留在之前的 ResBlock + SE 那一套。 EfficientNet 通过实验告诉了大家 MBConv 也可以做 large setting(印象中应该是第一个?),并且还十分有效。
MBConv其实就是MobileNetV3网络中的InvertedResidualBlock,但也有些许区别。一个是采用的激活函数不一样(EfficientNet的MBConv中使用的都是Swish激活函数),另一个是在每个MBConv中都加入了SE(Squeeze-and-Excitation)模块。下图是我自己绘制的MBConv结构。 

免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】谷歌大脑EfficientNet的工作原理解析 https://www.yhzz.com.cn/a/12449.html