【深度学习】基于深度神经网络进行权重剪枝的算法(二)
文章目录 1 摘要 2 介绍 3 OBD 4 一个例子 1 摘要通过从网络中删除不重要的权重,可以有更好的泛化能力、需求更少的训练样本、更少的学习或分类时间。本文的基础思想是使用二阶导数将一个训练好的网络,删除一半甚至一半以上的权重,最终会和原来的网络性能一样好,甚至更好。最好的泛化能力是在训练误差和网络复杂度平衡的时候。
2 介绍达到这种平衡的一种技术是最小化由两部分组成(原始的训练误差+网络复杂度的度量)的损失函数。
复杂度评估方法包括VC维度,描述长度、还有一个历史悠久的方法是:自由参数中的非零参数数量,这个方法也是本文选用的方法。
在很多统计推理的文章中,存在一些先验或者是启发式的信息规定了哪些参数应该被删除;例如,在一组多项式中,应该先删除高次项。但是在神经网络中,应该删除哪些次项的参数就不是那么明显了。
本文的技术是使用目标函数对参数求二阶导数表示参数的贡献度。而不是直观上用数值大小代替贡献度(即数值小的参数对对最终预测结果贡献度也小)
3 OBD目标函数在神经网络领域扮演着重要的角色;因此使用“删除一个参数之后,目标函数的变化”来定义一个参数的贡献度是很合理的。但是计算每一个参数删除引发的目标函数的变化是很困难的。
幸运的是,我们可以通过建立一个误差函数的局部模型,来分析预测扰动参数向量引起的影响。我们用泰勒级数来近似目标函数e。 数向量的扰动δ U将会通过下面的式子来改变目标函数


 结论:
结论: 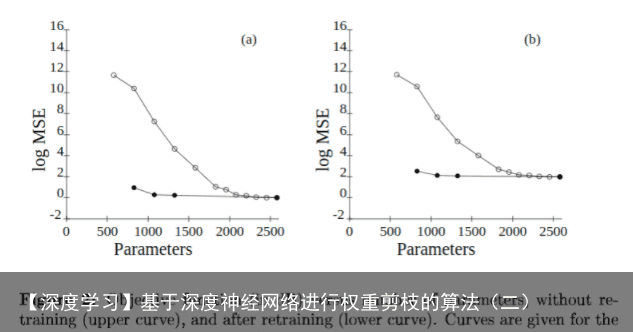
本文使用Optimal Brain Damage方法交互式的每次减少四分之一实际应用中神经网络的参数数量。通过使用OBD自动删除参数,我们得到了两个以上的附加因子:神经网络的速度明显增加,识别精度也轻微的增加。但是本文强调的是在剪枝需要在一个最先进的网络上进行,在一个表现不佳的网络上进行剪枝,达到改善的效果是很容易的。该技术可以改进先进的神经网络具有更加实际的用处。 我们认为这个使用二阶导数的技术仅仅是触及表面的技术。另外,我们也探讨了网络复杂度等同于自由参数的数量这一近似理论,我们使用这个近推导出了一个关于网络内容/复杂度改善的方法,我们使用这个方法去对比在特定任务上不同的网络架构,并与MDL概念进行联系。主要思想是,描述需要少量位元的简单网络比更复杂的网络更有可能正确地进行泛化,因为它可能已经提取了数据的本质并从中删除了冗余。
4 一个例子剪枝和网络结构搜索(Neural Architecture Search, NAS) 剪枝的各种方法里,有一个非常常见的套路是:训练-剪枝-微调三步走  微调这一步隐含了一个假设,就是完整结构的大网络训练出的参数,对最终结果是有贡献的。这种想法,其实和Lottery Hypothesis文章中的思路是有共通之处的,背后的一个思想是:参数和结构是紧密相连的。在Lottery Hypothesis里,通过实验验证了如果winning ticket没有用一开始的那组参数初始化,结果相比起来就会变差。
微调这一步隐含了一个假设,就是完整结构的大网络训练出的参数,对最终结果是有贡献的。这种想法,其实和Lottery Hypothesis文章中的思路是有共通之处的,背后的一个思想是:参数和结构是紧密相连的。在Lottery Hypothesis里,通过实验验证了如果winning ticket没有用一开始的那组参数初始化,结果相比起来就会变差。
模型剪枝(Model Pruning)是一种模型压缩方法,对深度神经网络的稠密连接引入稀疏性,通过将“不重要”的权值直接置零来减少非零权值数量,其历史可追溯到上世纪 90 年代初。
在 Optimal Brain Damage【2】中,使用对角 Hessian 逼近计算每个权值的重要性,重要性低的权值被置零,然后重新训练网络。
在 Optimal Brain Surgeon【3】中,使用逆 Hessian 矩阵计算每个权值的重要性,重要性低的权值被置零,剩下的权值使用二阶泰勒逼近的 loss 增量更新。
最近比较流行基于幅度的权值剪枝方法【4】,该方法将权值取绝对值,与设定的 threshhold 值进行比较,低于门限的权值被置零。基于幅度的权值剪枝算法计算高效,可以应用到大部分模型和数据集。TensorFlow 也使用了基于幅度的权值剪枝算法。
TensorFlow 代码目录 tensorflow/contrib/model_pruning/ 提供了对 TensorFlow 框架的扩展,可在模型训练时实现剪枝。
对每个被选中做剪枝的层增加一个二进制掩模(mask)变量,形状和该层的权值张量形状完全相同。该掩模决定了哪些权值参与前向计算。掩模更新算法则需要为 TensorFlow 训练计算图注入特殊运算符,对当前层权值按绝对值大小排序,对幅度小于一定门限的权值将其对应掩模值设为 0。反向传播梯度也经过掩模,被屏蔽的权值(mask 为 0)在反向传播步骤中无法获得更新量。
研究发现稀疏度不宜从一开始就设置最大,这样容易将重要的权值剪掉造成无法挽回的准确率损失,更好的方法是渐进稀疏度,从初始稀疏度 (一般为 0 )开始,逐步增大到最终稀疏度 ,这期间二进制掩模变量 mask 经历了 n 次更新,每次更新时的门限由当时的稀疏度决定,稀疏度由如下公式计算得到: 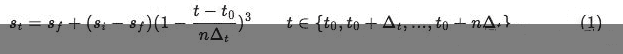 随着训练过程,逐步提高稀疏度,直到达到期望的稀疏度 为止。
随着训练过程,逐步提高稀疏度,直到达到期望的稀疏度 为止。
下图很直观地反映了渐进提高稀疏度的过程。 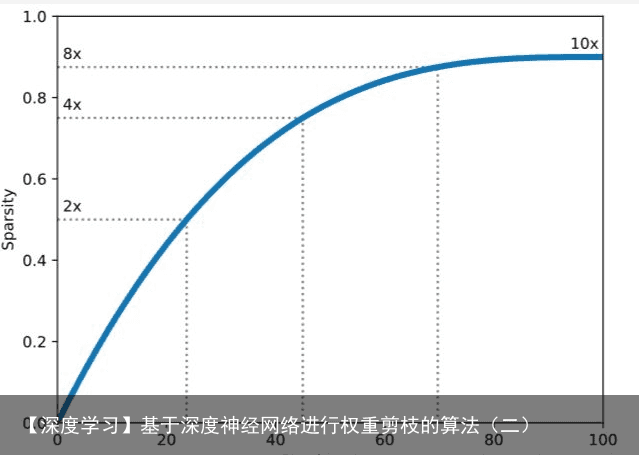 初始时刻,稀疏度提升较快,而越到后面,稀疏度提升速度会逐渐放缓,这个比较符合直觉,因为初始时有大量冗余的权值,而越到后面保留的权值数量越少,不能再“大刀阔斧”地修剪,而需要更谨慎些,避免“误伤无辜”。
初始时刻,稀疏度提升较快,而越到后面,稀疏度提升速度会逐渐放缓,这个比较符合直觉,因为初始时有大量冗余的权值,而越到后面保留的权值数量越少,不能再“大刀阔斧”地修剪,而需要更谨慎些,避免“误伤无辜”。
下面 TensorFlow 代码创建了带有 mask 变量的 graph:
from tensorflow.contrib.model_pruning.python import pruning with tf.variable_scope(conv1) as scope: # 创建权值 variable kernel = _variable_with_weight_decay( weights, shape=[5, 5, 3, 64], stddev=5e-2, wd=0.0) # 创建 conv2d op,权值 variable 增加 mask conv = tf.nn.conv2d( images, pruning.apply_mask(kernel, scope), [1, 1, 1, 1], padding=SAME)下面代码给出了带剪枝的模型训练代码结构:
from tensorflow.contrib.model_pruning.python import pruning # 命令行参数解析 pruning_hparams = pruning.get_pruning_hparams().parse(FLAGS.pruning_hparams) # 创建剪枝对象 pruning_obj = pruning.Pruning(pruning_hparams, global_step=global_step) # 使用剪枝对象向训练图增加更新 mask 的运算符 # 当且仅当训练步骤位于 [begin_pruning_step, end_pruning_step] 之间时, # conditional_mask_update_op 才会更新 mask mask_update_op = pruning_obj.conditional_mask_update_op() # 使用剪枝对象写入 summaries,用于跟踪每层权值 sparsity 变化 pruning_obj.add_pruning_summaries() with tf.train.MonitoredTrainingSession() as mon_sess: while not mon_sess.should_stop(): mon_sess.run(train_op) # 更新 mask mon_sess.run(mask_update_op)其中 FLAGS.pruning_hparams 为一组逗号分隔的键值对,取值如下表所示: 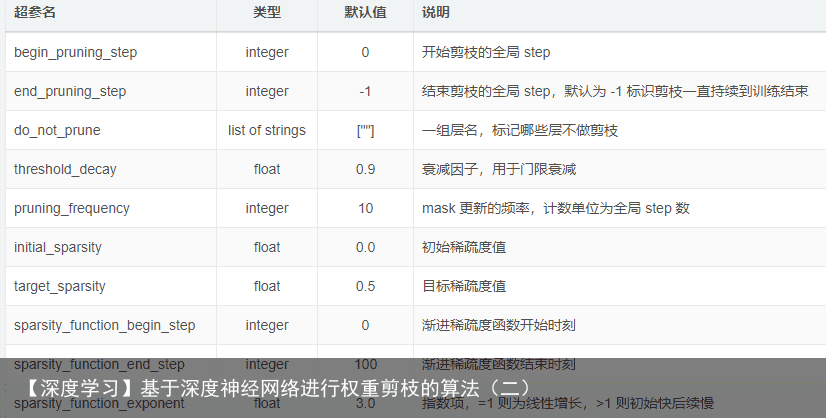 转者注: 详细代码可参照https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/model_pruning/examples/cifar10 (例子)
转者注: 详细代码可参照https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/model_pruning/examples/cifar10 (例子)
实践
TensorFlow model pruning 自带 CIFAR10 例程,实现了一个稀疏 CNN 模型,其中卷积层和 local 层的权值均做了稀疏化。
(1) 准备 TensorFlow r1.7 环境
硬件环境:GTX 1080
软件环境:CUDA 9.0 + cuDNN 7, Bazel 0.11.1
git clone https://github.com/tensorflow/tensorflow.git cd tensorflow/ git checkout r1.7 cd tensorflow/contrib/model_pruning/ bazel build -c opt examples/cifar10:cifar10_{train,val} cd ../../ bazel-bin/contrib/model_pruning/examples/cifar10/cifar10_train -prune_hparams=name=cifar10_pruning,begin_pruning_step=10000,target_sparsity=0.9,sparsity_function_begin_step=10000,sparsity_function_end_step=100000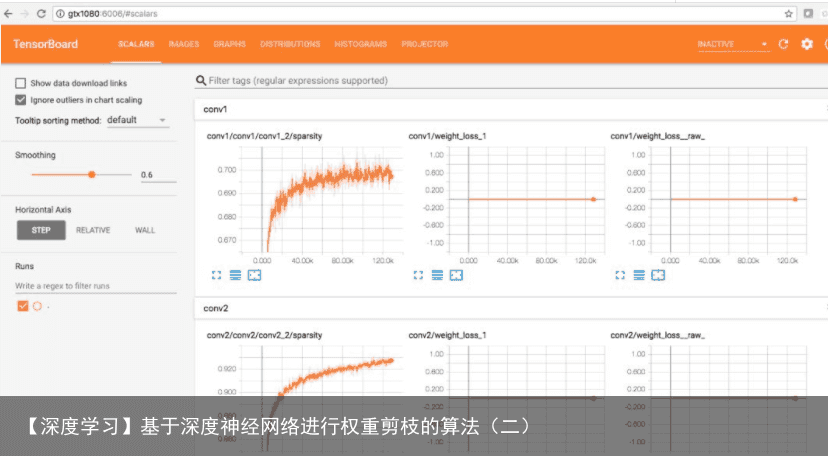 可以看到随着训练步骤增加,conv1 和 conv2 的 sparsity 在不断增长。总的 loss 变化如下图所示:
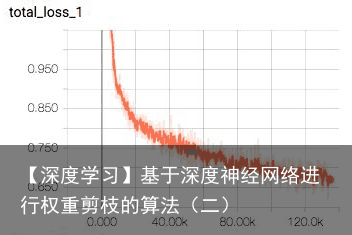
可以看到随着训练步骤增加,conv1 和 conv2 的 sparsity 在不断增长。总的 loss 变化如下图所示:
 (4) 查看计算图
(4) 查看计算图
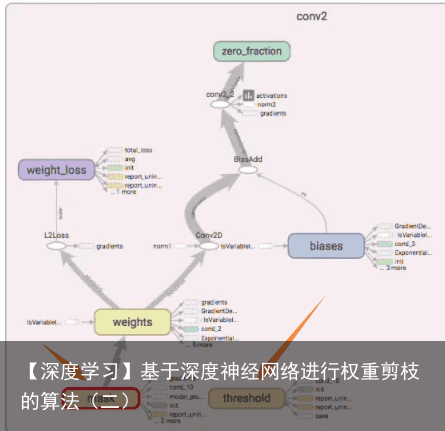
切换到 GRAPHS 页面,双击 conv2 节点,可以看到在原有计算图基础上新增了 mask 和 threshold 节点用来做 model pruning。
 模型评估
模型评估
利用以下命令对训练模型进行评估:
bazel-bin/tensorflow/contrib/model_pruning/examples/cifar10/cifar10_eval 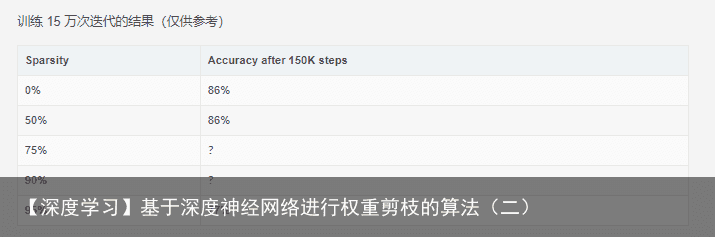 随着稀疏度提高,模型质量逐渐下降,其表现为分类准确率降低。
随着稀疏度提高,模型质量逐渐下降,其表现为分类准确率降低。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】基于深度神经网络进行权重剪枝的算法(二) https://www.yhzz.com.cn/a/12269.html