【深度学习】图像特征提取与通道数问题(基于U型网络)
1 医学图像特点 2 卷积核与图像特征提取 2.1 卷积 2.2 图像处理 2.3 边缘检测卷积核 2.4 图像锐化卷积核 2.5 高斯滤波 3 关于图像三通道和单通道的解释 4 pytorch 修改预训练模型(全连接层、单个卷积层、多个卷积层) 1 医学图像特点1.图像语义较为简单、结构较为固定。我们做脑的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定成像,而不是全身的。由于本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要(UNet的skip connection和U型结构就派上了用场)。举两个例子直观感受下。 2.数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。 原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内,非常轻量。个人尝试过使用Deeplab v3+和DRN等自然图像语义分割的SOTA网络在自己的项目上,发现效果和UNet差不多,但是参数量会大很多。 3.多模态。相比自然影像,医疗影像比较有趣和不同的一点是,医疗影像是具有多种模态的。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模态的数据。 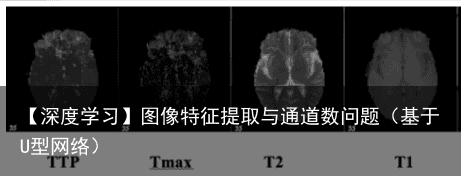 这就需要我们更好的设计网络去提取不同模态的特征feature。
这就需要我们更好的设计网络去提取不同模态的特征feature。
2.1 卷积
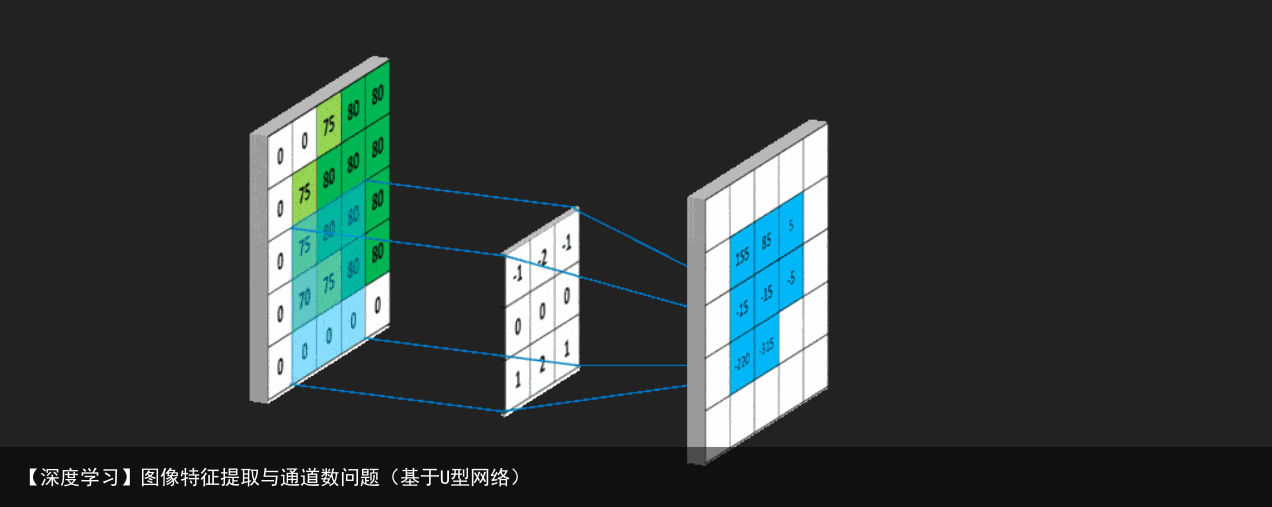 用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。对图像上的每个点都这样处理。由于大多数模板都是对称的,所以模板不旋转。卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。 把一个点的像素值用它周围的点的像素值的加权平均代替。 卷积是一种线性运算,图像处理中常见的mask运算都是卷积,广泛应用于图像滤波。 卷积关系最重要的一种情况,就是在信号与线性系统或数字信号处理中的卷积定理。利用该定理,可以将时间域或空间域中的卷积运算等价为频率域的相乘运算,从而利用FFT等快速算法,实现有效的计算,节省运算代价。
用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。对图像上的每个点都这样处理。由于大多数模板都是对称的,所以模板不旋转。卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。 把一个点的像素值用它周围的点的像素值的加权平均代替。 卷积是一种线性运算,图像处理中常见的mask运算都是卷积,广泛应用于图像滤波。 卷积关系最重要的一种情况,就是在信号与线性系统或数字信号处理中的卷积定理。利用该定理,可以将时间域或空间域中的卷积运算等价为频率域的相乘运算,从而利用FFT等快速算法,实现有效的计算,节省运算代价。
2.2 图像处理
对图像和滤波矩阵进行逐个元素相乘再求和的操作就相当于将一个二维的函数移动到另一个二维函数的所有位置,这个操作就叫卷积或者相关。卷积和相关的差别是,卷积需要先对滤波矩阵进行180的翻转,但如果矩阵是对称的,那么两者就没有什么差别了。 图像卷积操作的本质是矩阵卷积。某些特殊的卷积核会使图像产生特殊的效果:
2.3 边缘检测卷积核
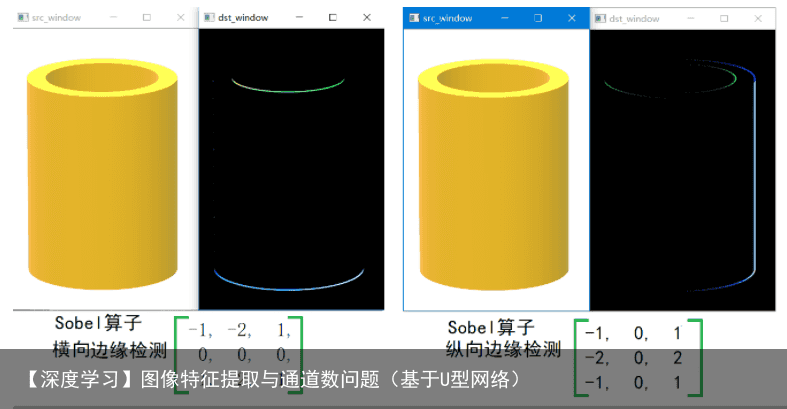
2.4 图像锐化卷积核
2.5 高斯滤波
#include <iostream> #include <opencv2\opencv.hpp> using namespace cv; using namespace std; int main(int argc, char **argv) { Mat src = imread(“C:\\Users\\Tim\\Desktop\\Image\\notbeautify1.png”); //Mat src = imread(“C:\\Users\\Tim\\Desktop\\Image\\AI.png”); Mat dst; if (src.empty()) { cout << “load image filed…” << endl; return -1; } namedWindow(“src_window”, CV_WINDOW_AUTOSIZE); imshow(“src_window”, src); //中值滤波去掉椒盐噪声 //medianBlur(src, dst, 3); //双边滤波 bilateralFilter(src, dst, 15, 100, 3); namedWindow(“medianBlur_dst”, CV_WINDOW_AUTOSIZE); imshow(“medianBlur_dst”, dst); Mat gblur; GaussianBlur(src, gblur, Size(15, 15), 3, 3); namedWindow(“HelloWorld”,CV_WINDOW_AUTOSIZE); namedWindow(“bglur_dst”, CV_WINDOW_AUTOSIZE); imshow(“bglur_dst”, gblur); //通过掩模提升对比度 Mat retImg; Mat kernal = (Mat_<int>(3, 3) << 0, -1, 0, -1, 5, -1, 0, -1, 0); filter2D(dst, retImg, dst.depth(), kernal, Point(-1, -1), 0); namedWindow(“retImg”, CV_WINDOW_AUTOSIZE); imshow(“retImg”, retImg); waitKey(0); return 0; } }
(一):单通道图,
俗称灰度图,每个像素点只能有有一个值表示颜色,它的像素值在0到255之间,0是黑色,255是白色,中间值是一些不同等级的灰色。(也有3通道的灰度图,3通道灰度图只有一个通道有值,其他两个通道的值都是零)。
如果是单通道图像,即灰度图,每个像素值用一个八位的二进制即可,如下图: 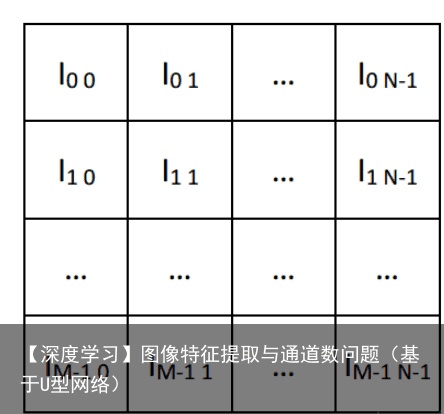
(二):三通道图,每个像素点都有3个值表示 ,所以就是3通道。也有4通道的图。例如RGB图片即为三通道图片,RGB色彩模式是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。总之,每一个点由三个值表示。 如果是多通道图像,比如 RGB 图像,则每个像素用三个字节表示。在 OpenCV 中, RGB 图像的通道顺序为 BGR ,存储如下图 所示: 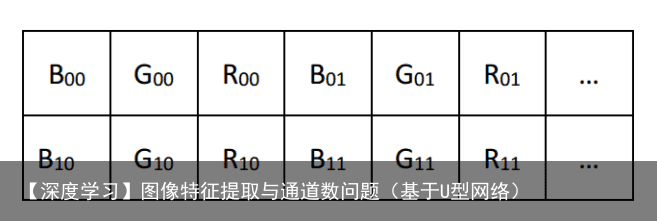
Res-UNet 和Dense U-Net
Res-UNet和Dense-UNet分别受到残差连接和密集连接的启发,将UNet的每一个子模块分别替换为具有残差连接和密集连接的形式。中将Res-UNet用于视网膜图像的分割,其结构如下图所示,其中灰色实线表示各个模块中添加的残差连接。 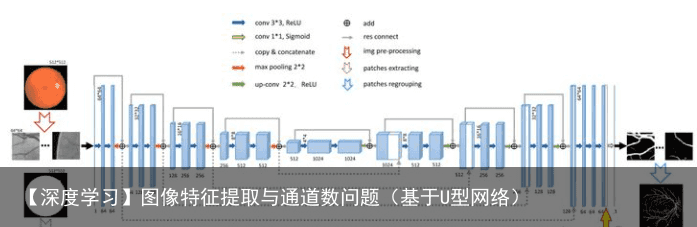 密集连接即将子模块中某一层的输出分别作为后续若干层的输入的一部分,某一层的输入则来自前面若干层的输出的组合。下图中的密集连接的一个例子。该文章中将U-Net的各个子模块替换为这样的密集连接模块,提出Fully Dense UNet 用于去除图像中的伪影。
密集连接即将子模块中某一层的输出分别作为后续若干层的输入的一部分,某一层的输入则来自前面若干层的输出的组合。下图中的密集连接的一个例子。该文章中将U-Net的各个子模块替换为这样的密集连接模块,提出Fully Dense UNet 用于去除图像中的伪影。
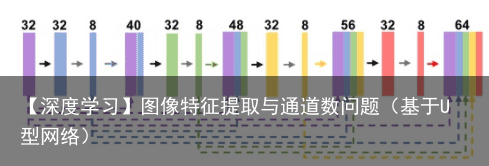 UNet是一个经典的网络设计方式,在图像分割任务中具有大量的应用。也有许多新的方法在此基础上进行改进,融合更加新的网络设计理念,但目前几乎没有人对这些改进版本做过比较综合的比较。由于同一个网络结构可能在不同的数据集上表现出不一样的性能,在具体的任务场景中还是要结合数据集来选择合适的网络。希望本文对做图像分割的同学有所启发。
UNet是一个经典的网络设计方式,在图像分割任务中具有大量的应用。也有许多新的方法在此基础上进行改进,融合更加新的网络设计理念,但目前几乎没有人对这些改进版本做过比较综合的比较。由于同一个网络结构可能在不同的数据集上表现出不一样的性能,在具体的任务场景中还是要结合数据集来选择合适的网络。希望本文对做图像分割的同学有所启发。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】图像特征提取与通道数问题(基于U型网络) https://www.yhzz.com.cn/a/12437.html