【深度学习】深入浅出对抗机器学习(AI攻防)
文章目录 1 Attack ML Model概述 2 基本概念 3 攻击分类 4 经典的对抗性样本生成算法 5 经典的对抗防御方法 6 人工智能安全现状概析 1 Attack ML Model概述随着AI时代机器学习模型在实际业务系统中愈发无处不在,模型的安全性也变得日渐重要。机器学习模型很可以会遭到恶意攻击,比较直接就能想到的如:人脸识别模型的攻击。训练出具有对抗性的机器学习模型,在业务系统存在着越来越重要的实际意义。
机器学习模型攻击要做的事情如下图所示: 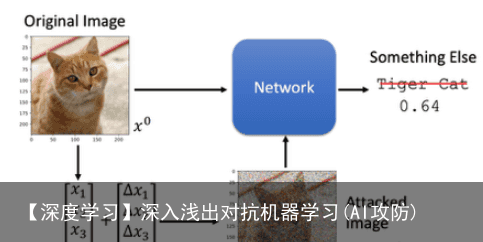 假设我们有一个Network用来做动物的图像识别。我们输入一张如图所示的图片, Network预测为“Tiger Cat”。机器学习模型攻击是在图片上加上一个微小的噪音Δ x,使得图片看起来还是一只“Tiger Cat”,但是通过Network的预测结果却是其他动物了。 并不需要一张图片训练一个噪音,一个噪音可以attack所有的图片:
假设我们有一个Network用来做动物的图像识别。我们输入一张如图所示的图片, Network预测为“Tiger Cat”。机器学习模型攻击是在图片上加上一个微小的噪音Δ x,使得图片看起来还是一只“Tiger Cat”,但是通过Network的预测结果却是其他动物了。 并不需要一张图片训练一个噪音,一个噪音可以attack所有的图片:

带一副眼镜,就能骗过人脸识别系统: 
对抗攻击是指在原始样本中加入人眼无法察觉的噪声,该噪声不影响人对预测结果的判定,但是会让深度神经网络DNN受到愚弄,产生错误的预测结果。
加入噪音后的输入被称为对抗性样本。
这里的对抗性的含义,与生成对抗网络GAN中的对抗是不同的。GAN中的对抗是指生成器与判别器之间的对抗,在对抗中得到性能提升。而对抗攻击是指对抗性样本对DNN的愚弄。虽然GAN中生成器的目标也是愚弄判别器,但是生成器所产生的图片是人眼能看出变化的,也就是生成器的目标是让人眼将它产生的fake图片认为是真的,同时让判别器也将fake图片认为是真的。而对抗攻击中特别强调愚弄DNN的同时,不能被人眼发觉。这是两者最大的区别。
3 攻击分类按照攻击者具备的能力,可以分为:
白盒攻击:攻击者知道模型和参数,能在攻击时与模型有交互,并观察输入输出。
黑盒攻击:攻击者不知道模型和参数,能在攻击时与模型有交互,并观察输入输出。
按照攻击要达到的目标,可以分为:
无目标攻击(untargeted attack):愚弄DNN时,不指定DNN误判的结果,只要让DNN将对抗性样本误判为非原来label即可。
有目标攻击(targeted attack):愚弄DNN时,指定DNN误判的结果,即让DNN将对抗性样本识别为攻击者期望的label。
4 经典的对抗性样本生成算法有了对抗性样本的概念和目的,那么下面就要考虑如何产生对抗性样本。
对抗性样本的生成算法有很多种,最为经典的是FGSM(Fast Gradient Sign Method),也最好理解。
该算法的核心思想,如下公式所示:
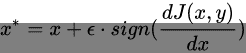
 可以这样理解这个公式,被攻击的DNN网络的参数,不论是白盒攻击还是黑盒攻击,都是不能改变的。那么攻击者就训练一个噪声矩阵,噪声矩阵的参数是可变的,是要在攻击过程中训练的。而loss函数通常是指导DNN网络向着负梯度方向调整参数,让其更加准确。那么攻击者训练的噪声矩阵的参数调整方向就是正梯度的方向,让DNN不准确,犯的错误更大。但是有一个前提就是不能被人眼识别出来,因此设置了一个超参数 ,让最终添加的噪音被限制在一定幅度。 Szegedy等人做出了一个有趣的发现:几种机器学习模型(包括最新的神经网络)容易受到对抗样本的攻击。也就是说,这些机器学习模型对这些样本进行了错误分类,这些样本与从数据分布中得出的正确分类的样本仅稍有不同。在许多情况下,在训练数据的不同子集上训练的、具有不同体系结构的各种模型都会将对抗样本错误分类。这表明对抗样本暴露了我们训练算法中的基本盲点。
可以这样理解这个公式,被攻击的DNN网络的参数,不论是白盒攻击还是黑盒攻击,都是不能改变的。那么攻击者就训练一个噪声矩阵,噪声矩阵的参数是可变的,是要在攻击过程中训练的。而loss函数通常是指导DNN网络向着负梯度方向调整参数,让其更加准确。那么攻击者训练的噪声矩阵的参数调整方向就是正梯度的方向,让DNN不准确,犯的错误更大。但是有一个前提就是不能被人眼识别出来,因此设置了一个超参数 ,让最终添加的噪音被限制在一定幅度。 Szegedy等人做出了一个有趣的发现:几种机器学习模型(包括最新的神经网络)容易受到对抗样本的攻击。也就是说,这些机器学习模型对这些样本进行了错误分类,这些样本与从数据分布中得出的正确分类的样本仅稍有不同。在许多情况下,在训练数据的不同子集上训练的、具有不同体系结构的各种模型都会将对抗样本错误分类。这表明对抗样本暴露了我们训练算法中的基本盲点。
这些对抗样本的原因是一个谜,而推测性的解释表明,这是由于深度神经网络的极端非线性所致,也许是由于模型平均不足和纯监督学习问题的正则化不足所致。我们证明这些推测性假设是不必要的。高维空间中的线性行为足以引起对抗样本。这种观点使我们能够设计一种快速生成对抗样本的方法,从而使对抗性训练切实可行。我们表明,对抗性训练可以提供dropout以外的正则化收益。通用的正则化策略(例如dropout、预训练和模型平均)并不能显着降低模型对付对抗样本的脆弱性,但改用非线性模型族(如RBF网络)可以做到。
我们的解释表明,设计模型因其线性而易于训练,而设计模型则利用非线性效应来抵抗对抗性扰动,这之间存在根本的张力。从长远来看,通过设计可以成功地训练更多非线性模型的更强大的优化方法,可以避免这种折衷。 基于FGSM算法被识别为烤面包机的家猪(概率为74.31%)的图片效果如下。  由于我们设置的退出条件是概率大于60%,所以FGSM没有继续迭代下去,我们通过设置阈值可以得到概率更大的图片,在进一步的实验中我们通过37次迭代得到了概率为99.56%的攻击图片。 batch:34 Cost: 97.030985%
由于我们设置的退出条件是概率大于60%,所以FGSM没有继续迭代下去,我们通过设置阈值可以得到概率更大的图片,在进一步的实验中我们通过37次迭代得到了概率为99.56%的攻击图片。 batch:34 Cost: 97.030985%
batch:35 Cost: 90.346575%
batch:36 Cost: 63.920081%
batch:37 Cost: 99.558592%
基于FGSM算法被识别为烤面包机的家猪(概率为99.56%)的图片效果如下。 
对抗性访防御最容易想到的就是把对抗性样本加入到训练集中,让模型见多识广,就可以减少被欺骗的可能了。这种方式被称为对抗训练。由于训练数据增多了,所以对抗训练能够让模型的准确率上有所提升,且在对对抗性样本的防御上鲁棒性更好。
集成对抗训练是在对抗训练的基础上采用了集成架构。即用不同的算法产生对抗性样本,构成不同的训练数据集,分别训练出若干模型,最后将这些模型进行集成使用。
其缺点是,训练成本高,每次增加新的对抗性样本,都要重新训练网络。
除了上述方法外,《Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks 》提出了一种防御蒸馏的方法。 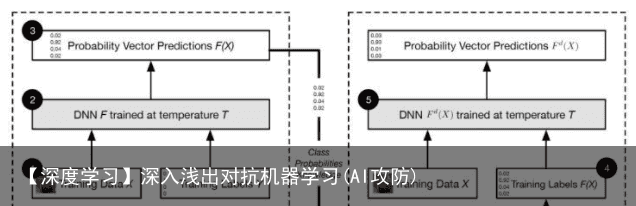 蒸馏是说教师网络将训练数据和硬标签中蕴含的分类知识蒸馏出来,以软标签的形式体现,而这个软标签是被蒸馏温度T控制的,因此,再基于此软标签去训练学生网络,就能够让学生网络对对抗性攻击不敏感,鲁棒性更好。
蒸馏是说教师网络将训练数据和硬标签中蕴含的分类知识蒸馏出来,以软标签的形式体现,而这个软标签是被蒸馏温度T控制的,因此,再基于此软标签去训练学生网络,就能够让学生网络对对抗性攻击不敏感,鲁棒性更好。
在分析之前,我们首先来简单的介绍一下人工智能的应用。由于人工智能具有突出的数据分析、知识提取、自主学习等优点,被广泛应用在网络防护、数据管理、信息审查、智能安防、金融风控以及舆情监测等方面。在这些方面,往往存在若干安全风险,常见风险如下:
1.框架安全风险近些年来,我们熟知的深度学习框架TensorFlow、Caffe等,及其依赖库被多次发现存在安全漏洞,这些漏洞可被攻击者利用,引发系统安全问题。
2.数据安全风险攻击者可以通过网络的内部参数逆向获取网络训练的数据集;人工智能技术还会加强数据挖掘的能力,这加大了隐私泄露的风险,例如2018年3月的Facebook数据泄露事件。
3.算法安全风险对于深度学习网络目标函数定义的不准确、不合理或者不正确也可能会导致错误甚至伤害性的结果。错误的目标函数、计算成本太高的目标函数、表达能力有限的网络都可能使网络产生错误的结果。例如,2018年3月,Uber自动驾驶汽车因机器视觉系统未及时识别路上突然出现的行人,导致与行人相撞,导致行人死亡的事故。
算法存在偏见与人工智能的不可解释性也是一个重大的问题。之前美国利用人工智能算法预测犯罪的人,名单暴露,其中许多无辜的人被冤枉,并且被冤枉的人中大多数为黑人,并且对于决策算法中系统为什么做出这样的决策,即使它的开发者也无法给出合理的解释。
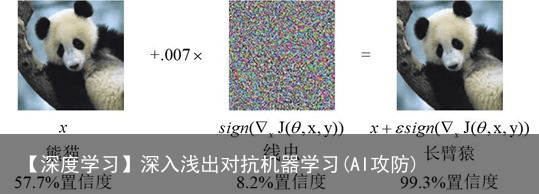
对抗性样本的出现也会使算法出现误判的情况,如下图中加入少量的噪声,AI便将熊猫以很高的置信度识别成长臂猿。
只要有足够的训练数据,人工智能就可以制作虚假的信息,用于不法活动。例如AI换脸技术DeepFakes,还有前段时间出现的DeepNude。一些不法分子利用虚假的语音与视频来实施zhapian。目前谷歌发明的聊天机器人在与人进行电话聊天时,已经完全能骗过人类。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】深入浅出对抗机器学习(AI攻防) https://www.yhzz.com.cn/a/12342.html