【深度学习】孪生网络(Siamese Network)的模式和训练过程
文章目录 1 概述 2 Siamese network 孪生神经网络 3 孪生神经网络和伪孪生神经网络分别适用于什么场景呢? 4 细节 5 网络训练 6 人脸检测—Siamese Network 1 概述孪生神经网络(Siamese neural network),又名双生神经网络,是基于两个人工神经网络建立的耦合构架。孪生神经网络以两个样本为输入,其两个子网络各自接收一个输入,输出其嵌入高维度空间的表征,通过计算两个表征的距离,例如欧式距离,以比较两个样本的相似程度。
狭义的孪生神经网络由两个结构相同,且权重共享的神经网络拼接而成。广义的孪生神经网络,或伪孪生神经网络(pseudo-siamese network),可由任意两个神经网拼接而成。孪生神经网络通常具有深度结构,可由卷积神经网络、循环神经网络等组成,其权重可以由能量函数或分类损失优化。
孪生网络用于处理两个输入”比较类似”的情况。比如,两个句子或者词汇的语义相似度计算,指纹或人脸的比对识别等使用siamese network比较适合; 伪孪生神经网络适用于处理两个输入”有一定差别”的情况。如验证标题与正文的描述是否一致,或者文字是否描述了一幅图片,就应该使用伪孪生神经网络。 孪生神经网络可以用于解决类别很多(或者说不确定),然而训练样本的类别数较少的分类任务,即可以进行小样本(one-shot learning),且不容易被错误样本干扰,因此可用于对容错率要求严格的模式识别问题,例如人像识别、指纹识别、目标追踪等。
2 Siamese network 孪生神经网络Siamese和Chinese有点像。Siam是古时候泰国的称呼,中文译作暹罗。Siamese也就是“暹罗”人或“泰国”人。Siamese在英语中是“孪生”、“连体”的意思,这是为什么呢?
 简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
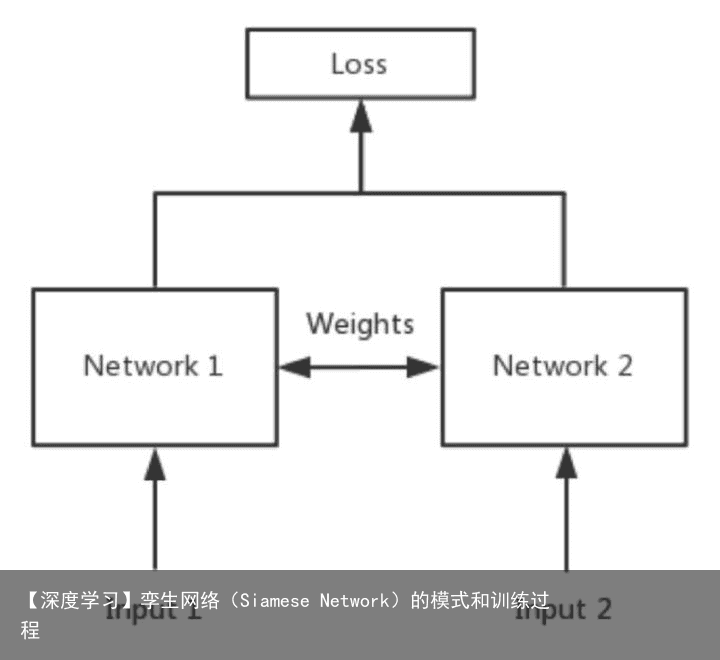 大家可能会有疑问:共享权值是什么意思?左右两个神经网络的权重一模一样?
大家可能会有疑问:共享权值是什么意思?左右两个神经网络的权重一模一样?
答:是的,在代码实现的时候,甚至可以是同一个网络,不用实现另外一个,因为权值都一样。对于siamese network,两边可以是lstm或者cnn,都可以。
大家可能还有疑问:如果左右两边不共享权值,而是两个不同的神经网络,叫什么呢?
答:pseudo-siamese network,伪孪生神经网络,如下图所示。对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
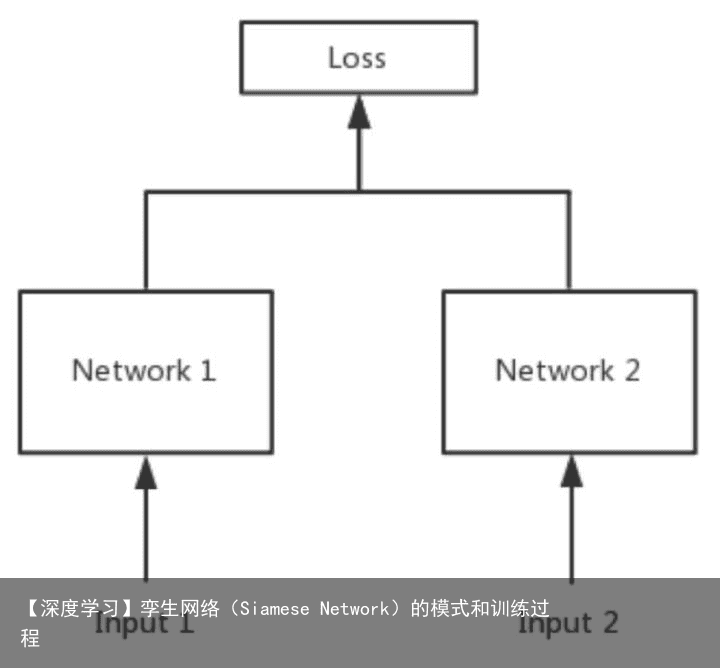
先上结论:孪生神经网络用于处理两个输入”比较类似”的情况。伪孪生神经网络适用于处理两个输入”有一定差别”的情况。比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。也就是说,要根据具体的应用,判断应该使用哪一种结构,哪一种Loss。
Softmax当然是一种好的选择,但不一定是最优选择,即使是在分类问题中。传统的siamese network使用Contrastive Loss。损失函数还有更多的选择,siamese network的初衷是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个”向量”,在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。其他的距离度量没有太多经验,这里简单说一下cosine和exp在NLP中的区别。
根据实验分析,cosine更适用于词汇级别的语义相似度度量,而exp更适用于句子级别、段落级别的文本相似性度量。其中的原因可能是cosine仅仅计算两个向量的夹角,exp还能够保存两个向量的长度信息,而句子蕴含更多的信息。
Siamese network是双胞胎连体,整一个三胞胎连体行不行?
4 细节OK,我们回到本篇博文的主题,下面是paper所用的Siamese网络(shared weights)。在网络的最后顶层,由线性全连接和ReLU激活函数,构成输出层。在paper中,采用的最后是包含两个全连接层,每个隐层包含512个神经元。
 除了Siamese网络,文献还提了另外一种Pseudo-siamese网络,这个网络与siamese network网络最大的区别在于两个分支是权值不共享的,是真正的双分支网络模型。Pseudo-siamese在网络的两个分支上,每个分支是不同的映射函数,也就是说它们提取特征的结构是不一样的,左右两个分支,有不同的权值、或者不同的网络层数等,两个函数互不相关,只是在最后的全连接层,将他们连接在一起了。这个网络相当于训练参数比Siamese网络的训练参数多了将近一倍,当然它比Siamese网络更加灵活。
除了Siamese网络,文献还提了另外一种Pseudo-siamese网络,这个网络与siamese network网络最大的区别在于两个分支是权值不共享的,是真正的双分支网络模型。Pseudo-siamese在网络的两个分支上,每个分支是不同的映射函数,也就是说它们提取特征的结构是不一样的,左右两个分支,有不同的权值、或者不同的网络层数等,两个函数互不相关,只是在最后的全连接层,将他们连接在一起了。这个网络相当于训练参数比Siamese网络的训练参数多了将近一倍,当然它比Siamese网络更加灵活。
数据处理部分,一般就是数据扩充,也就是给图片加上旋转、镜像、等操作。Paper采用的数据扩充,包含水平翻转、垂直翻转、还有就是旋转,包含90、180、270角度的旋转。训练迭代终止的方法不是采用什么early stop,而是启动让电脑跑个几天的时间,等到闲的时候,回来看结果,做对比(ps:这个有点low)。如果你是刚入门CNN的,还没听过数据扩充,可以看看:http://blog.csdn.net/tanhongguang1/article/details/46279991。Paper也是采用了训练过程中,随机数据的扩充的方法。
在孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。contrastive loss的表达式如下:  代表两个样本特征X 1和X 2 的欧氏距离(二范数)P 表示样本的特征维数,Y 为两个样本是否匹配的标签,Y=1 代表两个样本相似或者匹配,Y=0 则代表不匹配,m 为设定的阈值,N 为样本个数。
代表两个样本特征X 1和X 2 的欧氏距离(二范数)P 表示样本的特征维数,Y 为两个样本是否匹配的标签,Y=1 代表两个样本相似或者匹配,Y=0 则代表不匹配,m 为设定的阈值,N 为样本个数。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。  即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。 当 Y=0 (即样本不相似时),损失函数为
即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。 当 Y=0 (即样本不相似时),损失函数为 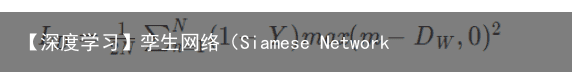 即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
即当样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大,这也正好符号我们的要求。
[注意这里设置了一个阈值margin,表示我们只考虑不相似特征欧式距离在0~margin之间的,当距离超过margin的,则把其loss看做为0(即不相似的特征离的很远,其loss应该是很低的;而对于相似的特征反而离的很远,我们就需要增加其loss,从而不断更新成对样本的匹配程度)]
6 人脸检测—Siamese Network将人脸通过若干层的卷积得到128维向量,用这128维向量代表一个人。两个人脸比对时,通过两个128维的元素方差和得到相似度。 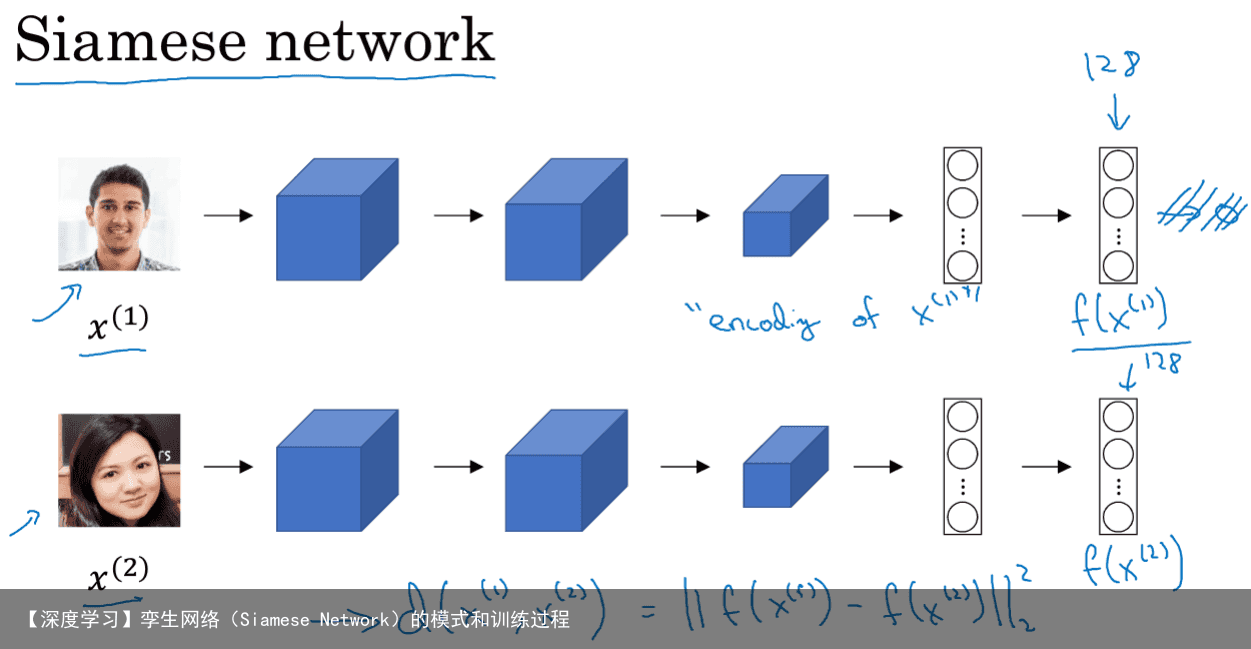

免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】孪生网络(Siamese Network)的模式和训练过程 https://www.yhzz.com.cn/a/12374.html