【深度学习】DL下的3D图像和Low-level Vision问题解析
文章目录 1 概述 2 low-level vision 2.1 【注意力机制、超分】Learning Texture Transformer Network for Image Super-Resolution 2.2 【解耦表征、多模图像转换、超分、修复】Nested Scale-Editing for Conditional Image Synthesis 3 Low-level vision task 低级视觉任务:image2image, video2video 等等。 4 High-level vision task 高级视觉任务:检测,识别,分割 等等。 5 3D图像训练 1 概述Low-level feature:通常是指图像中的一些小的细节信息,例如边缘(edge),角(corner),颜色(color),像素(pixeles),梯度(gradients)等,这些信息可以通过滤波器、SIFT或HOG获取。  high-level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具 有更丰富的语义信息 high-level feature常被人称为是高级的语义信息,他的感觉就像通过环境信息纹理信息, 等-些 信息综合得出来的一个信息,然后分类or检测的时候在使用它去进行判断。
high-level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具 有更丰富的语义信息 high-level feature常被人称为是高级的语义信息,他的感觉就像通过环境信息纹理信息, 等-些 信息综合得出来的一个信息,然后分类or检测的时候在使用它去进行判断。
low-level feature它是怎么来的? 它是原图通过很浅的几层卷积得到的输出,这里提一个感受野 (不知道感受野看第三点),浅层的特 征他的感受野较小,例如:他只从5×5的区域提取一个边缘信息。 high-level feature他的感受野大, 他可以从100×100的区域总结一个语义信息。
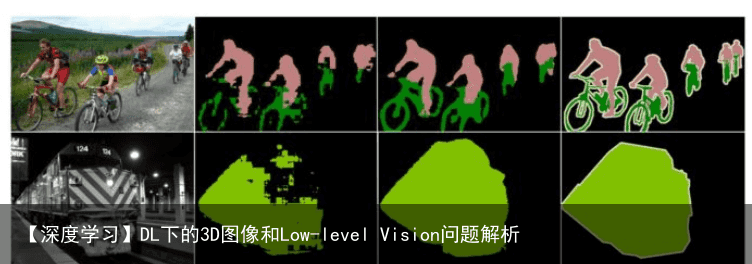 上图是语义分割一 个操作来分析有没有low-level所带来的影响,做法是一个网络label 就是右边的 GT,当只使用high-level的特征做预测的时候 他可以得到大体的目标的状态,一个很宏观的角度。当 引入low-level的特征就会弥补很多细节信息。 实low-level high-level实也要分任务的,不同任务理解也不太一样。
上图是语义分割一 个操作来分析有没有low-level所带来的影响,做法是一个网络label 就是右边的 GT,当只使用high-level的特征做预测的时候 他可以得到大体的目标的状态,一个很宏观的角度。当 引入low-level的特征就会弥补很多细节信息。 实low-level high-level实也要分任务的,不同任务理解也不太一样。
除了High-level Vision任务外,很少有研究将transformer应用于low-level vision领域,例如图像超分辨率,图像生成等。与以标签或框为输出的分类,分割和检测相比,low-level vision任务 通常将图像作为输出(例如,高分辨率图像或去噪图像),这更具有挑战性。
Parmar等迈出第一步,推广transformer模型来制定图像转换和生成任务,并提出Image transformer。 Image transformer由两部分组成:用于提取图像表示的编码器和用于生成像素的解码器。对于值为0 – 255的每个像素,将学习256×d维embeddings,以将每个值编码为d维向量,将其作为编码器的输入。编码器和解码器的架构与《Advances in neural information processing systems》中的相同。解码器中每一层的详细结构如图所示。 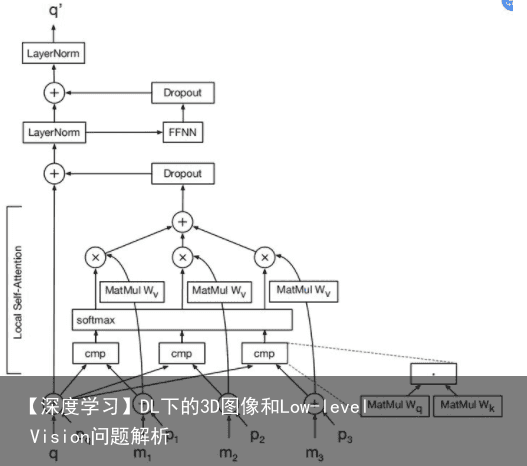
low-level vision low-level version: which concerns the extraction of image properties from the retinal image. 低级视觉:主要关注的是从视网膜图像中提取图像的特性。 middle-level vision middle-level vision: which concerns the integration of image properties into perceptual organizations. 中级视觉:主要关注是将图像特性整合到知觉组织中。 high-level vision high-level vision: which concerns the everyday functionality of perceptual organizations. 高级视觉:主要关注的是知觉组织的日常功能。 与其问low-level vision的热门方向是什么,不如问low-level领域有哪些亟待解决的难题。DL大热时随便一个low-level问题套上CNN都能远超之前的效果,但是现在能简单用CNN灌水的领域已经不多了 lol,随便聊一聊可能会再热的方向
其实评测标准一直是一个很头疼的问题,一直以来大家都默认PSNR,SSIM这些为主要的评测手段,但是近几年来越来越多的paper发现了,PSNR/SSIM与视觉效果不再保持一致。比较著名的比如说超分辨率(Super Resolution)领域,从SRGAN [1] 出来以后大家都发现清晰而错误的细节相比于模糊的细节PSNR结果更差,但是超分辨率恰恰是一个ill-posed的问题,没有所谓的正确的结果的,清晰的细节才是目标,举一个明显的例子,今年ECCV的一个challenge上放的一张图  很明显的看到最右边一张图才是人眼感受最好的,结果PSNR/SSIM结果反而最低,恰恰印证了上面提到的问题:错误而清晰的细节能提高人眼感受,却会得到一个较差的PSNR
很明显的看到最右边一张图才是人眼感受最好的,结果PSNR/SSIM结果反而最低,恰恰印证了上面提到的问题:错误而清晰的细节能提高人眼感受,却会得到一个较差的PSNR
2.1 【注意力机制、超分】Learning Texture Transformer Network for Image Super-Resolution
 图像超分辨率(SR)是从低分辨率(LR)图像中恢复逼真的纹理;通过将高分辨率图像用作参考(Ref),可将相关纹理迁移到LR图像。但现有SR方法忽略了使用注意力机制从Ref图像迁移高分辨率(HR)纹理的情况,本文提出TT(Texture Transformer Network)SR,其中LR和Ref图像分别表示为转换器中的查询和关键字。TTSR由四个紧密相关的模块组成,这些模块针对图像生成任务进行了优化,包括DNN可学习的纹理提取器,相关性嵌入模块,用于纹理迁移的硬注意力模块和用于纹理合成的软注意力模块。这样的设计鼓励了跨LR和Ref图像的联合特征学习,其中可通过注意力发现深层特征对应关系,从而可以传递/迁移准确的纹理特征信息。
图像超分辨率(SR)是从低分辨率(LR)图像中恢复逼真的纹理;通过将高分辨率图像用作参考(Ref),可将相关纹理迁移到LR图像。但现有SR方法忽略了使用注意力机制从Ref图像迁移高分辨率(HR)纹理的情况,本文提出TT(Texture Transformer Network)SR,其中LR和Ref图像分别表示为转换器中的查询和关键字。TTSR由四个紧密相关的模块组成,这些模块针对图像生成任务进行了优化,包括DNN可学习的纹理提取器,相关性嵌入模块,用于纹理迁移的硬注意力模块和用于纹理合成的软注意力模块。这样的设计鼓励了跨LR和Ref图像的联合特征学习,其中可通过注意力发现深层特征对应关系,从而可以传递/迁移准确的纹理特征信息。 
2.2 【解耦表征、多模图像转换、超分、修复】Nested Scale-Editing for Conditional Image Synthesis
 提出一种图像合成方法,可在潜在码空间中提供分层导航。对于微小局部或非常低分辨率的图像,方法在生成最接近GT的采样图像方面始终胜过最新技术。
提出一种图像合成方法,可在潜在码空间中提供分层导航。对于微小局部或非常低分辨率的图像,方法在生成最接近GT的采样图像方面始终胜过最新技术。 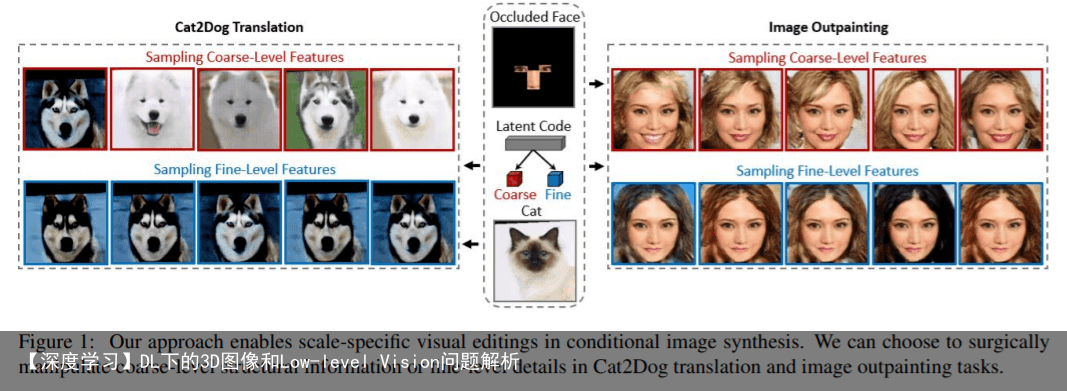
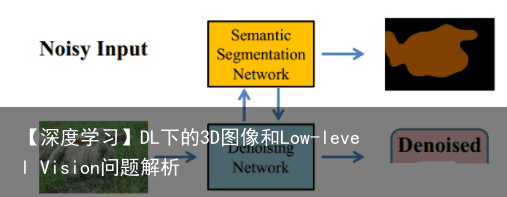 低级去噪任务+高级语义分割任务。
低级去噪任务+高级语义分割任务。
那么一般在什么应用场景会结合使用呢?比如做低质量人像识别,可通过low-level model得到较高质量的人像,再进行 high-level识别(然而在实际场景中,一般低质量的会被直接剔除掉)。。。这类问题的难点和有趣的地方在于“较高质量”的定义是客观/人类主观质量评价的,还是相对于高级任务有帮助的?Low-level和high-level又是如何mutual来学习的?
最近由于要做基于视频的低级+高级任务,故阅览了几篇经典的图像低级+高级任务结合的文章,总结分享一下。 Deep Generative Adversarial Compression Artifact Removal[1],ICCV2017 主要贡献如下:
设计了简单有效的生成器网络,并对比使用 MSE,SSIM,判别器对抗学习 三种不同的 Loss,对图像decompression去压缩任务的客观/主观质量的影响。
基于压缩算法一般先将图像分成patches再进行DCT的思想,判别器也是基于图像sub-patch level 来操作,可更好消除 mosquito noise。
探索了compression artifacts对深度学习目标检测器的影响,及decompression去压缩对检测器性能的提升。
生成器网络架构如下图: 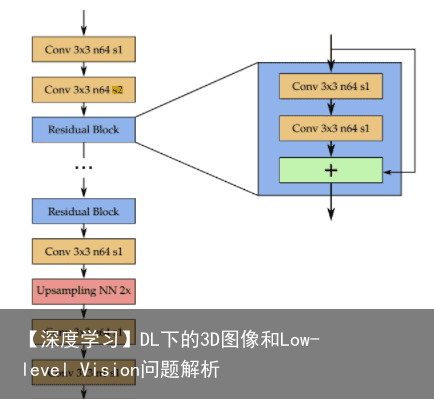 简单地堆残差block,只用了一个下采样及上采样来减少计算量,全卷积网络(即可在小Patch(128*128)进行训练,然后应用到更大的图片里;因为压缩损失一般是基于小block及macroblock)。
简单地堆残差block,只用了一个下采样及上采样来减少计算量,全卷积网络(即可在小Patch(128*128)进行训练,然后应用到更大的图片里;因为压缩损失一般是基于小block及macroblock)。
对于损失函数的设计,文中对比了以下三种:
MSE loss ,即对应 客观质量评价指标PSNR,故理论上使用MSE loss,监督出来图像的PSNR值会高。
SSIM loss, 即对应 客观质量评价指标SSIM,故理论上使用SSIM loss,监督出来图像的SSIM值会高。
基于生成对抗的 loss,保证分布相似及主观质量较好。
对于判别器,其输入是生成器输出的(128128)patch分成1616的sub-patches,这是针对压缩算法的特点设计的。
5 3D图像训练数据格式转换 常见的医学图像格式有DICOM(后缀名为.dcm),MHD(后缀名为.mhd和.raw)以及NIFTY(后缀名为.nii或.nii.gz)。这几种格式都不太方便直接进行操作,一般都使用对应的Python库将数据进行读取后,转换成numpy数组后再进行后续处理。
nnUNet中给出了一种建议的目标数据格式,将每一个病例的数据,都存成一个四维numpy数组以及与之对应的pickle文件。 图像裁剪Crop 图像裁剪就是将三维的医学图像裁剪到它的非零区域,具体方法就是在图像中寻找一个最小的三维bounding box,该bounding box区域以外的值为0,使用这个bounding box对图像进行裁剪。相比裁剪前,裁剪后的图像对于最后的分割结果没有影响,但是却可以减小图像尺寸,避免无用的计算,提高计算效率。这个操作对于部分数据集如大脑数据集比较有效,这些数据集中外围全黑的背景相对较多。裁剪在nnUNet的实现中可以分为3步。
 第一步根据四维图像数据data(C,X,Y,Z)生成三维的非零模板nonzero_mask,标示图像中哪些区域是非零的 。不同的模态都有对应的三维数据,产生不同的三维nonzero_mask,而整个四维图像的非零模板为各个模态非零模板的并集。最后调用scipy库的binary_fill_holes函数对生成的nonzero_mask进行填充。
第一步根据四维图像数据data(C,X,Y,Z)生成三维的非零模板nonzero_mask,标示图像中哪些区域是非零的 。不同的模态都有对应的三维数据,产生不同的三维nonzero_mask,而整个四维图像的非零模板为各个模态非零模板的并集。最后调用scipy库的binary_fill_holes函数对生成的nonzero_mask进行填充。
 重采样Resample 重采样目的是解决在一些三维医学图像数据集中,不同的图像中单个体素voxel所代表的实际空间大小spacing不一致的问题。因为卷积神经网络只在体素空间中进行操作,会忽视掉实际物理空间中大小信息。为了避免这种差异性,需要对不同图像数据在体素空间进行resize,保证不同的图像数据中,每个体素所代表的实际物理空间一致。
重采样Resample 重采样目的是解决在一些三维医学图像数据集中,不同的图像中单个体素voxel所代表的实际空间大小spacing不一致的问题。因为卷积神经网络只在体素空间中进行操作,会忽视掉实际物理空间中大小信息。为了避免这种差异性,需要对不同图像数据在体素空间进行resize,保证不同的图像数据中,每个体素所代表的实际物理空间一致。
具体需要将整个数据集resample到多大的spacing,即目标空间大小target_spacing应该多大呢?nnUNet给出的建议是在大多数时候使用数据集各个图像不同spacing的中值,但是在各向异性(最大坐标上的spacing÷最小坐标上的spacing>3)的数据集中,取数据集10%分位点的spacing值作为spacing最大坐标的目标空间大小会是更好的选择。重采样的步骤可以简单分成3步。
第一步是确定重采样的目标空间大小。在之前数据格式转换的时候,每个数据的spacing信息存储在对应的pickle文件中,需要依次进行读取,然后一起存放在一个列表spacings当中。之后调用numpy中函数统计每个维度spacing的中值即可。
target_spacing_percentile = 50 target = np.percentile(np.vstack(spacings), target_spacing_percentile, 0)接下来根据中值spacing进行判断,数据集是否存在各向异性的问题。nnUNet设定的判断标准是,中值spacing中三个维度,是否有一个维度spacing大于另一个维度spacing的3倍,并且,该维度的中值size小于另一个维度中值size的1/3。如果存在各向异性,对spacing特别大的维度,取数据集中该维度spacing值的10%分位点作为该维度的目标空间大小。
anisotropy_threshold = 3 worst_spacing_axis = np.argmax(target) other_axes = [i for i in range(len(target)) if i != worst_spacing_axis] other_spacings = [target[i] for i in other_axes] has_aniso_spacing = target[worst_spacing_axis] > (anisotropy_threshold * min(other_spacings)) has_aniso_voxels = target_size[worst_spacing_axis] * self.anisotropy_threshold < min(other_sizes) if has_aniso_spacing and has_aniso_voxels: spacings_of_that_axis = np.vstack(spacings)[:, worst_spacing_axis] target_spacing_of_that_axis = np.percentile(spacings_of_that_axis, 10) # dont let the spacing of that axis get higher than the other axes if target_spacing_of_that_axis < min(other_spacings): target_spacing_of_that_axis = max(min(other_spacings), target_spacing_of_that_axis) + 1e-5 target[worst_spacing_axis] = target_spacing_of_that_axis第二步根据target_spacing确定每张图像的目标尺寸。每张图像, spacing和shape之间的乘积为一个定值,代表整个图像在实际空间中的大小。因此可以得到如下关系:
new_shape = np.round(((np.array(original_spacing) / np.array(target_spacing)).astype(float) * shape)).astype(int)第三步调用skimage库中的reisze函数对每张图像进行resize即可, 但在nnUNet中会根据图像是否存在各向异性进行不同的resize策略。如果不存在各向异性,对整个三维图像进行3阶spline插值即可。如果图像存在各向异性,设spacing大的维度为z轴,则仅在图像的xy平面进行3阶spline插值,而在z轴采用最近邻插值。而对于分割的标注图像,无论各向异性与否, 在三个维度上都采用最近邻插值。下面代码中,用do_seperate_z表示是否存在各向异性,用axis表示各向异性图像中spacing最大的轴。
在医学图象中,多模态数据因成像机理不同而能从多种层面提供信息。多模态图像分割包含重点问题为如何融合(fusion)不同模态间信息,
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】DL下的3D图像和Low-level Vision问题解析 https://www.yhzz.com.cn/a/12392.html