【深度学习】Pytorch的深度神经网络剪枝应用
文章目录 1 概述 2 pytorch基于卷积层通道剪枝的方法 3 模型剪枝:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017). 4 一份复现的剪枝代码 1 概述网络剪枝个人觉得是一种实用性非常强的网络压缩方法,并且可以和其它模型压缩方法如网络蒸馏、参数位压缩等进行组合,在保留网络识别精度的同时极大幅度的减少网络在使用时的计算量。但是这种简单粗暴实用的方法,虽然在16年就已经提出了,在网上能够找到的资料反而相对较少。根据jacobgil的分析,可能的原因有:1、目前对剪枝的评价方法(决定哪一些参数应该被删除)还不够完善。2、以目前的框架很难实现网络的剪枝。3、各路大神都把这类网络压缩方法作为自己的大招秘而不宣。个人觉得,第2点才是主要原因。。。jacobgil大神采用python2+pytorch实现了对VGG16网络的压缩,不过正因为算法实现较为复杂,所以对于不同的网络结构,还是要对算法做相应调整,不过只要理解了算法修改起来还是很容易的。 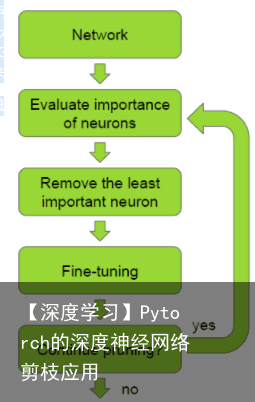 对于一个训练完毕的网络,首先评价各神经元的重要性,把重要性最低神经元移除,之后微调网络,循环上述三个步骤直到网络达到预定目标。所以问题主要在于两个部分,即如何评价各神经元重要性,以及怎么实现移除神经元。
对于一个训练完毕的网络,首先评价各神经元的重要性,把重要性最低神经元移除,之后微调网络,循环上述三个步骤直到网络达到预定目标。所以问题主要在于两个部分,即如何评价各神经元重要性,以及怎么实现移除神经元。
class FilterPrunner主要用于对网络进行剪枝部分的操作。compute_rank函数就是计算网络中各filter的重要性,这之后将重要性低的filter进行记录,最后输出filters_to_prune这个参数作为剪枝的依据。
class PrunningFineTuner_CNN就是整个程序在运行时的主要部分,包含了网络模型的参数配置、训练、测试以及剪枝的调用。在def prune(self)中,我们需要设置每一次循环需要剪枝的数目、最终网络经过剪枝后的filter保留率、每次剪枝之后的fine tune过程的参数等等。我们可以看到调用剪枝过程的核心语句: model = self.model.cpu() for layer_index, filter_index in prune_targets: model = prune_conv_layer(model, layer_index, filter_index) self.model = model.cuda()这里是将目前的模型,需要剪枝的网络层数以及filter的编号这三个参数输入prune.py中的prune_conv_layer函数,输出经过剪枝之后的网络,循环直到目标filter全部被修剪完毕,最后将修剪完成的模型替换原有的模型。
在prune.py中,我们可以看到,这种修剪实际上是通过重新定义一个卷积层,之后替换原有卷积层来实现的,这也是由于当前框架的一些限制所导致的。注意如果网络中存在非卷积的其他和卷积层输入输出相关联的层如nn.BatchNorm2d等,也需要相应跟随卷积层进行调整。而如果在定义网络的时候嵌套了多个sequence结构,那还得修改main中的部分代码以使得能够定位到子sequence中的卷积层才行。 我个人还是建议大家基于jacobgil的源码,针对自己想要剪枝的神经网络,进行相应的修改,来加深对这种方法的理解。我进行实验时,建立的CNN结构如下: 而各代的正确率和与原始网络大小的关系如下图所示,图中横坐标表示剪枝数目占原始网络的百分比,纵坐标: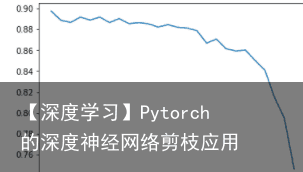 而从图中可以看出,随着网络剪枝数目的增加,网络的准确率逐步下降,并且下降的越来越快。。。我觉得可能有两个方面的原因:首先是网络本身的容量不足,其次则是固定剪枝数目而导致对最后几代网络造成了不可逆的影响。
而从图中可以看出,随着网络剪枝数目的增加,网络的准确率逐步下降,并且下降的越来越快。。。我觉得可能有两个方面的原因:首先是网络本身的容量不足,其次则是固定剪枝数目而导致对最后几代网络造成了不可逆的影响。
对比发现,剪枝所得模型在测试集上的正确率达到了87.07%,而相同模型从头开始训练的话,最终得到的分类正确率为87.05%。两者差别并不大。。。一方面可能是因为网络比较简单,收敛到一个比较好的参数难度不大,但同时也说明此算法还有非常大的优化空间,比如优化剪枝的选择方式(个人觉得可以考虑结合知识蒸馏的某些思想),结合人类的经验对不同层给予不同的剪枝权重等,对于DenseNet这种结构也可以对不同的卷积层进行剪枝,以减少卷积层的冗余等等。
2 pytorch基于卷积层通道剪枝的方法本文基于文章:Pruning Convolutional Neural Networks for Resource Efficient Inference
https://arxiv.org/abs/1611.06440 下面以ResNet模型为例,讲解剪枝方法。
1 评估神经元(即通道)重要性
1.1 给模型中所有conv layer重新编号排次序;
1.2 计算每个conv layer所有通道rank值,并按通道归一化;
1.3 统计模型所有conv layer的通道数;
1.4 根据设置拟剪枝数量num(默认512),对所有convlayer通道rank值按从大到小排序,即确定rank值最小的num个通道,记录并返回它们的卷积层号和通道编号。
2 去除不重要神经元
2.1 根据拟剪枝列表(即卷积层号和通道编号),在训练好或加载的模型中去除;
2.2 如何去除,即把conv layer中按2.1中的列表,去除通道a,使a的前后通道相连,使第一卷积层输出通道数与第二层输入通道数相同,最后一个卷积层输出需与第一个全连层 输入通道数相同,这里全连层不计算rank值,拟剪枝的卷积层,需要conv继承操作;
注意:残差块中需要处理公式(1)F(X)=f(x)+x中f(x)与x不同维数情况;即在convlayer通道数改变后,添加residual = out即可。这个修改虽与公式(1)本意有些出入,但通过实验发现,在模型大小减少一半的情况下,仍可以较好地与原模型精度差在1%以内;2.3 BatchNorm层通道数修改
当所有卷积层剪枝结束,依据邻近上一个卷积层输出通道数,通过BatchNorm层继承方式,它需修改成同样的通道数即可;3 剪枝模型训练
全网参数更新,也可设置微调特定层参数更新4 判断剪枝是否结束,若停止到下一步微调全网参数,否则重复1—3步骤;
5微调模型
使用与训练同一个数据库,也可用另外数据库,一般来说学习率要小于训练的1到2个数量级,微调结束后保存剪枝模型。6 问题与讨论
6.1 具体模型需定制剪枝,需依照其模型生成文件,也包括forward函数,这要在计算Loss时使用;
6.2 测试阶段
需保证剪枝模型可forward操作,设置好Variable参数,即volatile=True,以免GPU资源泄露;具体代码参见:https://github.com/eeric/channel_prune
2019.10.15日添加:从实践来看,模型剪枝算法存在自身缺陷,想要获得模型小速度快,精度有提高的办法是使用知识蒸馏训练。
3 模型剪枝:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017).论文参考:Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017).
导读:这篇文章是一篇关于CNN网络剪枝的文章,文章里面提出通过BatchNorm层的 scaling参数确定重要的channel,排除不重要的channel,从而达到网络瘦身的目的。 此外文章还引入了L1范数,通过L1范数约束的稀疏特性使得BN的scaling参数趋于0, 从而帮助确定非重要的channel,并按照给定的阈值剪裁掉。文章中对于剪裁的流程可以归纳为下图1所示,通过BN的scaling参数确定非重要的channel并剪裁掉,之后再根据需要是否再进行迭代剪裁。 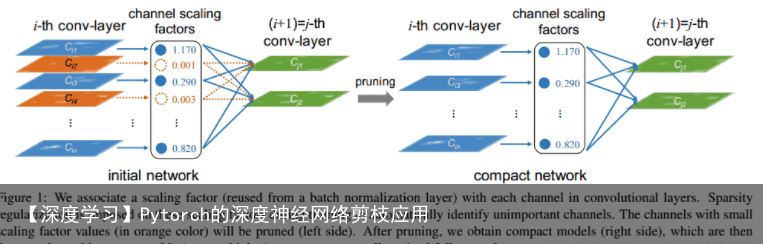 剪裁方法 文章中将正则化引入到网络的损失函数中,其总的定义如下:
剪裁方法 文章中将正则化引入到网络的损失函数中,其总的定义如下:  这里引入scaling参数有如下需要注意的事项:
这里引入scaling参数有如下需要注意的事项:
1)scaling参数是加载BN层上的,若是对于没有BN的CNN网络来说加入scaling会增加卷积的权值参数,带来不了稀疏的结构; 2)在BN层的前面添加scaling参数会被BN给补偿回来; 3)加在BN层的后面就相当于是两个Scaling参数进行运算了,也是达到不了稀疏的目的的; 这篇文章的剪裁方法是迭代进行的,其剪裁的流程图见下图所示: 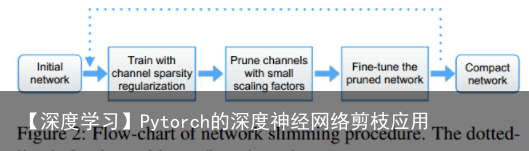 3.裁剪后的网络参数情况
3.裁剪后的网络参数情况 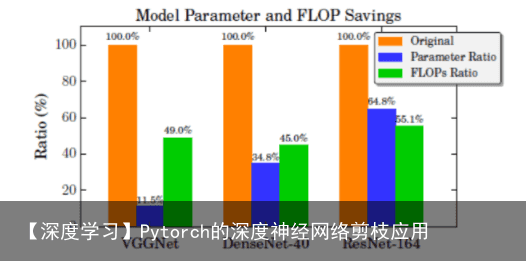 基于论文的代码复现以及拓展: 基于Learning Efficient Convolutional Networks Through Network Slimming论文。实现的代码及其拓展的github地址为:https://github.com/Culturenotes/Network-Slimming。
基于论文的代码复现以及拓展: 基于Learning Efficient Convolutional Networks Through Network Slimming论文。实现的代码及其拓展的github地址为:https://github.com/Culturenotes/Network-Slimming。
目前加入了Resnet和Densenet的网络模型剪枝的实现,后续将会添加EfficientNet、MobileNet、Xception、shuffleNet的模型剪枝实现。如果感兴趣可以和我一起改进并且实现他们。 在网络上中加入其它优化方法 最强深度学习优化器Ranger Ranger=RAdam+LookAhead。强强结合,性能更优速度更快!
RAdam可以说是优化者在培训开始时建立的最佳基础。RAdam利用动态整流器根据方差调整Adam的自适应动量,并有效地提供自动预热,根据当前数据集定制,以确保扎实的训练开始。
LookAhead受到深度神经网络损失表面理解的最新进展的启发,并在整个训练期间提供了稳健和稳定探索的突破。“减少了对广泛超参数调整的需求”,同时实现“以最小的计算开销实现不同深度学习任务的更快收敛”。
因此,两者都在深度学习优化的不同方面提供了突破,并且这种组合具有高度协同性,可能为您的深度学习结果提供最佳的两种改进。因此,对更加稳定和强大的优化方法的追求仍在继续,通过结合两项最新突破(RAdam + LookAhead),Ranger的整合有望为深度学习提供又一步。
warm up与consine learning rate warm up最早来自于这篇文章: https://arxiv.org/pdf/1706.02677.pdf 根据这篇论文所描述的,我们一般只在前5个epoch使用warm up。
consine learning rate来自于这篇文章:https://arxiv.org/pdf/1812.01187.pdf 通常情况下,把warm up和consine learning rate一起使用会达到更好的效果。 1、 理性分析 因为模型的weights是随机初始化的,可以理解为训练之初模型对数据的“理解程度”为0(即:没有任何先验知识),在第一个epoches中,每个batch的数据对模型来说都是新的,模型会根据输入的数据进行快速调参,此时如果采用较大的学习率的话,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”; 当模型训练一段时间之后(如:10epoches或10000steps),模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛; 当模型使用较大的学习率训练一段时间之后,模型的分布相对比较稳定,此时不宜从数据中再学到新特点,如果仍使用较大的学习率会破坏模型的稳定性,而使用小学习率更容易获取local optima。 2 、感性分析 刚开始模型对数据完全不了解,这个时候步子太大,容易扯着dan,此时需要使用小学习率摸着石头过河; 对数据了解了一段时间之后,可以使用大学习率朝着目标大步向前; 快接近目标时,使用小学习率进行探索,此时步子太大,容易错过最近点
代码实现**:
# MultiStepLR without warm up scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=args.milestones, gamma=0.1) # warm_up_with_multistep_lr warm_up_with_multistep_lr = lambda epoch: epoch / args.warm_up_epochs if epoch <= args.warm_up_epochs else 0.1**len([m for m in args.milestones if m <= epoch]) scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=warm_up_with_multistep_lr) # warm_up_with_cosine_lr warm_up_with_cosine_lr = lambda epoch: epoch / args.warm_up_epochs if epoch <= args.warm_up_epochs else 0.5 * ( math.cos((epoch – args.warm_up_epochs) /(args.epochs – args.warm_up_epochs) * math.pi) + 1) scheduler = torch.optim.lr_scheduler.LambdaLR( optimizer, lr_lambda=warm_up_with_cosine_lr)上面的三段代码分别是不使用warm up+multistep learning rate 衰减、使用warm up+multistep learning rate 衰减、使用warm up+consine learning rate衰减。代码均使用pytorch中的lr_scheduler.LambdaLR自定义学习率衰减器。
4 一份复现的剪枝代码工程地址:https://github.com/BBuf/model-compression  下次就分析这个啦。
下次就分析这个啦。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】Pytorch的深度神经网络剪枝应用 https://www.yhzz.com.cn/a/12259.html