【深度学习】对抗扰动、垃圾/钓鱼邮件自动分类和UEBA
文章目录 1 数据集 2 清洗数据集 3 GloVe + LSTM 4 GloVe词向量模型 5 搭建网络整体结构 6 训练模型并验证 7 对抗扰动 8 数据安全智能守护神UEBA(用户实际行为分析) 1 数据集总的数据集一共有4458条数据,将按照8:2进行划分训练集和验证集。通过分析发现,其中pam的数量有3866条,占数据集的大多数,可以考虑不平衡样本采样进行训练。
数据集的格式如图所示,有三列分别是ID,Label(pam、spam),Email  Spam表示垃圾邮件。
Spam表示垃圾邮件。
在实际中清洗数据也是非常必要的,套用一句俗话“数据决定了模型的上限”。常用的清洗数据的方法有:去掉停用词、去掉URL、去掉HTML标签、去掉特殊符号、去掉表情符号、去掉长重复字、将缩写补全、去掉单字、提取词干等等。当然,清洗数据也可能使模型变差,需要三思。提供部分处理的参考代码如下: 去掉停用词
from nltk.corpus import stopwords stop = set(stopwords.words(english)) text = “their are so many picture. how are you do this time very much!” clean_text = [] for word in word_tokenize(text): if word not in stop: clean_text.append(word) print(clean_text)去掉表情符号
# 删除表情符号 def remove_emoji(text): emoji_pattern = re.compile(“[” u”\U0001F600-\U0001F64F” # emoticons u”\U0001F300-\U0001F5FF” # symbols & pictographs u”\U0001F680-\U0001F6FF” # transport & map symbols u”\U0001F1E0-\U0001F1FF” # flags (iOS) u”\U00002702-\U000027B0″ u”\U000024C2-\U0001F251″ “]+”, flags=re.UNICODE) return emoji_pattern.sub(r, text)去掉特殊符号
import string def remove_punct(text): # 对punctuation中的词进行删除 table = str.maketrans(, , string.punctuation) return text.translate(table) 3 GloVe + LSTM环境要求:python3.6 、TensorFlow1.14.0、Keras=2.2.4
读取数据 由于数据量不是很大,还是选择了在训练集上进行分割,按8:2进行分割。 train = pd.read_csv(“../data/train.csv”, encoding=utf-8) # 后期清洗完数据后,会将训练集分为训练集、验证集、测试集 train_data = tweet_pad[:3000] test_data = tweet_pad[3000:] # 利用train_test_split函数进行拆分,需要引入 # from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(train_data, train[:3000][Label].values, test_size=0.2)加载GloVe词向量 GloVe词向量是基于共现矩阵的,所以GloVe会考虑全局特征。相比Word2Vec考虑上下文来看,似乎效果会更好一点,但实际上相差不大
4 GloVe词向量模型Glove认为Word2vec词向量的视野只有中心词周围的部分词语,缺少全局词语的信息;另外,w2v缺乏对高频词的处理。
glove的思路是将全局词-词共现矩阵进行分解,训练得到词向量。目标函数为: 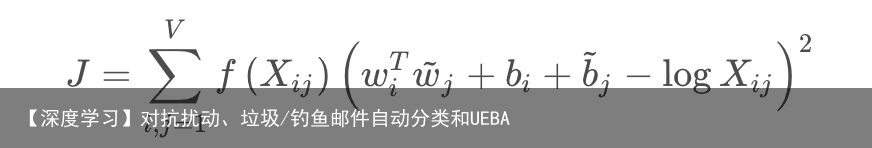

为了简单易操作,采用顺序方式Sequential来搭建模型。利用Sequential搭建模型的优点是便捷,但是受限于网络类型,不支持自定义网络层。如果后续想自己定义网络层,还是推荐函数式建模。更高级的可以使用子类的方式建模~
实现简单的LSTM网络:
# 构建模型 model = Sequential() embedding = Embedding(num_words, 100, embeddings_initializer=Constant(embedding_matrix), input_length=MAX_LEN, trainable=False) model.add(embedding) model.add(SpatialDropout1D(0.2)) model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2)) model.add(Dense(1, activation=sigmoid)) 6 训练模型并验证训练模型的时候要注意,由于使用深度学习框架进行训练,所以输入的数据需要经过预处理,这里的预处理指分词、填充、编码。
# 分词 + 填充 MAX_LEN = 50 # 输入每句话的长度,少的填充,多的截断。 tokenizer_obj = Tokenizer() tokenizer_obj.fit_on_texts(corpus) # 输入为两层列表格式[[…],[…],..] sequences = tokenizer_obj.texts_to_sequences(corpus) # 返回序列化的数据格式 # 填充序列,大于50的会被截断,小于50的会填充补0,truncating表示截断,padding表示填充 tweet_pad = pad_sequences(sequences, maxlen=MAX_LEN, truncating=post, padding=post)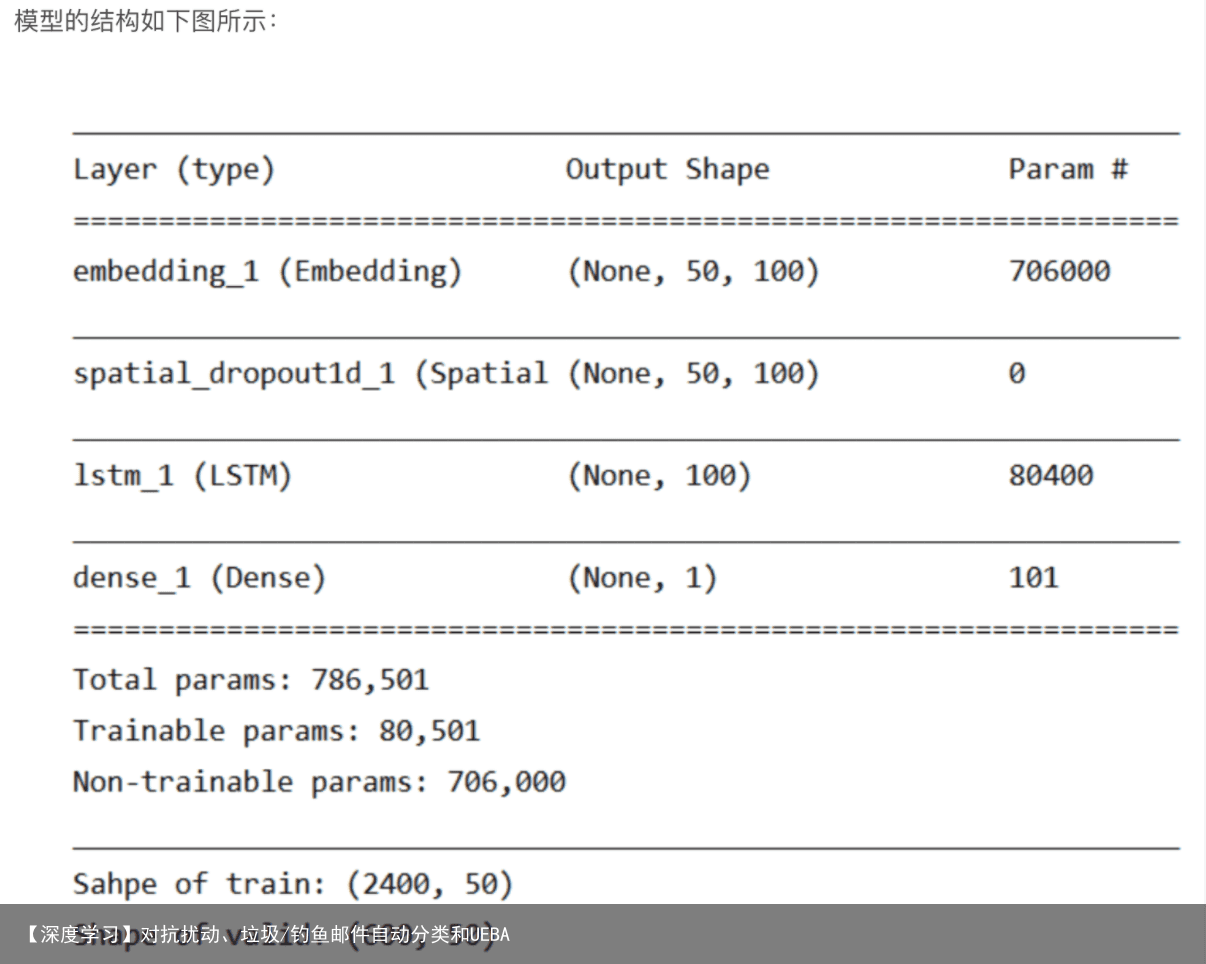
实验结果如下(数据量较小,得分偏高点:) 
随着GNN的应用越来越广,在安全非常重要的应用中应用GNN,存在漏洞可能是非常严重的。 比如说金融系统和风险管理,在信用评分系统中,欺诈者可以伪造与几个高信用客户的联系,以逃避欺诈检测模型;或者垃圾邮件发送者可以轻松地创建虚假的关注者,向社交网络添加错误的信息,以增加推荐和传播重大新闻的机会,或者操控在线评论和产品网站。 因此,我们需要研究对图神经网络的攻击和防御,在我们真正部署一个模型前,应该确认一下这个模型在面对对抗攻击的时候足够健壮? 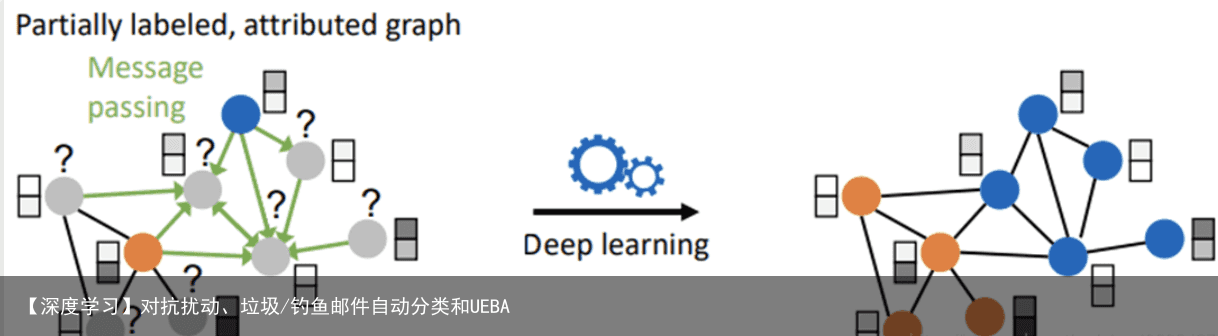
备注: 考虑一个简单且经典的场景,图上的结点分类任务。 给定一张图,图上部分结点有标签,通过训练一个深度学习模型来预测图上结点的分类。
一方面预测不基于单独的示例而是联合了图上很多实例的关系效应可能提高鲁棒性;另一方面信息传播带来的级联效应,操纵一个示例可能会影响其他实例,可能会降低鲁棒性。
本文就是研究操纵模型的预测结果是否可能?并且提出一个名叫nettack的对抗攻击算法,来欺骗图深度学习模型。 投毒攻击( poisoning attack) 发生在模型被训练前,攻击者可以在训练数据中投毒,导致训练的模型出现故障 逃逸攻击( evasion attack) 发生在模型被训练以后或者测试阶段,模型已经固定了,攻击者无法对模型的参数或者结构产生影响
图神经网络对抗攻击未来发展方向 不可感知的扰动度量:人无法轻易分辨是否有扰动,找到简洁的扰动评估方法很重要 研究的图的种类:主要研究集中在带节点属性的静态图,带边属性的图和动态图研究很少 图上对抗样本的存在性和可传递性:对于理解图上的学习算法很重要,有助于帮助建立健壮的模型 可放缩性:攻击方法的高度复杂性阻碍了在实际中的应用,大多数方法时间复杂度高,基于梯度,降低复杂度仍是一个问题 在过去的几年中,神经网络的兴起与应用成功推动了模式识别和数据挖掘的研究。许多曾经严重依赖于手工提取特征的机器学习任务(如目标检测、机器翻译和语音识别),如今都已被各种端到端的深度学习范式(例如卷积神经网络(CNN)、长短期记忆(LSTM)和自动编码器)彻底改变了。曾有学者将本次人工智能浪潮的兴起归因于三个条件,分别是:
计算资源的快速发展(如GPU) 大量训练数据的可用性 深度学习从欧氏空间数据中提取潜在特征的有效性 尽管传统的深度学习方法被应用在提取欧氏空间数据的特征方面取得了巨大的成功,但许多实际应用场景中的数据是从非欧式空间生成的,传统的深度学习方法在处理非欧式空间数据上的表现却仍难以使人满意。例如,在电子商务中,一个基于图(Graph)的学习系统能够利用用户和产品之间的交互来做出非常准确的推荐,但图的复杂性使得现有的深度学习算法在处理时面临着巨大的挑战。这是因为图是不规则的,每个图都有一个大小可变的无序节点,图中的每个节点都有不同数量的相邻节点,导致一些重要的操作(例如卷积)在图像(Image)上很容易计算,但不再适合直接用于图。此外,现有深度学习算法的一个核心假设是数据样本之间彼此独立。然而,对于图来说,情况并非如此,图中的每个数据样本(节点)都会有边与图中其他实数据样本(节点)相关,这些信息可用于捕获实例之间的相互依赖关系。
近年来,人们对深度学习方法在图上的扩展越来越感兴趣。在多方因素的成功推动下,研究人员借鉴了卷积网络、循环网络和深度自动编码器的思想,定义和设计了用于处理图数据的神经网络结构,由此一个新的研究热点——“图神经网络(Graph Neural Networks,GNN)”应运而生,本篇文章主要对图神经网络的研究现状进行简单的概述。
8 数据安全智能守护神UEBA(用户实际行为分析)用户身份信息容易伪造,但行为活动却不行。密切监视一个人的行为活动可以揭露出他的真实意图。同样,密切监视机器的行为活动也能暴露出潜在的安全问题。
将安全信息、事件管理(SIEM)与用户的实际行为分析(UEBA)相结合,可以监视企业的大量用户和设备。UEBA利用机器学习来识别用户活动中的异常,然后以可视化形式向管理员展示这些情况,使这些异常行为出现时可以及时解决。 
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】对抗扰动、垃圾/钓鱼邮件自动分类和UEBA https://www.yhzz.com.cn/a/12344.html