【深度学习】医学图像分割的集成与后处理
文章目录 1 如何通过组合多个神经网络提高模型性能 1.1 使用融合模型减少模型的方差 2 tensorflow keras 实现模型平均 2.1 训练多种模型 2.2 融合模型 3 神经网络训练之交叉验证 4 训练和后处理 5 介绍一些免费/开源的医学影像后处理工具
深度神经网络是非线性的。它们提供了更大的灵活性,并且理论上随着数据集的增多,其性能表现会越好。其缺点是通过随机训练算法进行学习,这意味着神经网络对训练数据很敏感,并且每次训练时会得到不同的权重向量,从而产生不同的预测。通常,这被称为具有高方差的神经网络,当使用其模型进行预测时,可能效果并不好。
减少神经网络模型方差的成功方法是融合多个模型而不是单个模型,并结合这些模型的预测结果综合判断,这样的模型称为融合模型(Aggregation Model),这种算法称为集成学习(Ensemble Learning)。融合模型不仅可以减少预测的方差,而且可以产生比任何单个模型都更好的预测
1.1 使用融合模型减少模型的方差
训练深度神经网络可能在计算上非常昂贵。在包含数百万个样本的数据集上训练非常深的网络可能需要花费数天,甚至数月的时间。
训练许多不同的候选网络,然后选择最佳的网络,并丢弃其余的网络。这种方法有两个缺点。
浪费在训练其余网络上的所有精力。 在验证集上表现最佳的网络可能不是在新测试数据上表现最佳的网络。 神经网络模型是一种非线性方法,可以学习数据中的复杂非线性关系。但是,这种学习算法具有很大的随机性,可以将神经网络视为一种具有低偏差和高方差的学习方法。
解决神经网络高方差的一种方案是训练多个模型并融合它们的预测,之前的集成学习文章中提到过。一个好的模型,意味着它的预测要好于随机预测的结果。重要的是,这些模型必须以不同的方式保持良好,并且产生不同的预测误差。这正是融合模型性能表现好的原因。
融合来自多个神经网络的预测会增加一个偏差,该偏差又会抵消单个训练后的神经网络模型的变化。融合模型的预测结果相对于拥有相同训练数据集,模型配置的单个神经网络模型来说,其预测对数据的敏感性很低,因为减少的训练房差,所以可以表现得更好。除了减少预测中的方差之外,集成模型可以比任何单个最佳模型产生更好的预测。
集成学习是融合模型充分利用针对同一问题准备的多个模型的预测的方法。通常,集成学习涉及在同一数据集上训练多个网络,然后使用每种训练后的模型进行预测,然后再以某种方式组合预测以得出最终结果或预测。实际上,融合模型是应用机器学习中的一种标准方法,可确保做出最稳定,最好的预测。
例如,Alex Krizhevsky 在2012年的论文《深度卷积神经网络Imagenet分类》中,介绍了用于照片分类的深度卷积神经网络AlexNet,它使用了多个表现良好的CNN模型的模型平均,来获得最好的结果。将一个模型的性能与在两个,五个和七个不同模型上平均的总体预测进行比较。
2 tensorflow keras 实现模型平均在Keras中开发模型平均合奏的最简单方法是在同一数据集上训练多个模型,然后组合来自每个训练模型的预测。
2.1 训练多种模型
训练多个模型可能会占用大量资源,具体取决于模型的大小和训练数据的大小。
集成所需的模型数量可能会根据问题和模型的复杂性而有所不同。这种方法的好处是可以继续创建模型,将其添加到集合中,并通过对保持测试集进行预测来评估它们对性能的影响。
小型模型可以全部同时加载到内存中,而超大型模型可能必须一次加载一个模型才能进行预测,然后再组合预测。
from tensorflow.keras.models import load_model … n_members = 10 models = list() for i in range(n_members): # load model filename = model_ + str(i + 1) + .h5 model = load_model(filename) # store in memory models.append(model) …2.2 融合模型
对于回归问题,可以对预测计算平均值。
… # make predictions yhats = [model.predict(testX) for model in models] yhats = array(yhats) # calculate average outcomes = mean(yhats)对于分类问题,有两种选择。
一种是计算预测的整数类别出现次数。
… from scipy.stats import mode # make predictions yhats = [model.predict_classes(testX) for model in models] yhats = array(yhats) # calculate mode outcomes, _ = scipy.stats.mode(yhats)这种方法的缺点是,对于较小的融合和兴或具有大量类别的数据集,预测结果可能不准确。
在二分类问题中,输出层上使用了S形激活函数,可以像回归问题一样计算预测概率的平均值。在具有两个以上类别的多类别分类问题的情况下,在输出层上使用softmax激活函数,可以在采用argmax获得类别值之前计算每个预测类别的概率之和。
… # make predictions yhats = [model.predict(testX) for model in models] yhats = array(yhats) # sum across ensembles summed = numpy.sum(yhats, axis=0) # argmax across classes outcomes = argmax(summed, axis=1) 3 神经网络训练之交叉验证10折交叉验证
10折交叉验证是把样本数据分成10份,轮流将其中9份做训练数据,将剩下的1份当测试数据,10次结果的均值作
为对算法精度的估计,通常情况下为了提高精度,还需要做多次10折交叉验证。更进一步,还有K折交叉验证,10
折交叉验证是它的特殊情况。K折交叉验证就是把样本分为K份,其中K-1份用来做训练建立模型,留剩下的一份来
验证,交叉验证重复K次,每个子样本验证一次。
4 训练和后处理在训练过程中,为3D_UNet在平面内使用空间增强的手段(例如缩放和旋转),仅仅是为了消除不同的切片进行重采样以后造成的插值伪影。 对于每个UNet配置都使用五折交叉验证,我们分别进行推理,以确保病例被合适地分层(因为每个病例有两张图片)。幸亏有交叉验证这种手段,让nnUNet可以在整个数据集上进行验证和结合。最后,着五个交叉验证被合在一起。nnUNet通过计算所有病例所有分割出来地前景地平均dice,得出一个标量值,从而来衡量模型的表现。详细的信息在这里不做赘述(附录F里有提到)。根据这个评估的方法,2D_UNet的得分是0.9165,3D_full_resolution的得分是0.9181,结合推理的得分是0.9228。因此,结合推理的方法将会用来进行预测测试集的效果。 后处理在结合推理中进行了配置,去小分支算法对于分割右心房和左心腔十分有用。 确定最好的 UNet 配置 当模型训练完成之后,使用下面的链接自动选择合适的 UNet 配置。
nnUNet_find_best_configuration -m 2d 3d_fullres 3d_lowres 3d_cascade_fullres -t XXX –strict注意:五折交叉验证需要全部训练完成。同理 XXX 代表你的任务序号,–strict 参数代表即使配置不存在仍继续执行。
5 介绍一些免费/开源的医学影像后处理工具ITK Snap  ITK Snap (http://itksnap.org) 是跨平台的免费开源软件。支持iOS,WIN和Linux。其界面走技术硬核风,如下图:
ITK Snap (http://itksnap.org) 是跨平台的免费开源软件。支持iOS,WIN和Linux。其界面走技术硬核风,如下图:
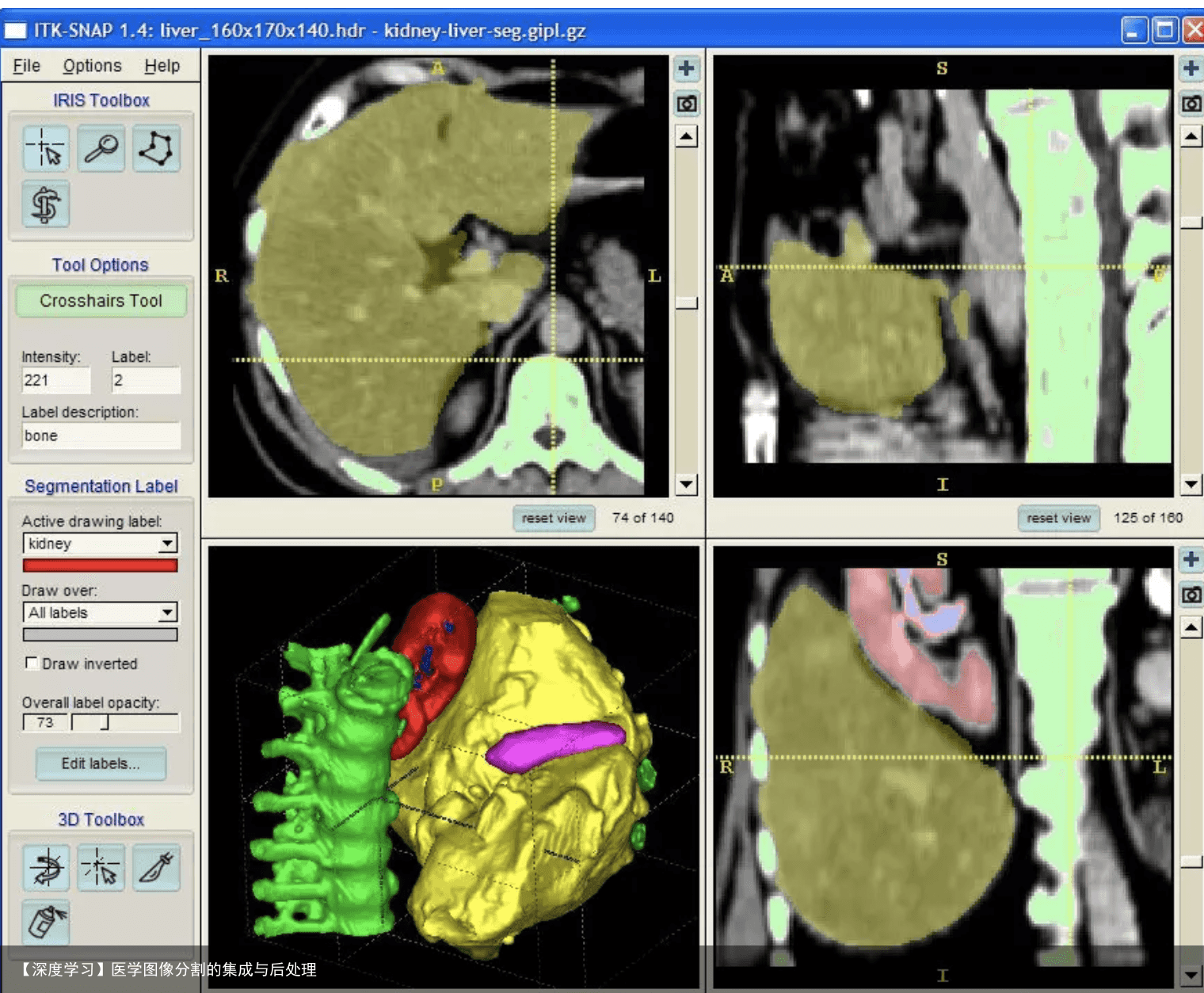 手动分割工具齐全而且实现了大量的ITK半自动方法,而且软件架构比较开放,很方便往里塞ITK写的新方法,比较适合做分割算法开发的工程师们用来调参数或者尝试新算法。对于医学背景的同学们,我更推荐下面这个软件:
手动分割工具齐全而且实现了大量的ITK半自动方法,而且软件架构比较开放,很方便往里塞ITK写的新方法,比较适合做分割算法开发的工程师们用来调参数或者尝试新算法。对于医学背景的同学们,我更推荐下面这个软件:
Seg3D
Seg3D (http://www.sci.utah.edu/download/seg3d/)是一款交互设计非常独树一帜的免费开源影像处理软件。考虑到它的开发单位犹他大学与Photoshop的渊源,Seg3D基于“蒙版”和“图层”的使用也并不意外。每一步分割算法都是生成一个新的“蒙版”,蒙版之间也可以便捷的逻辑运算。不过Seg3D里的半自动方法比较有限,只有区域生长,阈值之类的几种。软件比较封闭,想要二次开发加入新的方法也不是那么容易。下图是一个CT增强的颅内血管分割的小例子 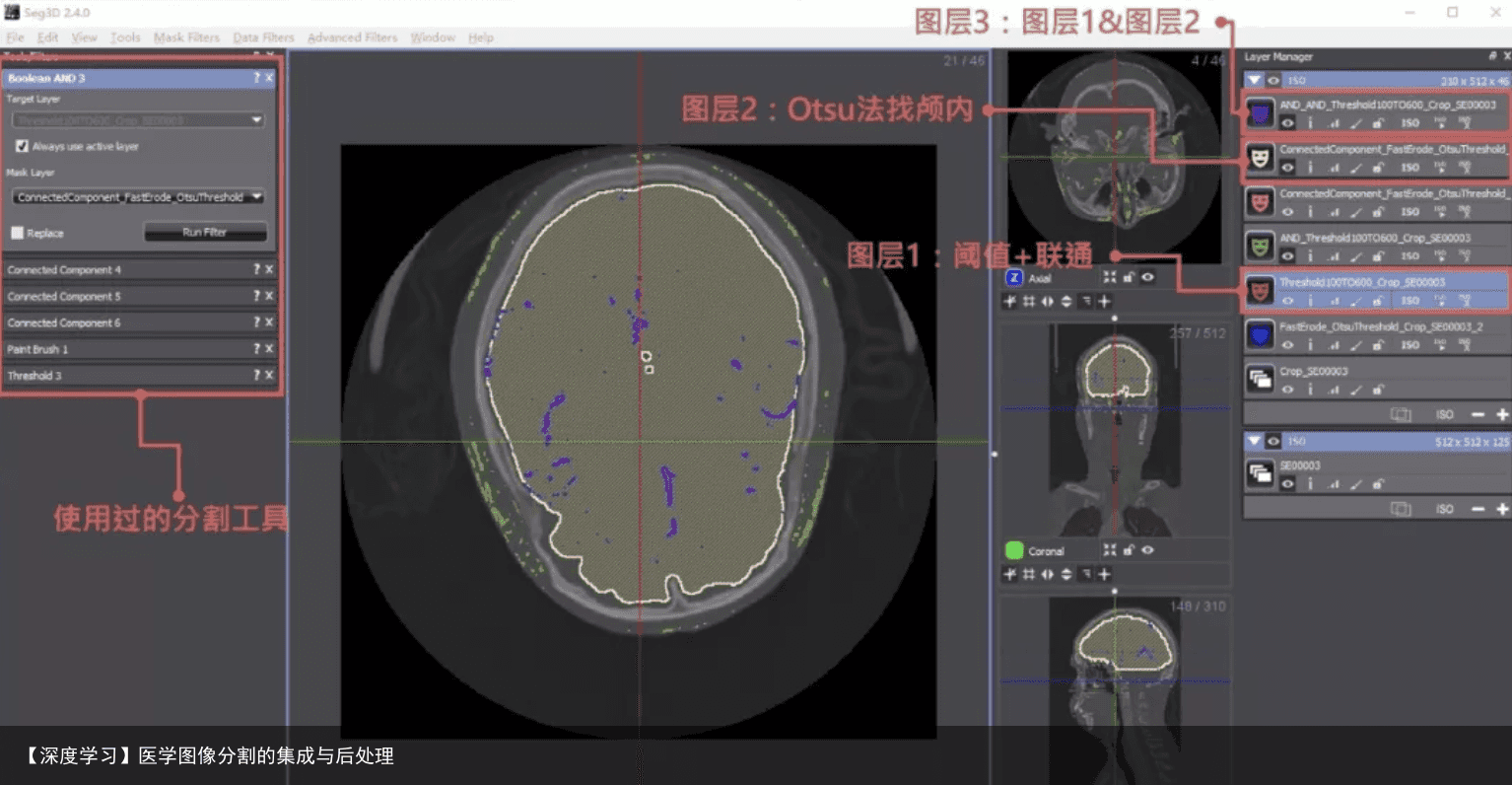
结合手动方法,愿意花时间的话,应该说可以满足绝大多数医学影像分割需求了。还可以把分割好的模型直接3D打印。
免责声明:文章内容来自互联网,本站不对其真实性负责,也不承担任何法律责任,如有侵权等情况,请与本站联系删除。
转载请注明出处:【深度学习】医学图像分割的集成与后处理 https://www.yhzz.com.cn/a/12233.html