【深度学习】关于图像情感识别的探索(包括多模态)
文章目录 1 情感分类 1.1 基于低端视觉特征的图像情感分类 1.2 基于语义特征的图像情感分类 1.3 基于深度学习的图像情感分类 1.4 数据集 2 用深度神经网络识别面部表情 3 多模态情感识别 1 情感分类当前情感分类上,主要把情感分为两类或者八类:  图像情感分类方法从特征角度来看,主要可以划分为三个方向,即:基于低端视觉特征的图像情感分类方法、基于语义特征的图像情感分类方法以及基于深度学习的图像情感分类方法。
图像情感分类方法从特征角度来看,主要可以划分为三个方向,即:基于低端视觉特征的图像情感分类方法、基于语义特征的图像情感分类方法以及基于深度学习的图像情感分类方法。
1.1 基于低端视觉特征的图像情感分类
低级的眼特征和脸部特征,很好理解。
1.2 基于语义特征的图像情感分类
基于语义特征的图像情感分类方法,主要试图建立图像情感与诸如物体、场景等语义之间的联系。Borth(2013)筛选了1200个形容词名词对,例如美丽的花、可爱的狗等,然后针对这1200个概念,在传统低端特征的基础上建立了一个分类器,因而可以用图像对这1200不同概念的响应,生成一个1200维的情感特征向量,进行图像情感分类。与此同时,Yuan(2013)则是建立一个关于102个场景的分类器,其将图像对102个场景的响应结合人脸特征,作为情感特征,从而进行情感分类。
1.3 基于深度学习的图像情感分类
基于深度学习的图像情感分类 基于深度学习的图像情感分类方法,主要试图通过深度学习的方法,让网络自动学习对情感分类最有帮助的特征,其特征是通过学习而来,而非人工设计。You(2015)设计了一个深度卷积神经网络进行图像情感分类,并且利用反馈的机制,滤除训练集中标注错误的数据,进一步提升了图像情感分类能力。Wang(2016)通过两路网络分别学习形容词性质的描述性词语以及名词性质的物体词语的特征表示,最终将两路特征结合起来用于图像情感分类。
1.4 数据集
常用数据集 IASP (International Affective Picture System) IASPa Abstract GAPED (Geneva Affective Picture Database) MART devArt Tweet FlickrCC (Flickr creative common) Flickr Emotion6 FI (Flicker and Instagram) Emotion6 IESN FlickrLDL TwitterLDL 2 用深度神经网络识别面部表情情绪效价( Valence )和情绪唤醒(Arousal),是心理学专家用来评估人类情绪的专业术语。
其中,前者描述了一个人对于某事物的感兴趣或排斥的程度。后者是指一个人对外界刺激重新产生反应的程度,比如是微笑,大笑,狂笑,还是歇斯底里的笑。

fer2013数据集下载: 链接:https://pan.baidu.com/s/1QKpc5ZhXSBjeHRDas1vnng 提取码:0cbz
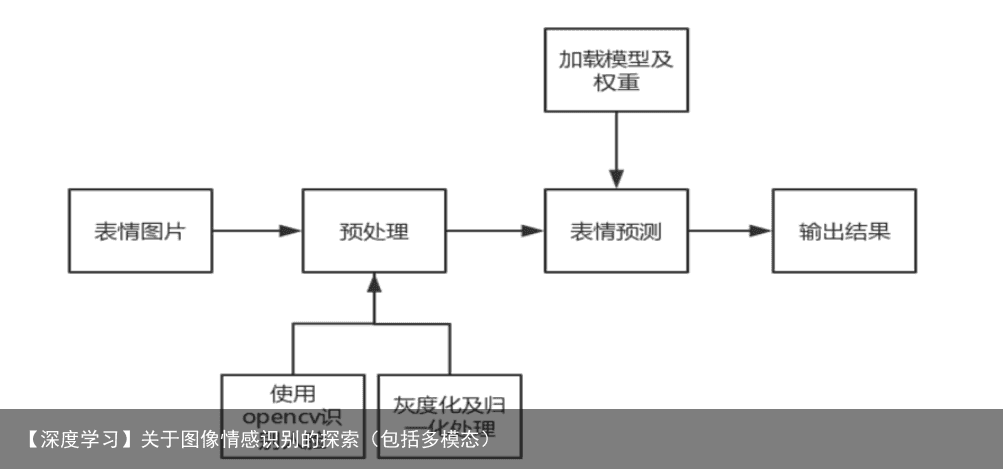
opencv中自带的人脸识别: haarcascade_frontalface_alt.xml + haarcascade_frontalface_default.xml 链接:https://pan.baidu.com/s/1WneMWNXzr4KDU3pegKIX_w 提取码:21eu
分为3步:数据集的处理、模型的构建及训练、预测。 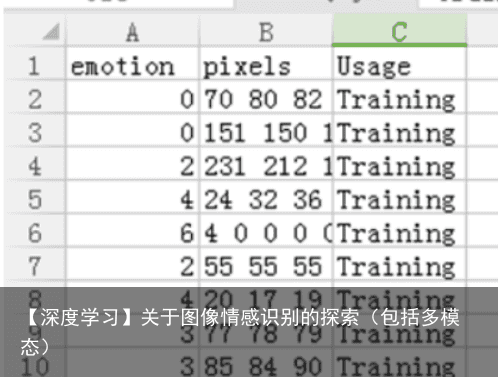
emotion:表示7个表情类别,0=angry,1=disgust,2=fear,3=happy,4=sad,5=surprise,6=normal pixels:表示表情图片的像素点 usage:表示图片的用途,训练or验证or测试
根据第三列Usage将数据集分为训练集train、验证集val、测试集test三个csv文件。 将上述3个csv文件分别转换成灰度图,并按照emotion列的分类保存在7个文件夹里。
模型的构建及训练 1、模型结构:4层卷积层,3层池化层,3层全连接层; 2、激活函数1-6均采用relu(AlexNet中提出的):f(x)=max(0,x);激活函数7采用softmax进行分类; 3、优化算法使用SGD随机梯度下降算法; 4、训练过程中,使用keras自带的ImageDataGenerator方法扩展数据集,实现数据增广,从而提高模型性能; 5、通过尝试后,批尺寸选为128,每次迭代步数为200,共迭代训练100次,能取得不错的效果; 模型结构如下图所示:
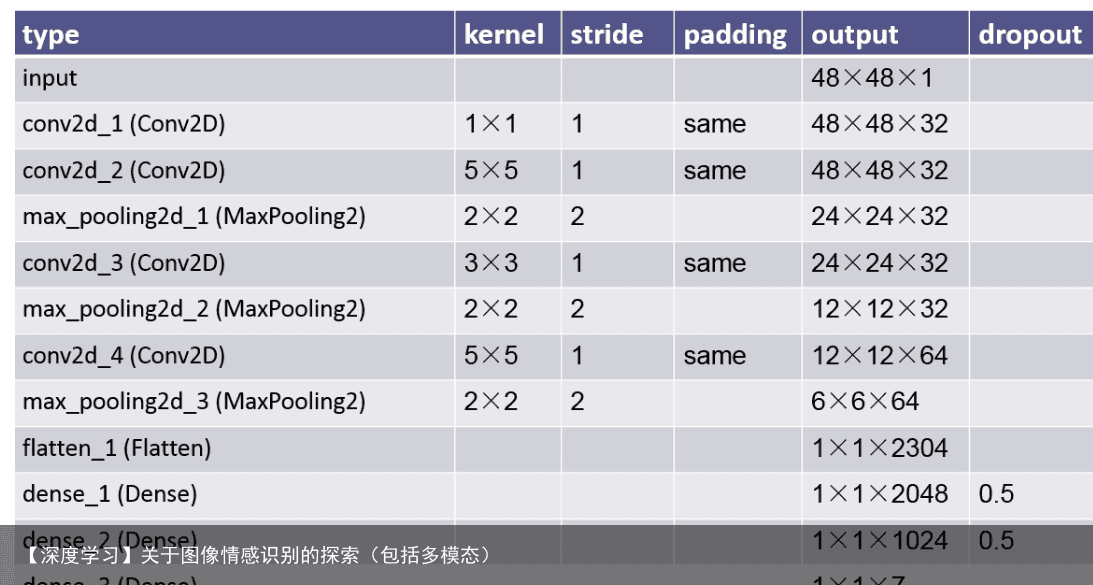 keras代码:
keras代码:

也可以视频实时预测
模型在测试集准确率为76%,测试集和验证集上的预测结果大约都在66-67%,验证集的混淆矩阵如下所示: 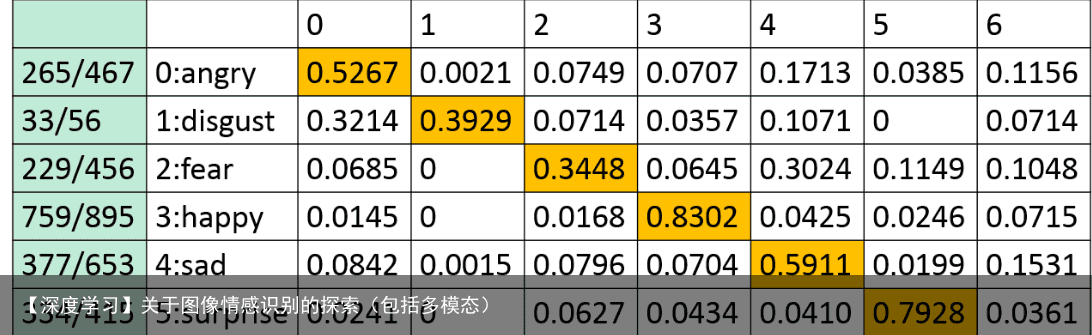 看出,标签为1,即disgust的预测准确率很低,这应该是因为样disgust的数量太少的原因导致的
看出,标签为1,即disgust的预测准确率很低,这应该是因为样disgust的数量太少的原因导致的
正确率并没有很高,大概是因为数据集的不均衡导致的; 后续思路:可以使用数据增广的方法,将每一种表情都扩展为一样的数量,进行训练; 网上有人说fer2013数据集的标签可能有一些错误
3 多模态情感识别 传统的基于视频图像的疲劳驾驶检测如下图:
传统的基于视频图像的疲劳驾驶检测如下图:  多模态的情绪识别与疲劳驾驶检测
多模态的情绪识别与疲劳驾驶检测
这种复杂的疲劳和情绪状态,多模态肯定是一个非常好的手段,因为你现在很难找到一个单一的信号能够对这个模型进行辨识。
一个是脑电信号,一个是眼动信号。大概在四年前提出了这个方案,为什么采用这两个模态而不是别的?因为刚才提到了脑电信号不管是神经科学还是医学类,它是最能直接反映人的情绪和状况,它是表现了我们人类内部的状况,眼动仪和追踪仪刚好是表明你的外部的状态,而且随着现在的技术发展,眼动仪追踪已经可以戴上眼镜了。最近韩国一个公司可以把眼动仪集成到一个非常好穿戴设备。
有了这样的两个模态,我们看看能否对情绪识别起到帮助。刚才说到了实际上这两个信息有个互补的特性,脑电信号反映了神经的内部,眼动刚好是外部的潜意识行为,当然也可以追加其他的一些模态的情况。 南大老师最近要求我分析一下论文,对网安很小白的我,决定分析下单眼情绪识别这篇文章,但是硬件很头疼,总结一下全脸的情绪识别部分(不是单眼哦),就到这啦。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】关于图像情感识别的探索(包括多模态) https://www.yhzz.com.cn/a/12372.html