【深度学习】超强优化器如何与网络有机结合
1 Ranger优化器 2 一个例子(基于CNN和pytorch) 3 剪枝(减小优化器压力) 1 Ranger优化器RAdam + Lookahead + Gradient Centralization 优化器(Optimizer)对于深度神经网络在大型数据集上的训练是十分重要的,如SGD和SGDM,优化器的目标有两个:加速训练过程和提高模型的泛化能力。目前,很多工作研究如何提高如SGD等优化器的性能,如克服训练中的梯度消失和梯度爆炸问题,有效的trick有权值初始化、激活函数、梯度裁剪以及自适应学习率等。而一些工作则从统计的角度对权值和特征值进行标准化来让训练更稳定,比如特征图标准化方法BN以及权值标准化方法WN。。
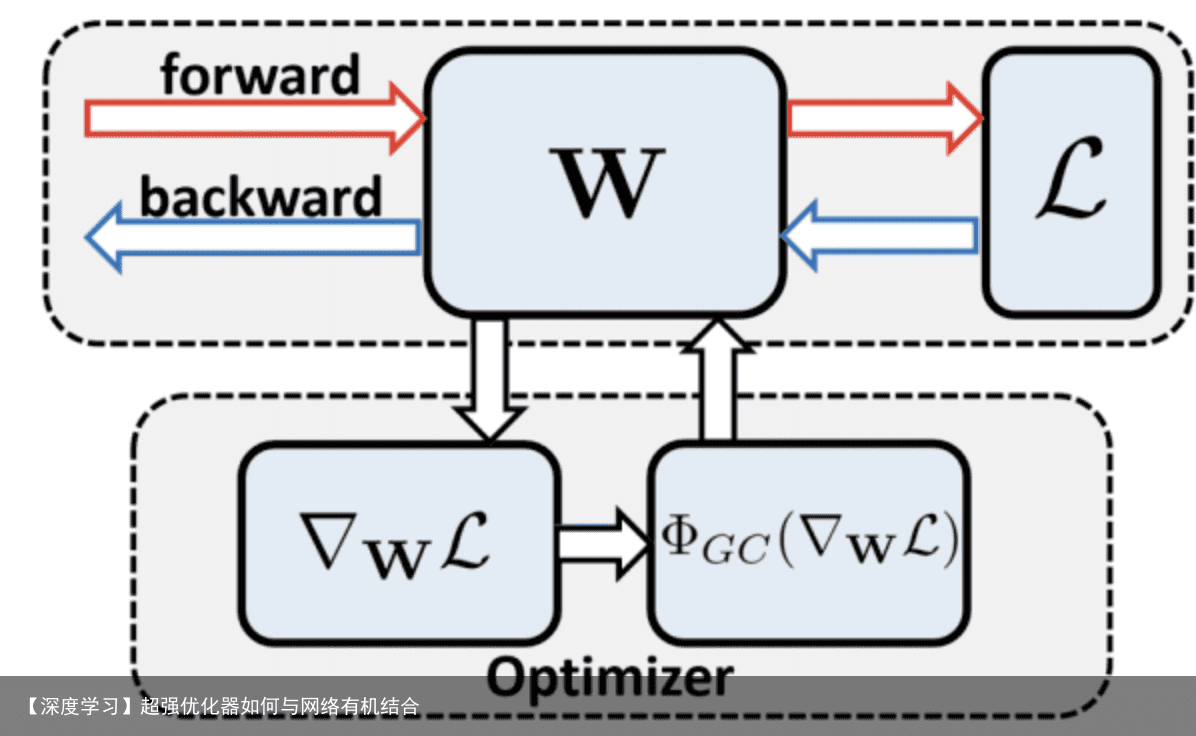 与在权值和特征值进行标准化方法不同,论文提出作用于权值梯度的高性能网络优化算法梯度中心化(GC, gradient centralization),能够加速网络训练,提高泛化能力以及兼容模型fine-tune。如图a所示,GC的思想很简单,零均值化梯度向量,能够轻松地嵌入各种优化器中。论文主要贡献如下:
与在权值和特征值进行标准化方法不同,论文提出作用于权值梯度的高性能网络优化算法梯度中心化(GC, gradient centralization),能够加速网络训练,提高泛化能力以及兼容模型fine-tune。如图a所示,GC的思想很简单,零均值化梯度向量,能够轻松地嵌入各种优化器中。论文主要贡献如下:
提出新的通用网络优化方法,梯度中心化(GC),不仅能平滑和加速训练过程,还能提高模型的泛化能力。 分析了GC的理论属性,表明GC能够约束损失函数,标准化权值空间和特征值空间,提升模型的泛化能力。另外,约束的损失函数有更好的Lipschitzness(抗扰动能力,函数斜率恒定小于一个Lipschitze常数),让训练更稳定、更高效。 Motivation BN和WS使用Z-score标准化分别操作于特征值和权重,实际是间接地对权值的梯度进行约束,从而提高优化时损失函数的Lipschitz属性。受此启发,论文直接对梯度操作,首先尝试了Z-score标准化,但实验发现并没有提升训练的稳定性。之后,尝试计算梯度向量的均值,对梯度向量进行零均值化,实验发现能够有效地提高损失函数的Lipschitz属性,使网络训练更稳定、更具泛化能力,得到梯度中心化(GC)算法。
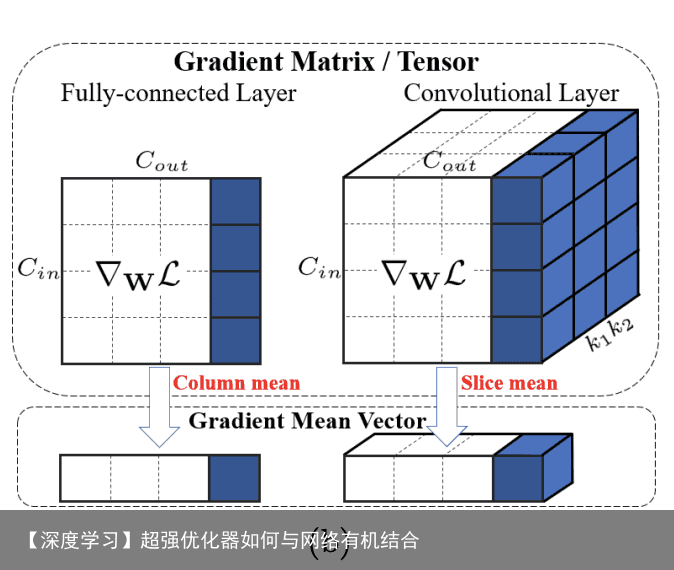
Notations 定义一些基础符号,使用$W \in \mathbb{R}^{M \times N}$统一表示全连接层的权值矩阵$W{fc} \in \mathbb{R}^{C{in}\times C{out}}$和卷积层的权值张量$W{conv} \in \mathbb{R}^{(C_{in} k_1 k2)\times C{out}}$,$wi \in \mathbb{R}M$为权值矩阵$W$的第$i$列,$\mathcal{L}$为目标函数,$\nabla{W}\mathcal{L}$和$\nabla_{w_i}\mathcal{L}$为$\mathcal{L}$对$W$和$wi$的梯度,$W$与$\nabla{W}\mathcal{L}$的大小一样。定义$X$为输入特征图,则$WT X$为输出特征图,$e=\frac{1}{\sqrt{M}}1$为$M$位单位向量(unit vector),$I\in\mathbb{R}^{M\times M}$为单位矩阵(identity matrix)。
Formulation of GC
 使用方法:
使用方法: 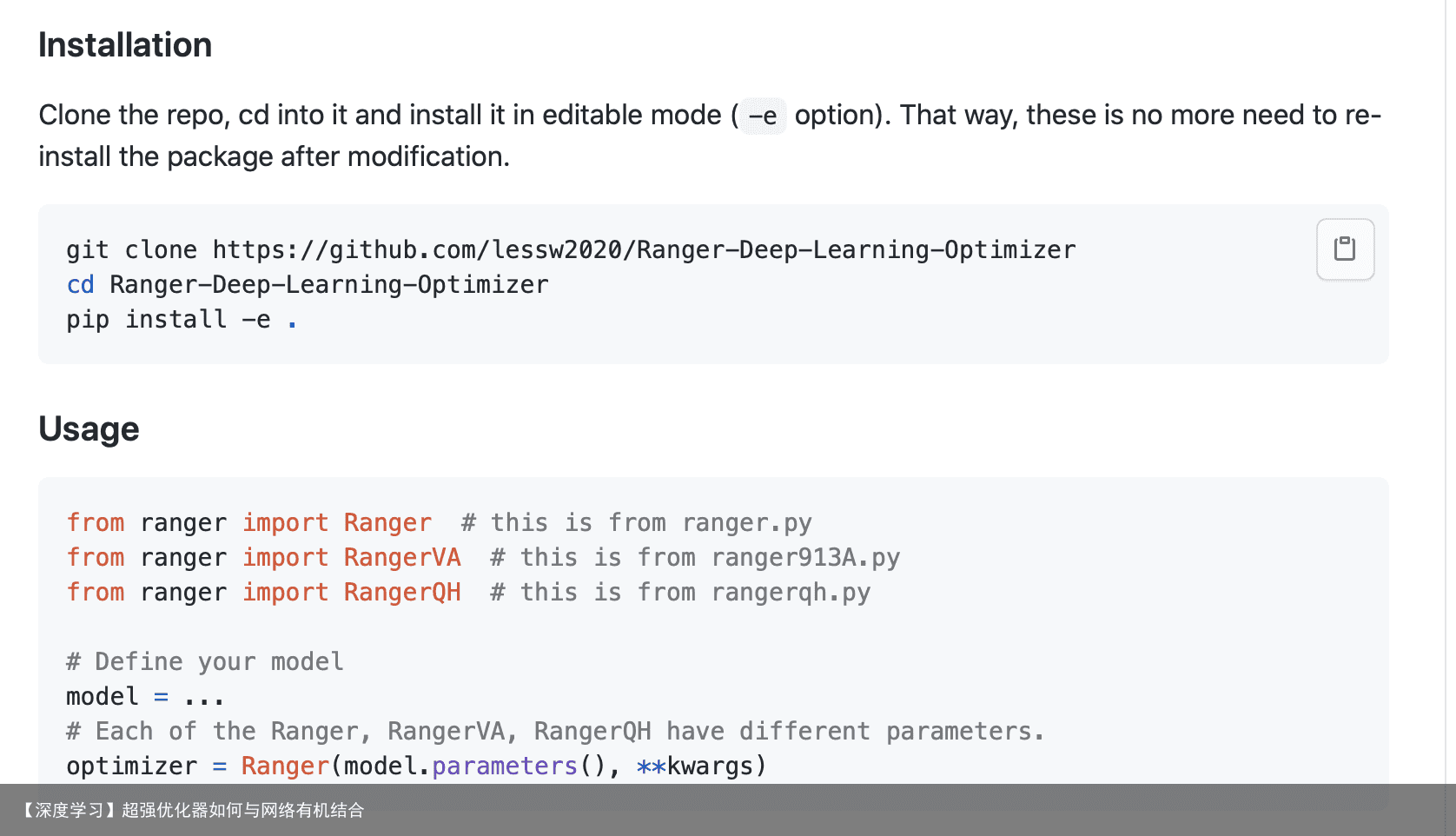
 换成如下代码:
换成如下代码:
结果: 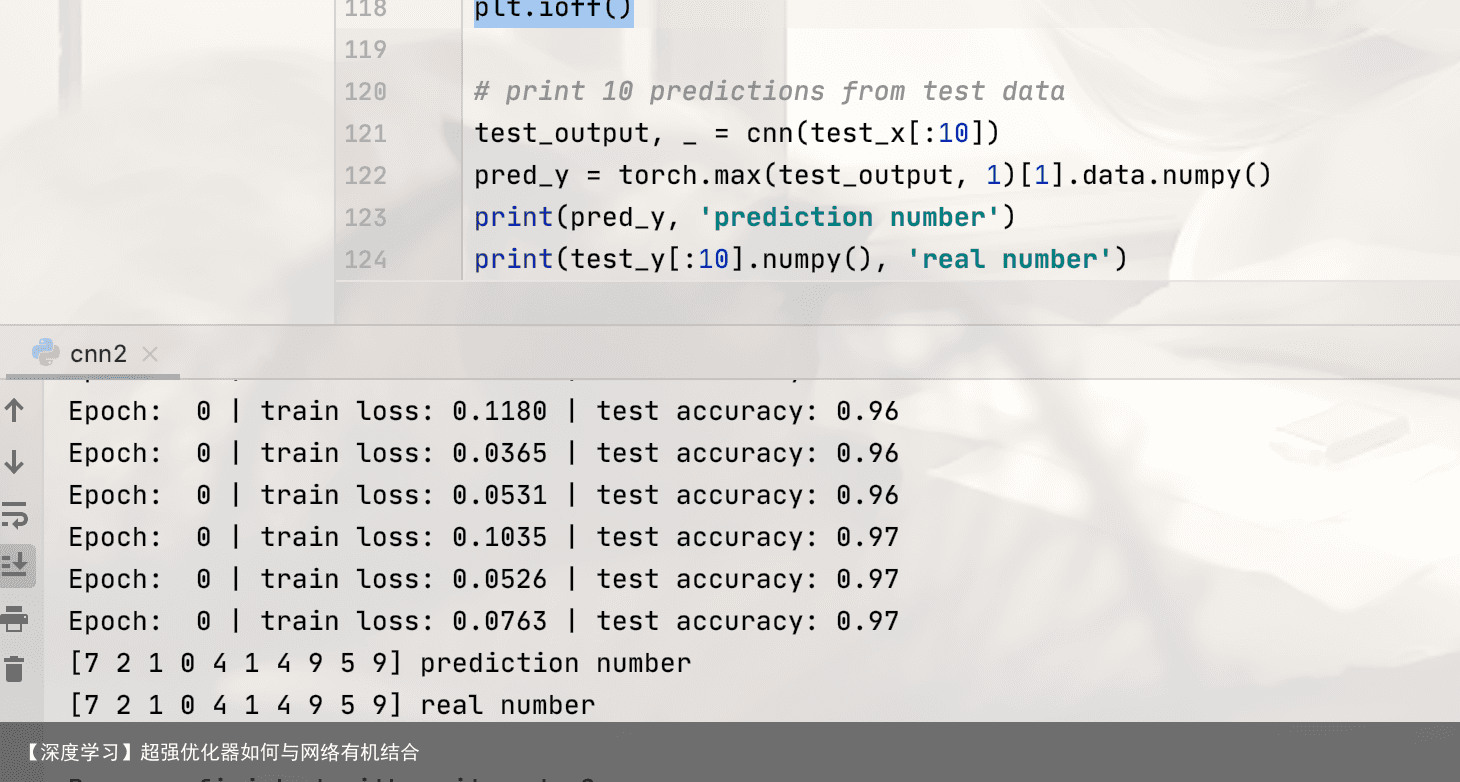
通过观察深度学习模型,可以发现其中很多kernel的权重很小,均在-1~1之间震荡,对于这些绝对值很小的参数,可以视其对整体模型贡献很小,将其删除,然后将剩余的权重构成新的模型,以达到模型压缩,加速,并保证精准度不变的目的。
基本步骤:
1.实现原始网络,并将其训练到收敛,保存权重
2.观察对每一层的权重,判断其对模型的贡献大小,删除贡献较小的kernel,评判标准可以是std,sum(abs),mean等
3.当删除部分kernel后,会导致输出层的channel数变化,需要删除输出层对应kernel的对应channel
4.构建剪枝后的网络,加载剪枝后的权重,与原模型对比精准度。
5.使用较小的学习率,rebirth剪枝后的模型
6.重复第1步
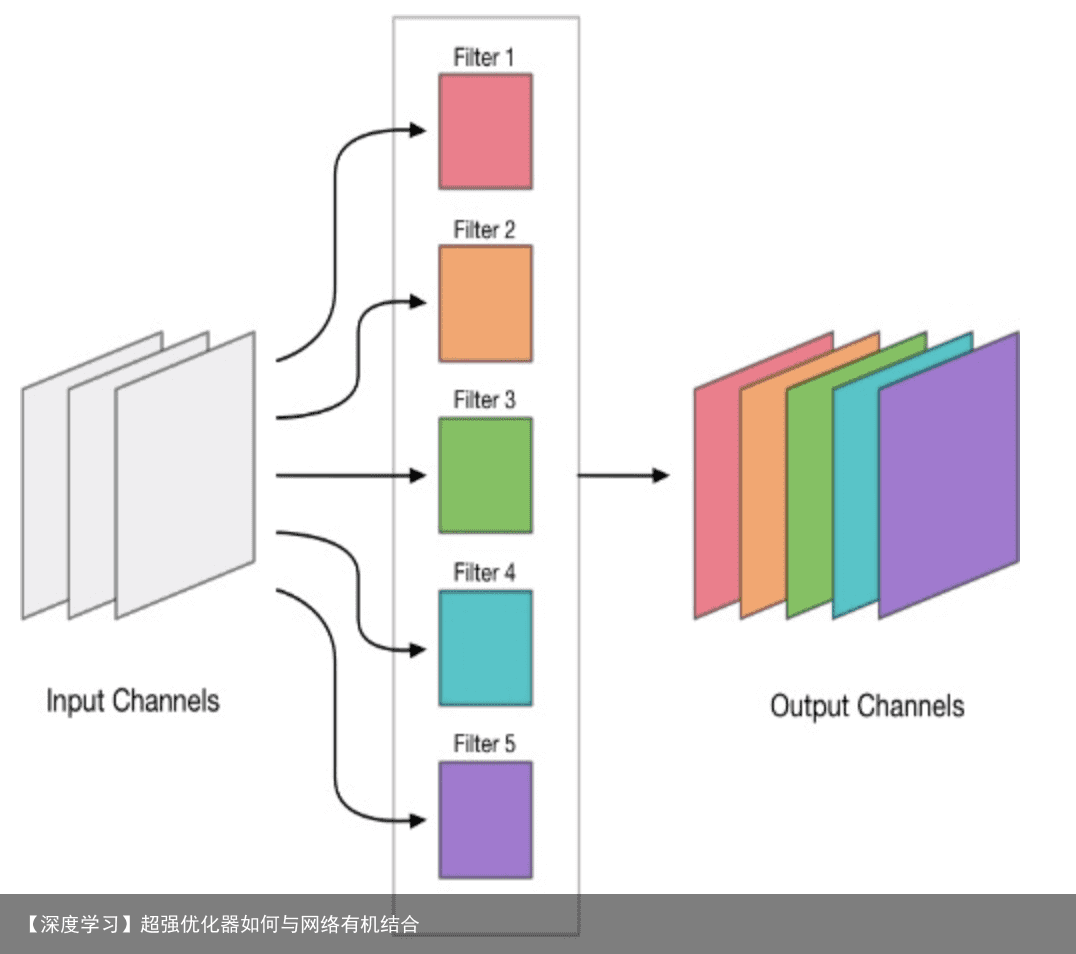
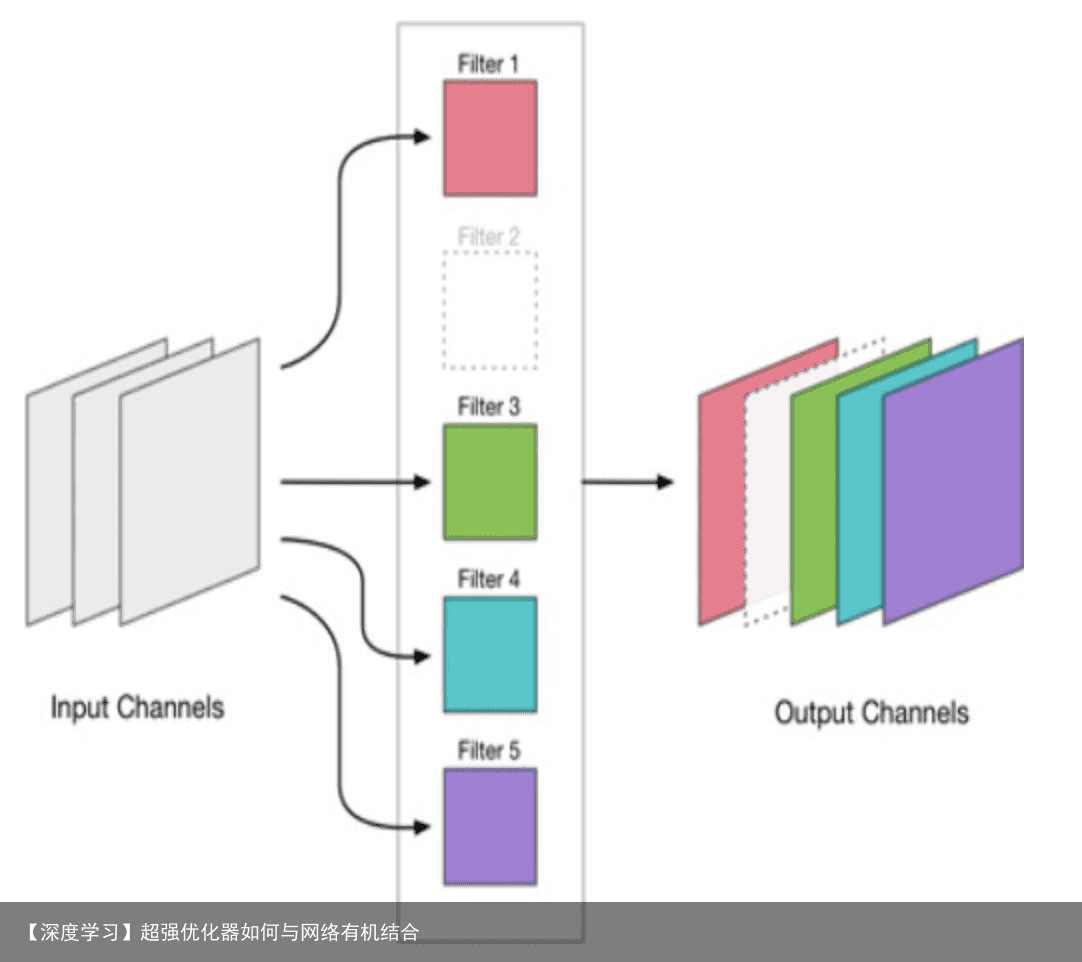 上图展示了conv的kernel剪枝后导致的输出维度变化 一个使用mnist的简单示例
上图展示了conv的kernel剪枝后导致的输出维度变化 一个使用mnist的简单示例
后面层重复以上操作
剪枝后结果对比 原始模型精度 模型权重大小从400多kb减小到了100多kb 剪枝是模型压缩的一个子领域,依据剪枝粒度可以分为非结构化/结构化剪枝,依据实现方法可以大致分为基于度量标准/基于重建误差/基于稀疏训练的剪枝,并且逐渐有向AutoML发展的趋势。由于实现方法在剪枝粒度上是有通用性的,本文主要从实现方法进行展开,康康近年来关于剪枝的有的没的,从个人角度对近几年经典的剪枝方法以及其拓展进行一下梳理。
基于度量标准的剪枝
这类方法通常是提出一个判断神经元是否重要的度量标准,依据这个标准计算出衡量神经元重要性的值,将不重要的神经元剪掉。在神经网络中可以用于度量的值主要分为3大块:Weight / Activation / Gradient。各种神奇的组合就产出了各种metric玩法。
这里的神经元可以为非结构化剪枝中的单个weight亦或结构化剪枝中的整个filter。
Weight:基于结构化剪枝中比较经典的方法是Pruning Filters for Efficient ConvNets(ICLR2017),基于L1-norm判断filter的重要性。Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration(CVPR2019) 把绝对重要性拉到相对层面,认为与其他filters太相似的filter不重要。
Activation:Network trimming: A data-driven neuron pruning approach towards efficient deep architectures 用activations中0的比例 (Average Percentage of Zeros, APoZ)作为度量标准,An Entropy-based Pruning Method for CNN Compression 则利用信息熵进行剪枝。
Gradient:这类方法通常从Loss出发寻找对损失影响最小的神经元。将目标函数用泰勒展开的方法可以追溯到上世纪90年代初,比如Lecun的Optimal Brain Damage 和 Second order derivatives for network pruning: Optimal Brain Surgeon 。近年来比较有代表性的就是Pruning Convolutional Neural Networks for Resource Efficient(ICLR2017),对activation在0点进行泰勒展开。原作者也很好的向我们展现了如何优雅地进行方法迁移 Importance Estimation for Neural Network Pruning(CVPR2019),换成weight的展开再加个平方。类似的方法还有 Faster gaze prediction with dense networks and Fisher pruning,用Fisher信息来近似Hessian矩阵。SNIP: Single-shot Network Pruning based on Connection Sensitivity(ICLR2019)则直接利用导数对随机初始化的权重进行非结构化剪枝。相关工作同样可以追溯到上世纪80年代末Skeletonization: A Technique for Trimming the Fat from a Network via Relevance Assessment(NIPS1988)。历史总是惊人的相似:
 还有一些考虑实际硬件部署并结合度量标准进行剪枝的方法,对网络层的剪枝顺序进行了选择。Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning(CVPR2017)利用每层的energy consumption来决定剪枝顺序,NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications(ECCV2018)建立了latency的表,利用贪心的方式决定该剪的层。
还有一些考虑实际硬件部署并结合度量标准进行剪枝的方法,对网络层的剪枝顺序进行了选择。Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning(CVPR2017)利用每层的energy consumption来决定剪枝顺序,NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications(ECCV2018)建立了latency的表,利用贪心的方式决定该剪的层。 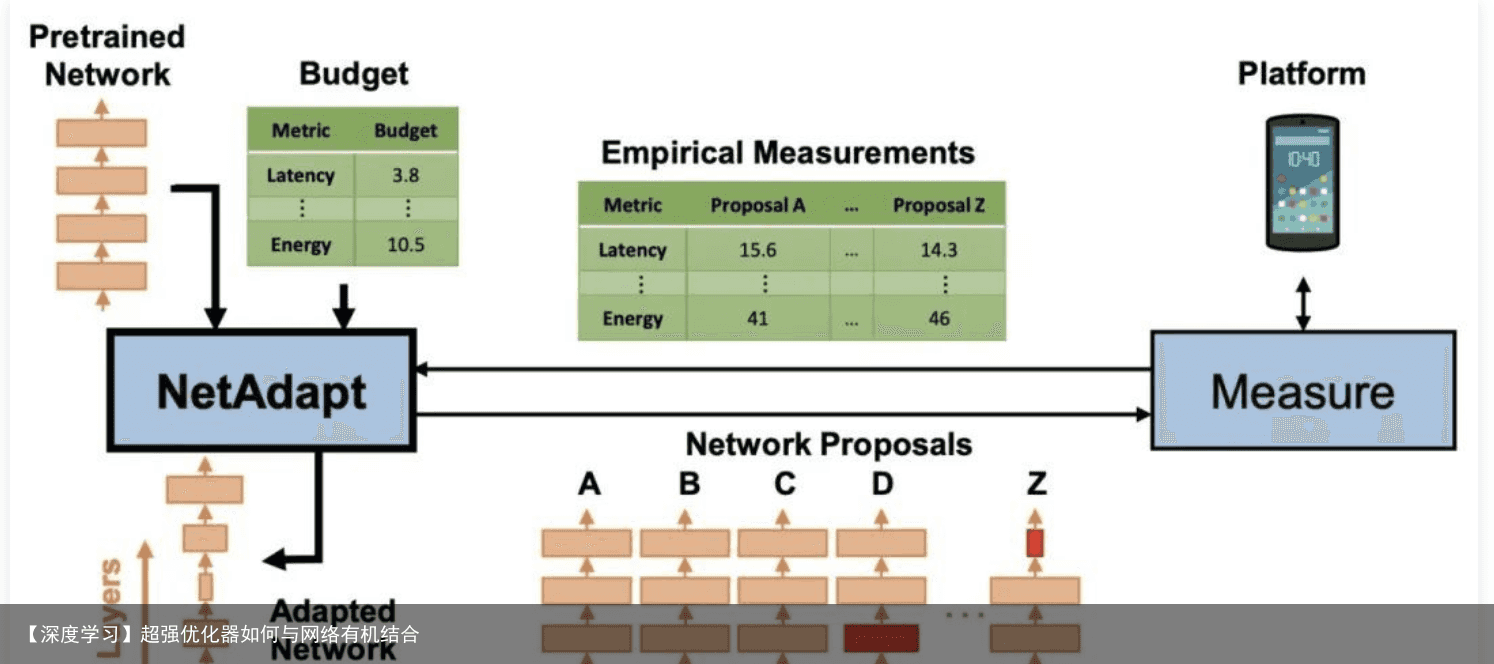
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】超强优化器如何与网络有机结合 https://www.yhzz.com.cn/a/12271.html