【深度学习】Swin-Transformer和EfficientNet对比分析
文章目录 1 概述 2 算法解析 2.1 Speed 2.2 EfficientNet v2算法详解 2.3 渐进学习 3 EfficientUNet 4 总结 1 概述就在几天前Swin Transformers刚刚为Transformer阵营夺下ImageNet的Top-1准确率(86.4%)不久,以Quoc V.Le为首的CNN阵营又通过大杀器AutoML又再次抢占了这个阵地(87.3%),而拿下这个Top-1的模型便是我们这里要介绍的EfficientNet v2 [1]。
那么EfficientNet v2是如何做到的呢?对比其他AutoML方法,EfficientNet v2深入探索了输入图像尺寸和模型的正则尺度的关系,并提出了递增式的AutoML方法。即通过逐渐增加输入图像的尺寸并不断调整与之匹配的模型的正则尺度来进行网络的构建。
EfficientNet v2的另外一个贡献是把训练速度作为了优化目标之一。通过对近年CNN的若干算法的总结,作者发现了影响训练速度的几个重要原因,并以这些原因作为出发点,对模型的搜索空间做了约束。
2 算法解析2.1 Speed
在训练一个网络时,作者发现了几个影响训练速度的因素,它们分别是:
使用大的图像作为输入会使训练变慢; 在网络的更浅的层中,深度卷积会比普通卷积要慢; 像EfficientNet v1中使用相同的尺度对模型的每个阶段进行缩放并不是最优选择。 第一个因素比较容易理解。在我们的训练环境(显存容量)固定时,大的训练图像意味着只能使用更小的batchsize,因此训练速度会变慢。
第二个因素是和我们的之前对于深度可分离卷积的认知相冲突的一个观点。在我们的认知中,深度卷积一直是比普通卷积速度要快,参数量要少的一个操作。出现这个冲突的原因在于现在的一些加速设备或者移动设备在普通卷积上拥有更好的优化,因此在某些条件像会达到比深度卷积更快的计算速度。那么究竟是硬件的提速更重要还是算法设计的提速更重要呢,这就需要我们通过实验结果来验证了。在这篇论文中,作者对比了在EfficientNet的不同阶段将MBConv替换为Fused-MBConv的速度对比(表1),发现将stage 1-3的MBConv替换为Fused-MBConv将提高预测速度和准确率。
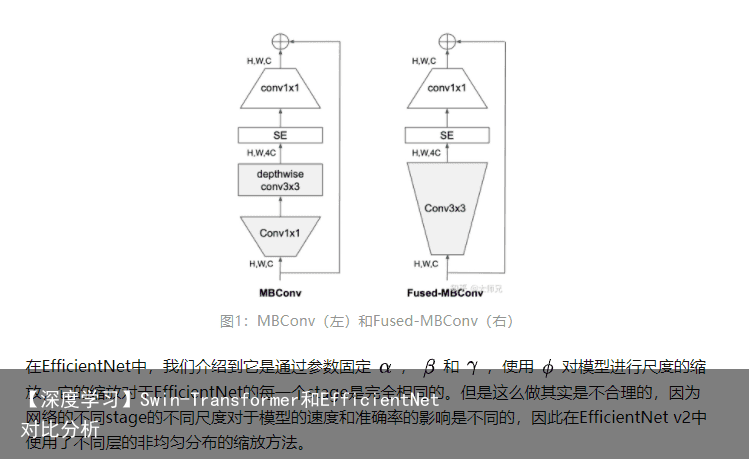
2.2 EfficientNet v2算法详解
EfficientNet v2的算法包括两个核心方面:
使用新的搜索空间和奖励函数搜索一个新的模型架构; 使用渐进学习(Progressively Learning)动态的调整正则尺度和输入图像尺寸的关系来对网络进行训练。

2.3 渐进学习
在上面我们介绍过模型的正则化尺度和输入图像的分辨率有近乎正比的关系,因此当我们在调整一个网络的输入图像的尺寸时,我们需要对应的调整网络的正则内容才能更大幅发挥网络的性能。这就是EfficientNet v2中提出的渐进学习(Porgressive Learning)。
EfficientNet v2的渐进学习分成两步:
在训练的早期,使用更小尺寸的输入图像和更弱的正则; 然后逐渐增大输入图像的分辨率和网络以及使用更强的正则。 在EfficientNet v2中使用的正则类型有三类,它们是: 
EfficientNet(B0-B7)参数 还是先给出EfficientNetB0的网络结构,方便后面理解。
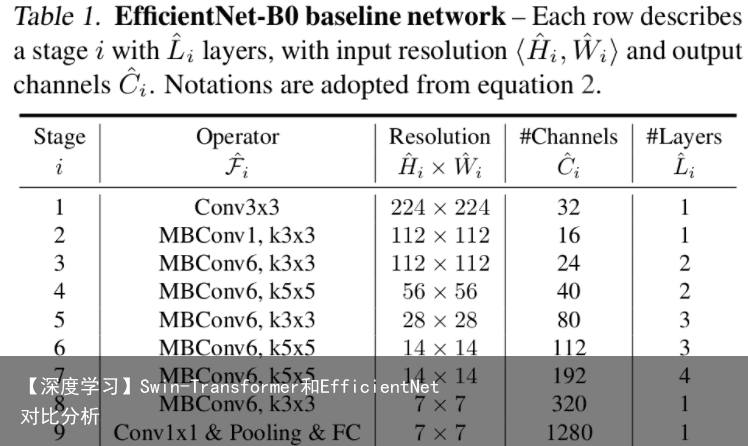 通过上面的内容,我们是可以搭建出EfficientNetB0网络的,其他版本的详细参数可见下表:
通过上面的内容,我们是可以搭建出EfficientNetB0网络的,其他版本的详细参数可见下表:
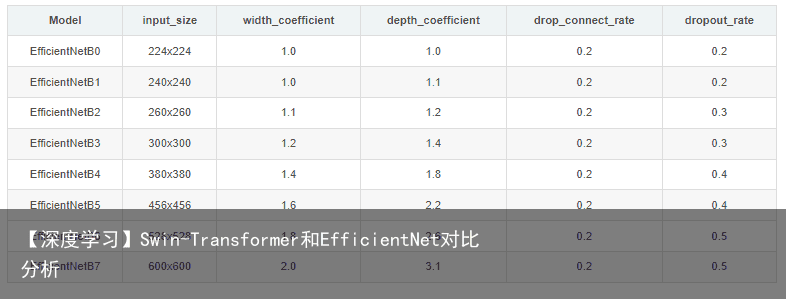
input_size代表训练网络时输入网络的图像大小 width_coefficient代表channel维度上的倍率因子 depth_coefficient代表depth维度上的倍率因子 drop_connect_rate是在MBConv结构中dropout层使用的drop_rate dropout_rate是最后一个全连接层前的dropout层(在stage9的Pooling与FC之间)的dropout_rate。
4 总结2021年伊始,Vision Transformers和CNN阵营的竞争好像达到了一个白热化的阶段,随之而来的便是ImageNet Top-1准确率的不断刷新。本文介绍的EfficientNet v2更多的价值在于提出了图像尺寸和正则尺度的关系,整个渐进学习的过程是一个过拟合难度从易到难的迭代式开发,这种多图像尺度加正则尺度无疑讲大幅提高模型的泛化能力。
EfficientNetV2对所提方法的迁移学习能力进行了对比。可以看到:相比其他卷积网络与Transformer方案,本文所提方法的泛化性能更加。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】Swin-Transformer和EfficientNet对比分析 https://www.yhzz.com.cn/a/12247.html